 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Single-domain Generalized Object Detection via Vision-Language Knowledge Interaction
Apr 27, 2025
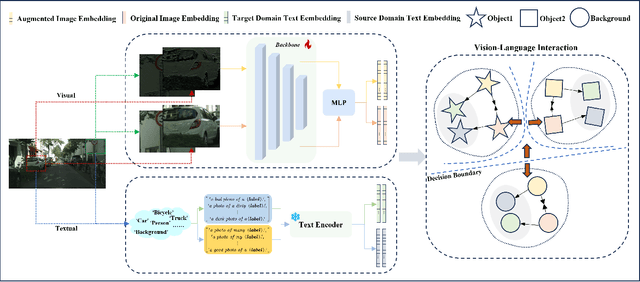


Single-Domain Generalized Object Detection~(S-DGOD) aims to train an object detector on a single source domain while generalizing well to diverse unseen target domains, making it suitable for multimedia applications that involve various domain shifts, such as intelligent video surveillance and VR/AR technologies. With the success of large-scale Vision-Language Models, recent S-DGOD approaches exploit pre-trained vision-language knowledge to guide invariant feature learning across visual domains. However, the utilized knowledge remains at a coarse-grained level~(e.g., the textual description of adverse weather paired with the image) and serves as an implicit regularization for guidance, struggling to learn accurate region- and object-level features in varying domains. In this work, we propose a new cross-modal feature learning method, which can capture generalized and discriminative regional features for S-DGOD tasks. The core of our method is the mechanism of Cross-modal and Region-aware Feature Interaction, which simultaneously learns both inter-modal and intra-modal regional invariance through dynamic interactions between fine-grained textual and visual features. Moreover, we design a simple but effective strategy called Cross-domain Proposal Refining and Mixing, which aligns the position of region proposals across multiple domains and diversifies them, enhancing the localization ability of detectors in unseen scenarios. Our method achieves new state-of-the-art results on S-DGOD benchmark datasets, with improvements of +8.8\%~mPC on Cityscapes-C and +7.9\%~mPC on DWD over baselines, demonstrating its efficacy.
PhysAug: A Physical-guided and Frequency-based Data Augmentation for Single-Domain Generalized Object Detection
Dec 16, 2024



Single-Domain Generalized Object Detection~(S-DGOD) aims to train on a single source domain for robust performance across a variety of unseen target domains by taking advantage of an object detector. Existing S-DGOD approaches often rely on data augmentation strategies, including a composition of visual transformations, to enhance the detector's generalization ability. However, the absence of real-world prior knowledge hinders data augmentation from contributing to the diversity of training data distributions. To address this issue, we propose PhysAug, a novel physical model-based non-ideal imaging condition data augmentation method, to enhance the adaptability of the S-DGOD tasks. Drawing upon the principles of atmospheric optics, we develop a universal perturbation model that serves as the foundation for our proposed PhysAug. Given that visual perturbations typically arise from the interaction of light with atmospheric particles, the image frequency spectrum is harnessed to simulate real-world variations during training. This approach fosters the detector to learn domain-invariant representations, thereby enhancing its ability to generalize across various settings. Without altering the network architecture or loss function, our approach significantly outperforms the state-of-the-art across various S-DGOD datasets. In particular, it achieves a substantial improvement of $7.3\%$ and $7.2\%$ over the baseline on DWD and Cityscape-C, highlighting its enhanced generalizability in real-world settings.
SQLfuse: Enhancing Text-to-SQL Performance through Comprehensive LLM Synergy
Jul 19, 2024



Text-to-SQL conversion is a critical innovation, simplifying the transition from complex SQL to intuitive natural language queries, especially significant given SQL's prevalence in the job market across various roles. The rise of Large Language Models (LLMs) like GPT-3.5 and GPT-4 has greatly advanced this field, offering improved natural language understanding and the ability to generate nuanced SQL statements. However, the potential of open-source LLMs in Text-to-SQL applications remains underexplored, with many frameworks failing to leverage their full capabilities, particularly in handling complex database queries and incorporating feedback for iterative refinement. Addressing these limitations, this paper introduces SQLfuse, a robust system integrating open-source LLMs with a suite of tools to enhance Text-to-SQL translation's accuracy and usability. SQLfuse features four modules: schema mining, schema linking, SQL generation, and a SQL critic module, to not only generate but also continuously enhance SQL query quality. Demonstrated by its leading performance on the Spider Leaderboard and deployment by Ant Group, SQLfuse showcases the practical merits of open-source LLMs in diverse business contexts.
Demonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models
Apr 18, 2024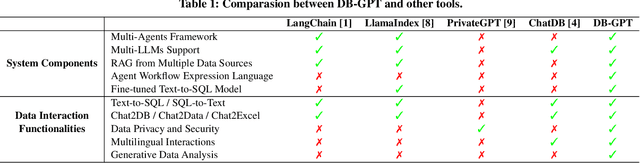
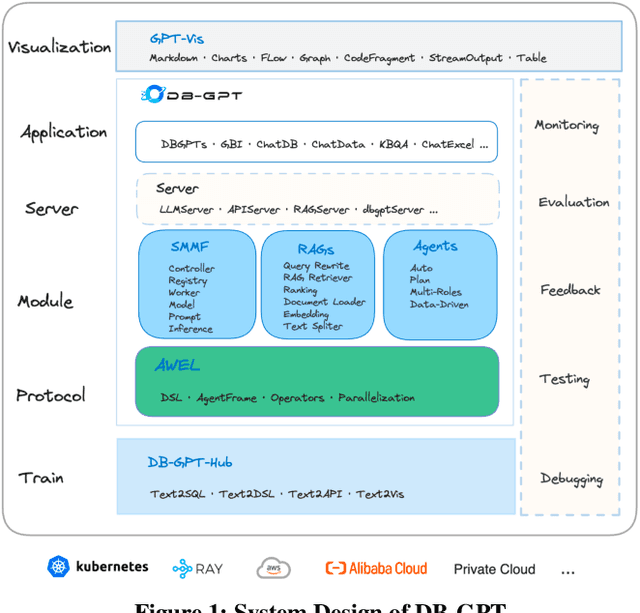

