 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Attentional Controllable Video Diffusion Editing
Dec 16, 2024Editing videos with textual guidance has garnered popularity due to its streamlined process which mandates users to solely edit the text prompt corresponding to the source video. Recent studies have explored and exploited large-scale text-to-image diffusion models for text-guided video editing, resulting in remarkable video editing capabilities. However, they may still suffer from some limitations such as mislocated objects, incorrect number of objects. Therefore, the controllability of video editing remains a formidable challenge. In this paper, we aim to challenge the above limitations by proposing a Re-Attentional Controllable Video Diffusion Editing (ReAtCo) method. Specially, to align the spatial placement of the target objects with the edited text prompt in a training-free manner, we propose a Re-Attentional Diffusion (RAD) to refocus the cross-attention activation responses between the edited text prompt and the target video during the denoising stage, resulting in a spatially location-aligned and semantically high-fidelity manipulated video. In particular, to faithfully preserve the invariant region content with less border artifacts, we propose an Invariant Region-guided Joint Sampling (IRJS) strategy to mitigate the intrinsic sampling errors w.r.t the invariant regions at each denoising timestep and constrain the generated content to be harmonized with the invariant region content. Experimental results verify that ReAtCo consistently improves the controllability of video diffusion editing and achieves superior video editing performance.
Distortion-aware Monocular Depth Estimation for Omnidirectional Images
Oct 18, 2020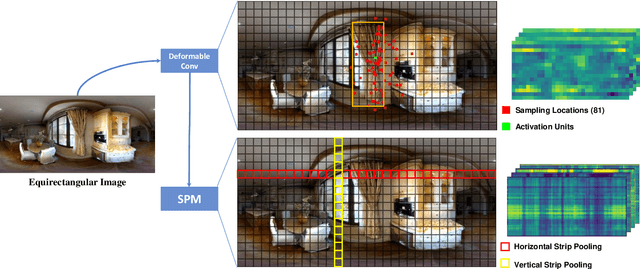
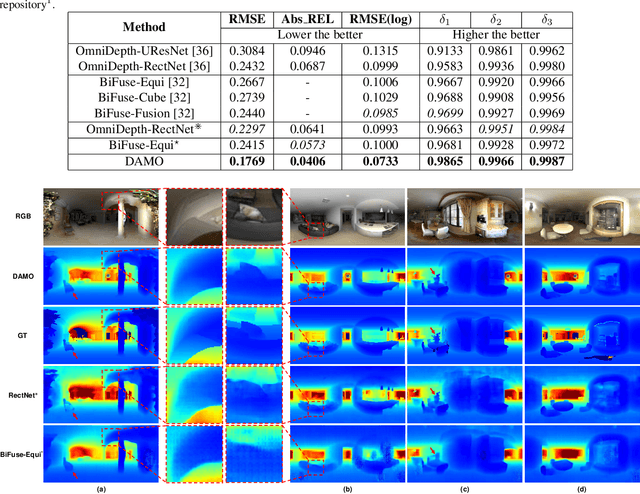
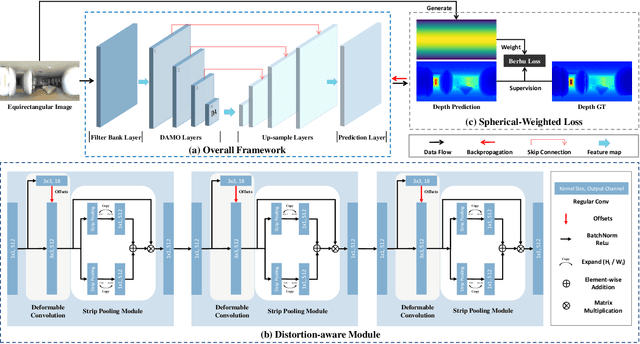
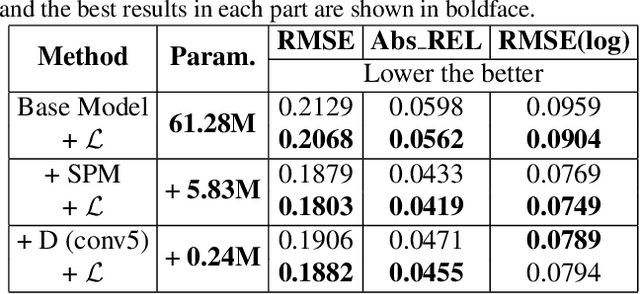
