 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Neural Interaction Discovery for Click-Through Rate Prediction
Jun 29, 2020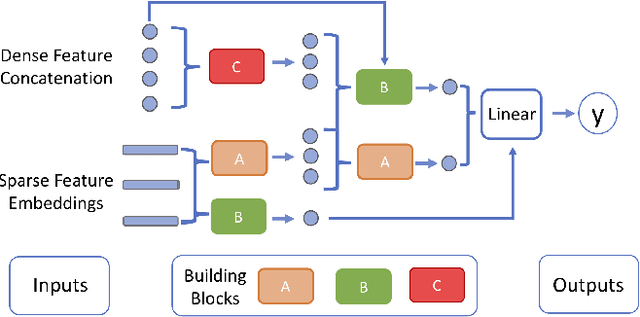
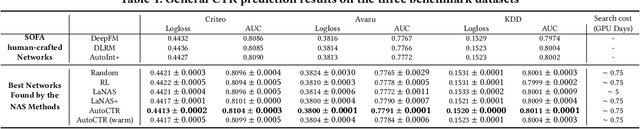
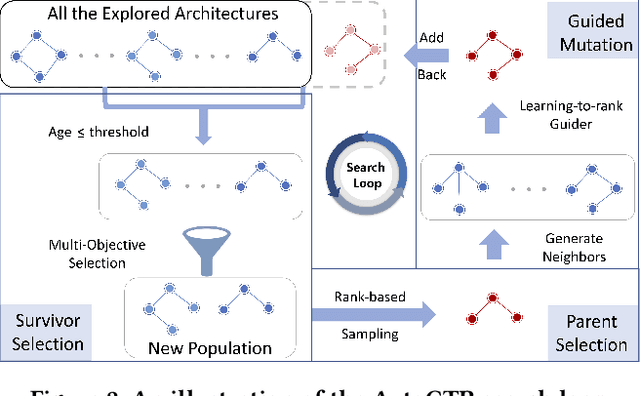
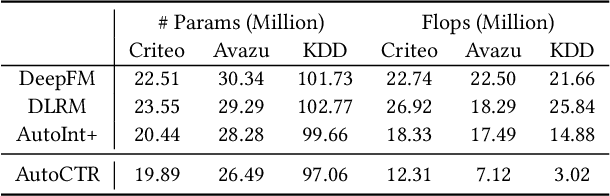
Click-Through Rate (CTR) prediction is one of the most important machine learning tasks in recommender systems, driving personalized experience for billions of consumers. Neural architecture search (NAS), as an emerging field, has demonstrated its capabilities in discovering powerful neural network architectures, which motivates us to explore its potential for CTR predictions. Due to 1) diverse unstructured feature interactions, 2) heterogeneous feature space, and 3) high data volume and intrinsic data randomness, it is challenging to construct, search, and compare different architectures effectively for recommendation models. To address these challenges, we propose an automated interaction architecture discovering framework for CTR prediction named AutoCTR. Via modularizing simple yet representative interactions as virtual building blocks and wiring them into a space of direct acyclic graphs, AutoCTR performs evolutionary architecture exploration with learning-to-rank guidance at the architecture level and achieves acceleration using low-fidelity model. Empirical analysis demonstrates the effectiveness of AutoCTR on different datasets comparing to human-crafted architectures. The discovered architecture also enjoys generalizability and transferability among different datasets.
