 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Collapse in Sequential Post-Training of Large Language Models
May 28, 2026Large language models are now adapted through chains of post-training stages rather than through a single instruction-tuning pass. This paper studies whether such sequential post-training gradually compresses internal representations into low-rank, anisotropic, and homogeneous feature spaces. We define a measurement suite for hidden states, logits, token trajectories, and LoRA updates, and we use it to analyze supervised fine-tuning, preference optimization, safety/refusal tuning, math and code specialization, and long chain-of-thought tuning under controlled stage orderings. The central hypothesis is that excessive representation concentration is not merely a geometric curiosity: it predicts reduced plasticity during later adaptation, weaker out-of-domain generalization, and poorer calibration. We further evaluate lightweight interventions, including mixed-domain replay, feature refresh, representation diversity regularization, and LoRA update decorrelation, as ways to preserve future learnability without giving up the behavioral gains of post-training.
Towards Domain-Generalized Open-Vocabulary Object Detection: A Progressive Domain-invariant Cross-modal Alignment Method
Mar 29, 2026Open-Vocabulary Object Detection (OVOD) has achieved remarkable success in generalizing to novel categories. However, this success often rests on the implicit assumption of domain stationarity. In this work, we provide a principled revisit of the OVOD paradigm, uncovering a fundamental vulnerability: the fragile coupling between visual manifolds and textual embeddings when distribution shifts occur. We first systematically formalize Domain-Generalized Open-Vocabulary Object Detection (DG-OVOD). Through empirical analysis, we demonstrate that visual shifts do not merely add noise; they cause a collapse of the latent cross-modal space where novel category visual signals detach from their semantic anchors. Motivated by these insights, we propose Progressive Domain-invariant Cross-modal Alignment (PICA). PICA departs from uniform training by introducing a multi-level ambiguity and signal strength curriculum. It builds adaptive pseudo-word prototypes, refined via sample confidence and visual consistency, to enforce invariant cross-domain modality alignment. Our findings suggest that OVOD's robustness to domain shifts is intrinsically linked to the stability of the latent cross-modal alignment space. Our work provides both a challenging benchmark and a new perspective on building truly generalizable open-vocabulary systems that extend beyond static laboratory conditions.
Boosting Single-domain Generalized Object Detection via Vision-Language Knowledge Interaction
Apr 27, 2025
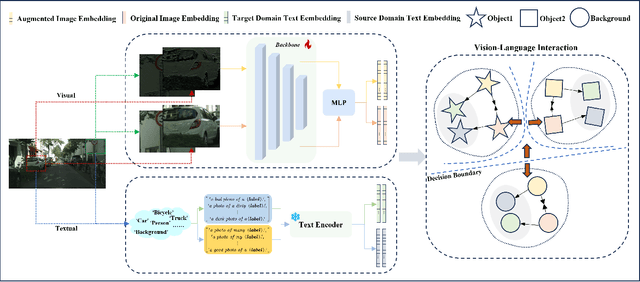


Single-Domain Generalized Object Detection~(S-DGOD) aims to train an object detector on a single source domain while generalizing well to diverse unseen target domains, making it suitable for multimedia applications that involve various domain shifts, such as intelligent video surveillance and VR/AR technologies. With the success of large-scale Vision-Language Models, recent S-DGOD approaches exploit pre-trained vision-language knowledge to guide invariant feature learning across visual domains. However, the utilized knowledge remains at a coarse-grained level~(e.g., the textual description of adverse weather paired with the image) and serves as an implicit regularization for guidance, struggling to learn accurate region- and object-level features in varying domains. In this work, we propose a new cross-modal feature learning method, which can capture generalized and discriminative regional features for S-DGOD tasks. The core of our method is the mechanism of Cross-modal and Region-aware Feature Interaction, which simultaneously learns both inter-modal and intra-modal regional invariance through dynamic interactions between fine-grained textual and visual features. Moreover, we design a simple but effective strategy called Cross-domain Proposal Refining and Mixing, which aligns the position of region proposals across multiple domains and diversifies them, enhancing the localization ability of detectors in unseen scenarios. Our method achieves new state-of-the-art results on S-DGOD benchmark datasets, with improvements of +8.8\%~mPC on Cityscapes-C and +7.9\%~mPC on DWD over baselines, demonstrating its efficacy.
