 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Domain-Generalized Open-Vocabulary Object Detection: A Progressive Domain-invariant Cross-modal Alignment Method
Mar 29, 2026Open-Vocabulary Object Detection (OVOD) has achieved remarkable success in generalizing to novel categories. However, this success often rests on the implicit assumption of domain stationarity. In this work, we provide a principled revisit of the OVOD paradigm, uncovering a fundamental vulnerability: the fragile coupling between visual manifolds and textual embeddings when distribution shifts occur. We first systematically formalize Domain-Generalized Open-Vocabulary Object Detection (DG-OVOD). Through empirical analysis, we demonstrate that visual shifts do not merely add noise; they cause a collapse of the latent cross-modal space where novel category visual signals detach from their semantic anchors. Motivated by these insights, we propose Progressive Domain-invariant Cross-modal Alignment (PICA). PICA departs from uniform training by introducing a multi-level ambiguity and signal strength curriculum. It builds adaptive pseudo-word prototypes, refined via sample confidence and visual consistency, to enforce invariant cross-domain modality alignment. Our findings suggest that OVOD's robustness to domain shifts is intrinsically linked to the stability of the latent cross-modal alignment space. Our work provides both a challenging benchmark and a new perspective on building truly generalizable open-vocabulary systems that extend beyond static laboratory conditions.
Boosting Single-domain Generalized Object Detection via Vision-Language Knowledge Interaction
Apr 27, 2025
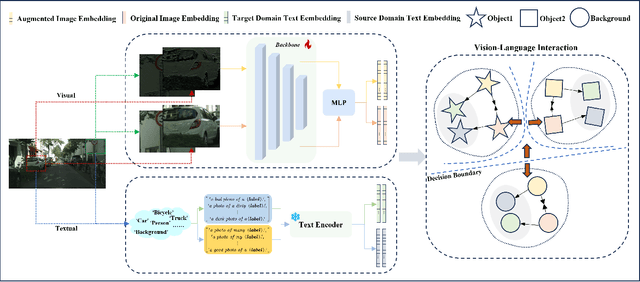


Single-Domain Generalized Object Detection~(S-DGOD) aims to train an object detector on a single source domain while generalizing well to diverse unseen target domains, making it suitable for multimedia applications that involve various domain shifts, such as intelligent video surveillance and VR/AR technologies. With the success of large-scale Vision-Language Models, recent S-DGOD approaches exploit pre-trained vision-language knowledge to guide invariant feature learning across visual domains. However, the utilized knowledge remains at a coarse-grained level~(e.g., the textual description of adverse weather paired with the image) and serves as an implicit regularization for guidance, struggling to learn accurate region- and object-level features in varying domains. In this work, we propose a new cross-modal feature learning method, which can capture generalized and discriminative regional features for S-DGOD tasks. The core of our method is the mechanism of Cross-modal and Region-aware Feature Interaction, which simultaneously learns both inter-modal and intra-modal regional invariance through dynamic interactions between fine-grained textual and visual features. Moreover, we design a simple but effective strategy called Cross-domain Proposal Refining and Mixing, which aligns the position of region proposals across multiple domains and diversifies them, enhancing the localization ability of detectors in unseen scenarios. Our method achieves new state-of-the-art results on S-DGOD benchmark datasets, with improvements of +8.8\%~mPC on Cityscapes-C and +7.9\%~mPC on DWD over baselines, demonstrating its efficacy.
PhysAug: A Physical-guided and Frequency-based Data Augmentation for Single-Domain Generalized Object Detection
Dec 16, 2024



Single-Domain Generalized Object Detection~(S-DGOD) aims to train on a single source domain for robust performance across a variety of unseen target domains by taking advantage of an object detector. Existing S-DGOD approaches often rely on data augmentation strategies, including a composition of visual transformations, to enhance the detector's generalization ability. However, the absence of real-world prior knowledge hinders data augmentation from contributing to the diversity of training data distributions. To address this issue, we propose PhysAug, a novel physical model-based non-ideal imaging condition data augmentation method, to enhance the adaptability of the S-DGOD tasks. Drawing upon the principles of atmospheric optics, we develop a universal perturbation model that serves as the foundation for our proposed PhysAug. Given that visual perturbations typically arise from the interaction of light with atmospheric particles, the image frequency spectrum is harnessed to simulate real-world variations during training. This approach fosters the detector to learn domain-invariant representations, thereby enhancing its ability to generalize across various settings. Without altering the network architecture or loss function, our approach significantly outperforms the state-of-the-art across various S-DGOD datasets. In particular, it achieves a substantial improvement of $7.3\%$ and $7.2\%$ over the baseline on DWD and Cityscape-C, highlighting its enhanced generalizability in real-world settings.
Object Gaussian for Monocular 6D Pose Estimation from Sparse Views
Sep 04, 2024



Monocular object pose estimation, as a pivotal task in computer vision and robotics, heavily depends on accurate 2D-3D correspondences, which often demand costly CAD models that may not be readily available. Object 3D reconstruction methods offer an alternative, among which recent advancements in 3D Gaussian Splatting (3DGS) afford a compelling potential. Yet its performance still suffers and tends to overfit with fewer input views. Embracing this challenge, we introduce SGPose, a novel framework for sparse view object pose estimation using Gaussian-based methods. Given as few as ten views, SGPose generates a geometric-aware representation by starting with a random cuboid initialization, eschewing reliance on Structure-from-Motion (SfM) pipeline-derived geometry as required by traditional 3DGS methods. SGPose removes the dependence on CAD models by regressing dense 2D-3D correspondences between images and the reconstructed model from sparse input and random initialization, while the geometric-consistent depth supervision and online synthetic view warping are key to the success. Experiments on typical benchmarks, especially on the Occlusion LM-O dataset, demonstrate that SGPose outperforms existing methods even under sparse view constraints, under-scoring its potential in real-world applications.