Backprop-Q: Generalized Backpropagation for Stochastic Computation Graphs
Jul 25, 2018
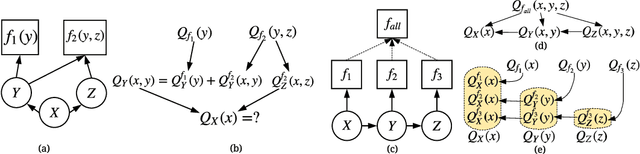
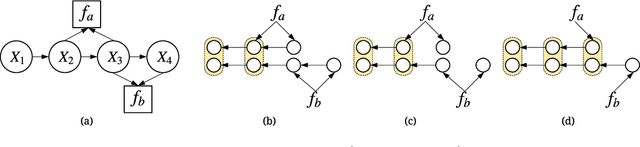
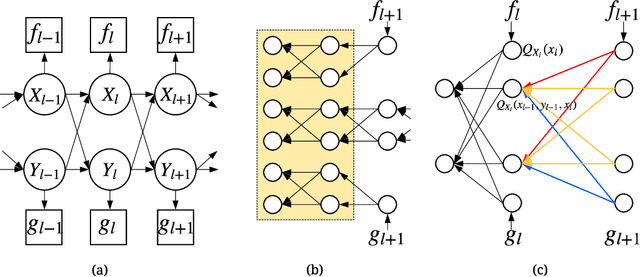
In real-world scenarios, it is appealing to learn a model carrying out stochastic operations internally, known as stochastic computation graphs (SCGs), rather than learning a deterministic mapping. However, standard backpropagation is not applicable to SCGs. We attempt to address this issue from the angle of cost propagation, with local surrogate costs, called Q-functions, constructed and learned for each stochastic node in an SCG. Then, the SCG can be trained based on these surrogate costs using standard backpropagation. We propose the entire framework as a solution to generalize backpropagation for SCGs, which resembles an actor-critic architecture but based on a graph. For broad applicability, we study a variety of SCG structures from one cost to multiple costs. We utilize recent advances in reinforcement learning (RL) and variational Bayes (VB), such as off-policy critic learning and unbiased-and-low-variance gradient estimation, and review them in the context of SCGs. The generalized backpropagation extends transported learning signals beyond gradients between stochastic nodes while preserving the benefit of backpropagating gradients through deterministic nodes. Experimental suggestions and concerns are listed to help design and test any specific model using this framework.
Content-based Video Relevance Prediction Challenge: Data, Protocol, and Baseline
Jun 03, 2018
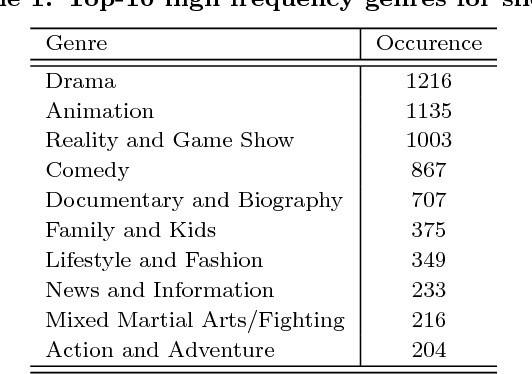
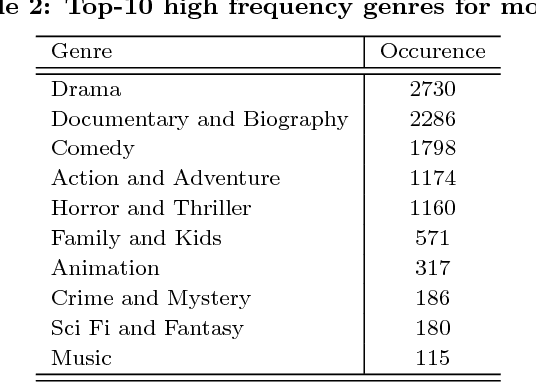
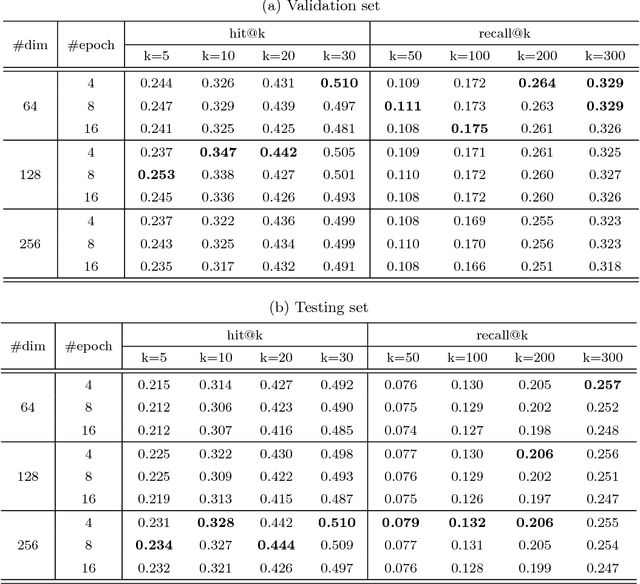
Video relevance prediction is one of the most important tasks for online streaming service. Given the relevance of videos and viewer feedbacks, the system can provide personalized recommendations, which will help the user discover more content of interest. In most online service, the computation of video relevance table is based on users' implicit feedback, e.g. watch and search history. However, this kind of method performs poorly for "cold-start" problems - when a new video is added to the library, the recommendation system needs to bootstrap the video relevance score with very little user behavior known. One promising approach to solve it is analyzing video content itself, i.e. predicting video relevance by video frame, audio, subtitle and metadata. In this paper, we describe a challenge on Content-based Video Relevance Prediction (CBVRP) that is hosted by Hulu in the ACM Multimedia Conference 2018. In this challenge, Hulu drives the study on an open problem of exploiting content characteristics directly from original video for video relevance prediction. We provide massive video assets and ground truth relevance derived from our really system, to build up a common platform for algorithm development and performance evaluation.