Patients Speak, AI Listens: LLM-based Analysis of Online Reviews Uncovers Key Drivers for Urgent Care Satisfaction
Mar 26, 2025Investigating the public experience of urgent care facilities is essential for promoting community healthcare development. Traditional survey methods often fall short due to limited scope, time, and spatial coverage. Crowdsourcing through online reviews or social media offers a valuable approach to gaining such insights. With recent advancements in large language models (LLMs), extracting nuanced perceptions from reviews has become feasible. This study collects Google Maps reviews across the DMV and Florida areas and conducts prompt engineering with the GPT model to analyze the aspect-based sentiment of urgent care. We first analyze the geospatial patterns of various aspects, including interpersonal factors, operational efficiency, technical quality, finances, and facilities. Next, we determine Census Block Group(CBG)-level characteristics underpinning differences in public perception, including population density, median income, GINI Index, rent-to-income ratio, household below poverty rate, no insurance rate, and unemployment rate. Our results show that interpersonal factors and operational efficiency emerge as the strongest determinants of patient satisfaction in urgent care, while technical quality, finances, and facilities show no significant independent effects when adjusted for in multivariate models. Among socioeconomic and demographic factors, only population density demonstrates a significant but modest association with patient ratings, while the remaining factors exhibit no significant correlations. Overall, this study highlights the potential of crowdsourcing to uncover the key factors that matter to residents and provide valuable insights for stakeholders to improve public satisfaction with urgent care.
PhysAug: A Physical-guided and Frequency-based Data Augmentation for Single-Domain Generalized Object Detection
Dec 16, 2024



Single-Domain Generalized Object Detection~(S-DGOD) aims to train on a single source domain for robust performance across a variety of unseen target domains by taking advantage of an object detector. Existing S-DGOD approaches often rely on data augmentation strategies, including a composition of visual transformations, to enhance the detector's generalization ability. However, the absence of real-world prior knowledge hinders data augmentation from contributing to the diversity of training data distributions. To address this issue, we propose PhysAug, a novel physical model-based non-ideal imaging condition data augmentation method, to enhance the adaptability of the S-DGOD tasks. Drawing upon the principles of atmospheric optics, we develop a universal perturbation model that serves as the foundation for our proposed PhysAug. Given that visual perturbations typically arise from the interaction of light with atmospheric particles, the image frequency spectrum is harnessed to simulate real-world variations during training. This approach fosters the detector to learn domain-invariant representations, thereby enhancing its ability to generalize across various settings. Without altering the network architecture or loss function, our approach significantly outperforms the state-of-the-art across various S-DGOD datasets. In particular, it achieves a substantial improvement of $7.3\%$ and $7.2\%$ over the baseline on DWD and Cityscape-C, highlighting its enhanced generalizability in real-world settings.