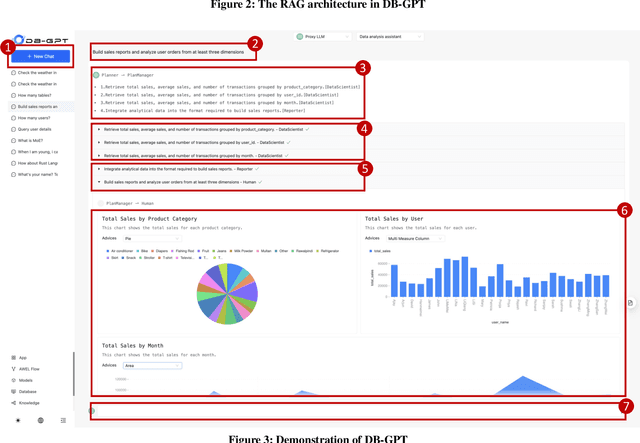
The recent breakthroughs in large language models (LLMs) are positioned to transition many areas of software. The technologies of interacting with data particularly have an important entanglement with LLMs as efficient and intuitive data interactions are paramount. In this paper, we present DB-GPT, a revolutionary and product-ready Python library that integrates LLMs into traditional data interaction tasks to enhance user experience and accessibility. DB-GPT is designed to understand data interaction tasks described by natural language and provide context-aware responses powered by LLMs, making it an indispensable tool for users ranging from novice to expert. Its system design supports deployment across local, distributed, and cloud environments. Beyond handling basic data interaction tasks like Text-to-SQL with LLMs, it can handle complex tasks like generative data analysis through a Multi-Agents framework and the Agentic Workflow Expression Language (AWEL). The Service-oriented Multi-model Management Framework (SMMF) ensures data privacy and security, enabling users to employ DB-GPT with private LLMs. Additionally, DB-GPT offers a series of product-ready features designed to enable users to integrate DB-GPT within their product environments easily. The code of DB-GPT is available at Github(https://github.com/eosphoros-ai/DB-GPT) which already has over 10.7k stars. Please install DB-GPT for your own usage with the instructions(https://github.com/eosphoros-ai/DB-GPT#install) and watch a 5-minute introduction video on Youtube(https://youtu.be/n_8RI1ENyl4) to further investigate DB-GPT.
BALANCE: Bayesian Linear Attribution for Root Cause Localization
Jan 31, 2023



Root Cause Analysis (RCA) plays an indispensable role in distributed data system maintenance and operations, as it bridges the gap between fault detection and system recovery. Existing works mainly study multidimensional localization or graph-based root cause localization. This paper opens up the possibilities of exploiting the recently developed framework of explainable AI (XAI) for the purpose of RCA. In particular, we propose BALANCE (BAyesian Linear AttributioN for root CausE localization), which formulates the problem of RCA through the lens of attribution in XAI and seeks to explain the anomalies in the target KPIs by the behavior of the candidate root causes. BALANCE consists of three innovative components. First, we propose a Bayesian multicollinear feature selection (BMFS) model to predict the target KPIs given the candidate root causes in a forward manner while promoting sparsity and concurrently paying attention to the correlation between the candidate root causes. Second, we introduce attribution analysis to compute the attribution score for each candidate in a backward manner. Third, we merge the estimated root causes related to each KPI if there are multiple KPIs. We extensively evaluate the proposed BALANCE method on one synthesis dataset as well as three real-world RCA tasks, that is, bad SQL localization, container fault localization, and fault type diagnosis for Exathlon. Results show that BALANCE outperforms the state-of-the-art (SOTA) methods in terms of accuracy with the least amount of running time, and achieves at least $6\%$ notably higher accuracy than SOTA methods for real tasks. BALANCE has been deployed to production to tackle real-world RCA problems, and the online results further advocate its usage for real-time diagnosis in distributed data systems.