Variational Deep Embedding: An Unsupervised and Generative Approach to Clustering
Jun 28, 2017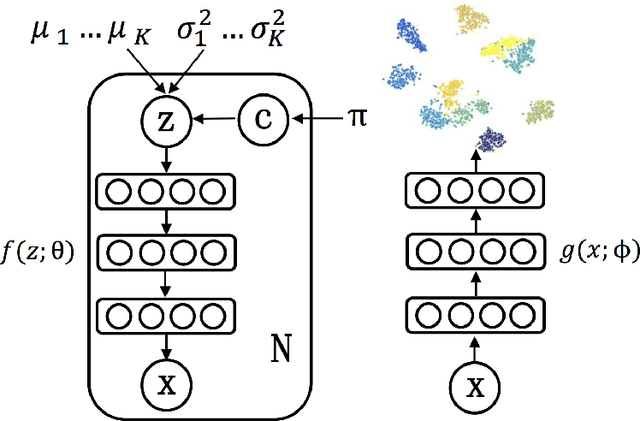
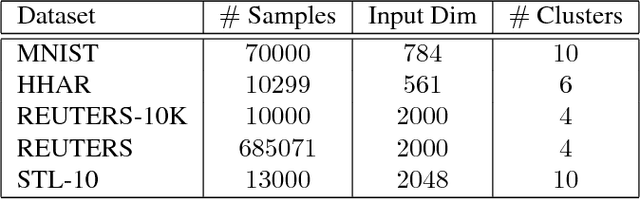
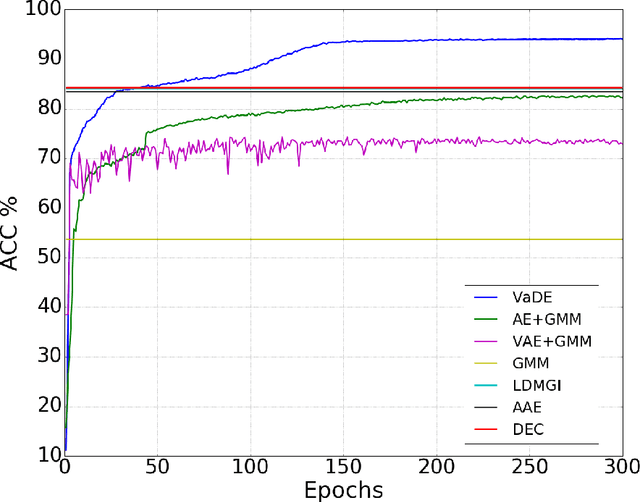
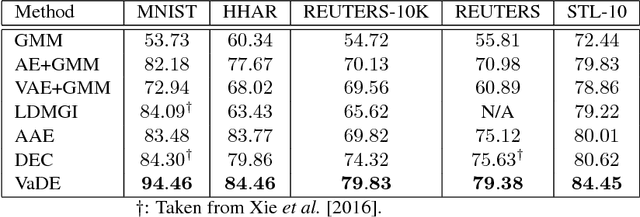
Clustering is among the most fundamental tasks in computer vision and machine learning. In this paper, we propose Variational Deep Embedding (VaDE), a novel unsupervised generative clustering approach within the framework of Variational Auto-Encoder (VAE). Specifically, VaDE models the data generative procedure with a Gaussian Mixture Model (GMM) and a deep neural network (DNN): 1) the GMM picks a cluster; 2) from which a latent embedding is generated; 3) then the DNN decodes the latent embedding into observables. Inference in VaDE is done in a variational way: a different DNN is used to encode observables to latent embeddings, so that the evidence lower bound (ELBO) can be optimized using Stochastic Gradient Variational Bayes (SGVB) estimator and the reparameterization trick. Quantitative comparisons with strong baselines are included in this paper, and experimental results show that VaDE significantly outperforms the state-of-the-art clustering methods on 4 benchmarks from various modalities. Moreover, by VaDE's generative nature, we show its capability of generating highly realistic samples for any specified cluster, without using supervised information during training. Lastly, VaDE is a flexible and extensible framework for unsupervised generative clustering, more general mixture models than GMM can be easily plugged in.