Dynamically Pruned Message Passing Networks for Large-Scale Knowledge Graph Reasoning
Sep 27, 2019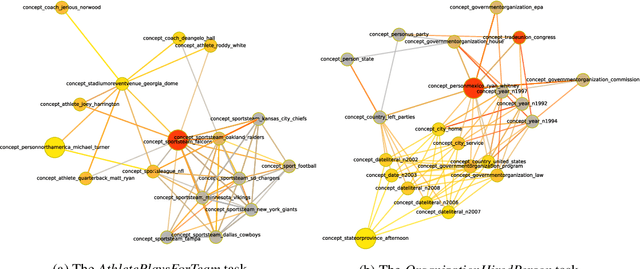


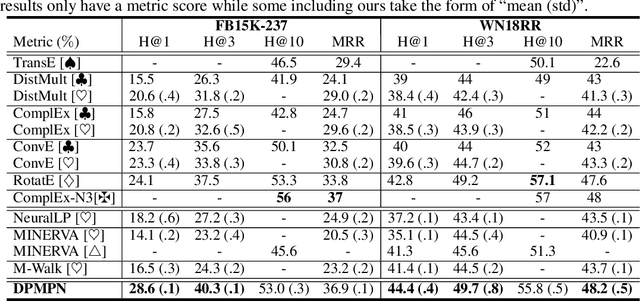
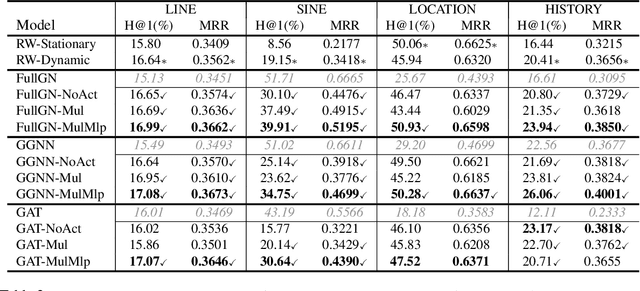
We propose Dynamically Pruned Message Passing Networks (DPMPN) for large-scale knowledge graph reasoning. In contrast to existing models, embedding-based or path-based, we learn an input-dependent subgraph to explicitly model a sequential reasoning process. Each subgraph is dynamically constructed, expanding itself selectively under a flow-style attention mechanism. In this way, we can not only construct graphical explanations to interpret prediction, but also prune message passing in Graph Neural Networks (GNNs) to scale with the size of graphs. We take the inspiration from the consciousness prior proposed by Bengio to design a two-GNN framework to encode global input-invariant graph-structured representation and learn local input-dependent one coordinated by an attention module. Experiments show the reasoning capability in our model that is providing a clear graphical explanation as well as predicting results accurately, outperforming most state-of-the-art methods in knowledge base completion tasks.
Neural Consciousness Flow
May 30, 2019
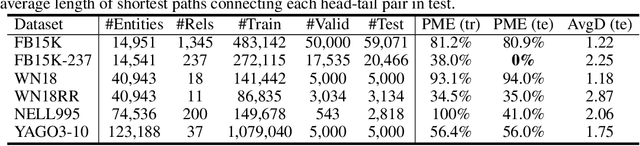
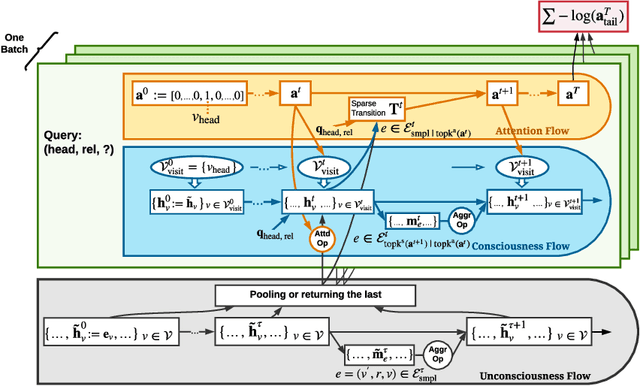
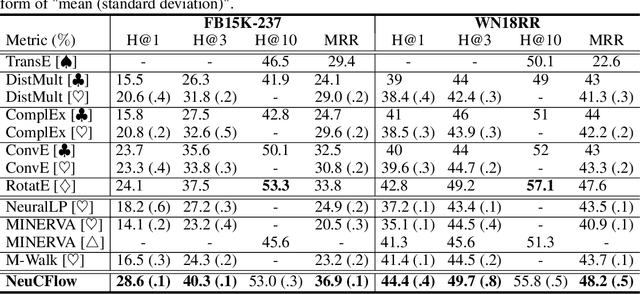
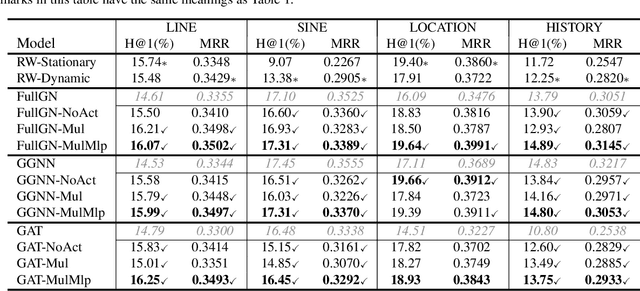
The ability of reasoning beyond data fitting is substantial to deep learning systems in order to make a leap forward towards artificial general intelligence. A lot of efforts have been made to model neural-based reasoning as an iterative decision-making process based on recurrent networks and reinforcement learning. Instead, inspired by the consciousness prior proposed by Yoshua Bengio, we explore reasoning with the notion of attentive awareness from a cognitive perspective, and formulate it in the form of attentive message passing on graphs, called neural consciousness flow (NeuCFlow). Aiming to bridge the gap between deep learning systems and reasoning, we propose an attentive computation framework with a three-layer architecture, which consists of an unconsciousness flow layer, a consciousness flow layer, and an attention flow layer. We implement the NeuCFlow model with graph neural networks (GNNs) and conditional transition matrices. Our attentive computation greatly reduces the complexity of vanilla GNN-based methods, capable of running on large-scale graphs. We validate our model for knowledge graph reasoning by solving a series of knowledge base completion (KBC) tasks. The experimental results show NeuCFlow significantly outperforms previous state-of-the-art KBC methods, including the embedding-based and the path-based. The reproducible code can be found by the link below.