A main challenge for tasks on panorama lies in the distortion of objects among images. In this work, we propose a Distortion-Aware Monocular Omnidirectional (DAMO) dense depth estimation network to address this challenge on indoor panoramas with two steps. First, we introduce a distortion-aware module to extract calibrated semantic features from omnidirectional images. Specifically, we exploit deformable convolution to adjust its sampling grids to geometric variations of distorted objects on panoramas and then utilize a strip pooling module to sample against horizontal distortion introduced by inverse gnomonic projection. Second, we further introduce a plug-and-play spherical-aware weight matrix for our objective function to handle the uneven distribution of areas projected from a sphere. Experiments on the 360D dataset show that the proposed method can effectively extract semantic features from distorted panoramas and alleviate the supervision bias caused by distortion. It achieves state-of-the-art performance on the 360D dataset with high efficiency.
Learning Local Features with Context Aggregation for Visual Localization
May 30, 2020
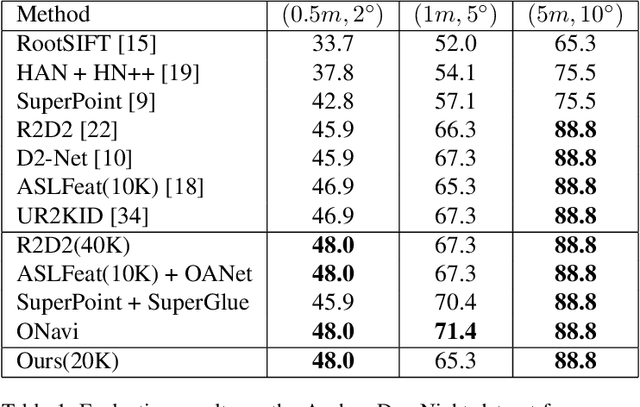
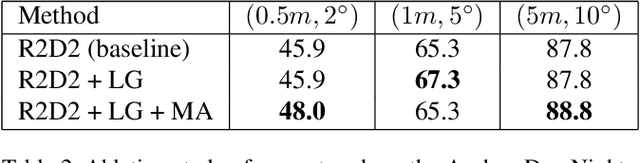

Keypoint detection and description is fundamental yet important in many vision applications. Most existing methods use detect-then-describe or detect-and-describe strategy to learn local features without considering their context information. Consequently, it is challenging for these methods to learn robust local features. In this paper, we focus on the fusion of low-level textual information and high-level semantic context information to improve the discrimitiveness of local features. Specifically, we first estimate a score map to represent the distribution of potential keypoints according to the quality of descriptors of all pixels. Then, we extract and aggregate multi-scale high-level semantic features based by the guidance of the score map. Finally, the low-level local features and high-level semantic features are fused and refined using a residual module. Experiments on the challenging local feature benchmark dataset demonstrate that our method achieves the state-of-the-art performance in the local feature challenge of the visual localization benchmark.