A Neural Autoregressive Approach to Collaborative Filtering
May 31, 2016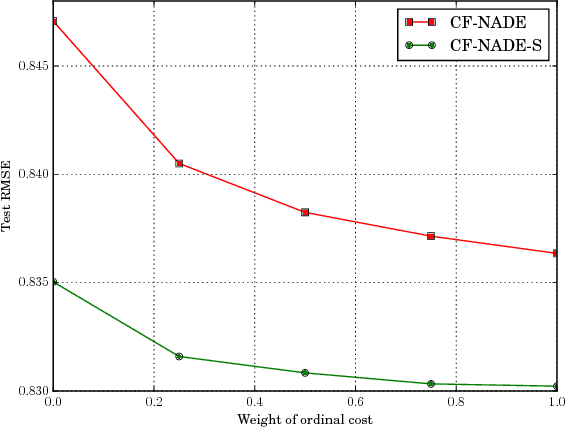
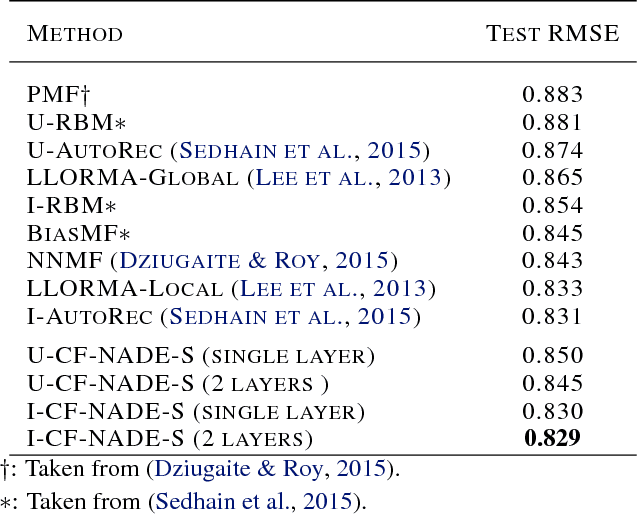
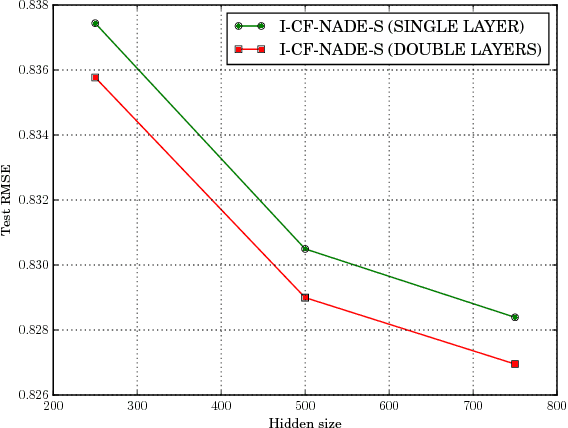
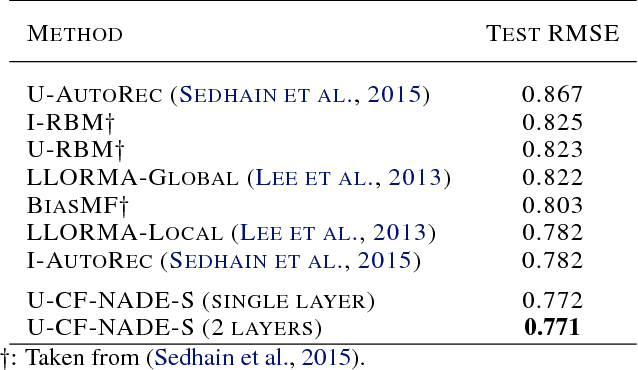
This paper proposes CF-NADE, a neural autoregressive architecture for collaborative filtering (CF) tasks, which is inspired by the Restricted Boltzmann Machine (RBM) based CF model and the Neural Autoregressive Distribution Estimator (NADE). We first describe the basic CF-NADE model for CF tasks. Then we propose to improve the model by sharing parameters between different ratings. A factored version of CF-NADE is also proposed for better scalability. Furthermore, we take the ordinal nature of the preferences into consideration and propose an ordinal cost to optimize CF-NADE, which shows superior performance. Finally, CF-NADE can be extended to a deep model, with only moderately increased computational complexity. Experimental results show that CF-NADE with a single hidden layer beats all previous state-of-the-art methods on MovieLens 1M, MovieLens 10M, and Netflix datasets, and adding more hidden layers can further improve the performance.