Modeling Attention Flow on Graphs
Nov 01, 2018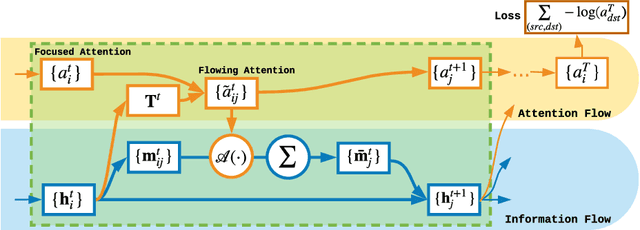

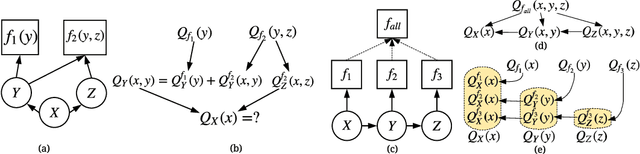
Real-world scenarios demand reasoning about process, more than final outcome prediction, to discover latent causal chains and better understand complex systems. It requires the learning algorithms to offer both accurate predictions and clear interpretations. We design a set of trajectory reasoning tasks on graphs with only the source and the destination observed. We present the attention flow mechanism to explicitly model the reasoning process, leveraging the relational inductive biases by basing our models on graph networks. We study the way attention flow can effectively act on the underlying information flow implemented by message passing. Experiments demonstrate that the attention flow driven by and interacting with graph networks can provide higher accuracy in prediction and better interpretation for trajectories reasoning.
Backprop-Q: Generalized Backpropagation for Stochastic Computation Graphs
Jul 25, 2018
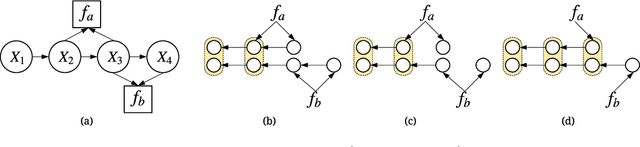
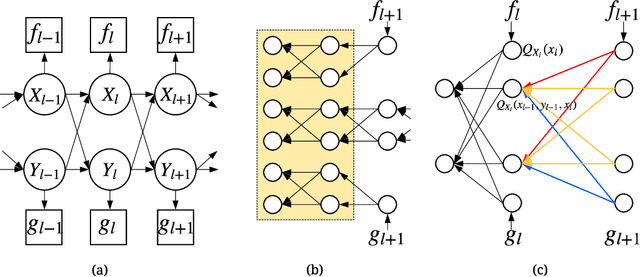
In real-world scenarios, it is appealing to learn a model carrying out stochastic operations internally, known as stochastic computation graphs (SCGs), rather than learning a deterministic mapping. However, standard backpropagation is not applicable to SCGs. We attempt to address this issue from the angle of cost propagation, with local surrogate costs, called Q-functions, constructed and learned for each stochastic node in an SCG. Then, the SCG can be trained based on these surrogate costs using standard backpropagation. We propose the entire framework as a solution to generalize backpropagation for SCGs, which resembles an actor-critic architecture but based on a graph. For broad applicability, we study a variety of SCG structures from one cost to multiple costs. We utilize recent advances in reinforcement learning (RL) and variational Bayes (VB), such as off-policy critic learning and unbiased-and-low-variance gradient estimation, and review them in the context of SCGs. The generalized backpropagation extends transported learning signals beyond gradients between stochastic nodes while preserving the benefit of backpropagating gradients through deterministic nodes. Experimental suggestions and concerns are listed to help design and test any specific model using this framework.