Content-based Video Relevance Prediction Challenge: Data, Protocol, and Baseline
Jun 03, 2018
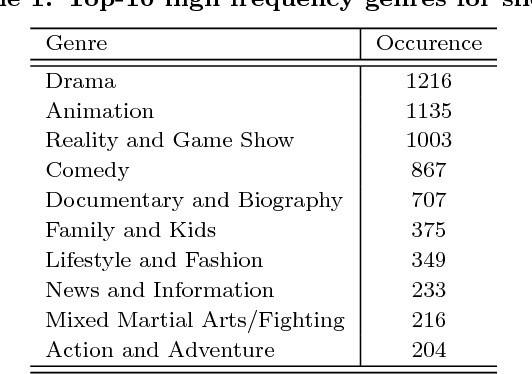
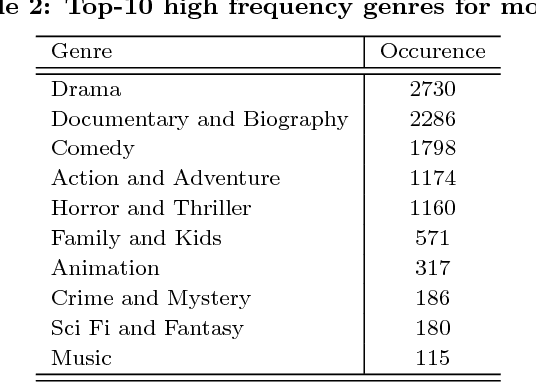
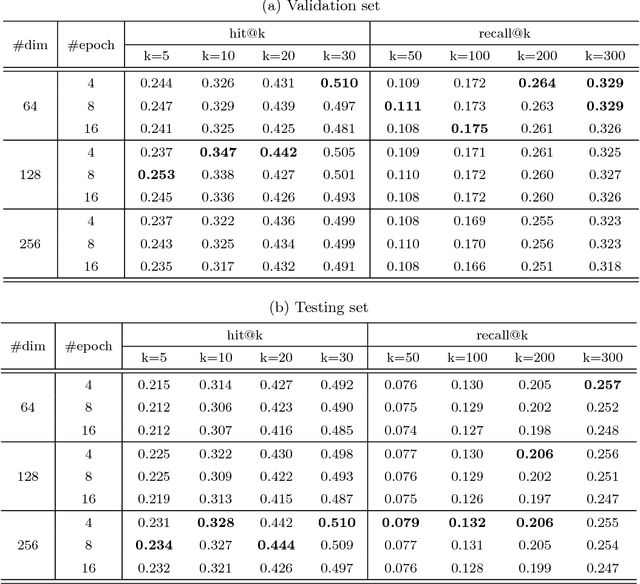
Video relevance prediction is one of the most important tasks for online streaming service. Given the relevance of videos and viewer feedbacks, the system can provide personalized recommendations, which will help the user discover more content of interest. In most online service, the computation of video relevance table is based on users' implicit feedback, e.g. watch and search history. However, this kind of method performs poorly for "cold-start" problems - when a new video is added to the library, the recommendation system needs to bootstrap the video relevance score with very little user behavior known. One promising approach to solve it is analyzing video content itself, i.e. predicting video relevance by video frame, audio, subtitle and metadata. In this paper, we describe a challenge on Content-based Video Relevance Prediction (CBVRP) that is hosted by Hulu in the ACM Multimedia Conference 2018. In this challenge, Hulu drives the study on an open problem of exploiting content characteristics directly from original video for video relevance prediction. We provide massive video assets and ground truth relevance derived from our really system, to build up a common platform for algorithm development and performance evaluation.
Self-paced Learning for Weakly Supervised Evidence Discovery in Multimedia Event Search
Oct 23, 2017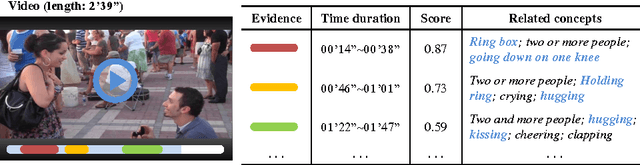
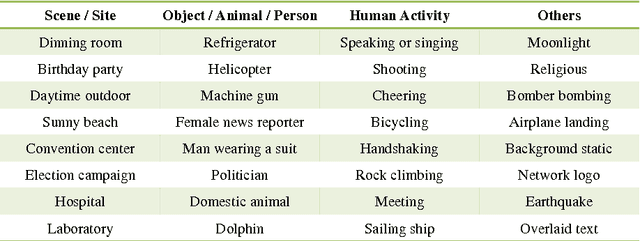
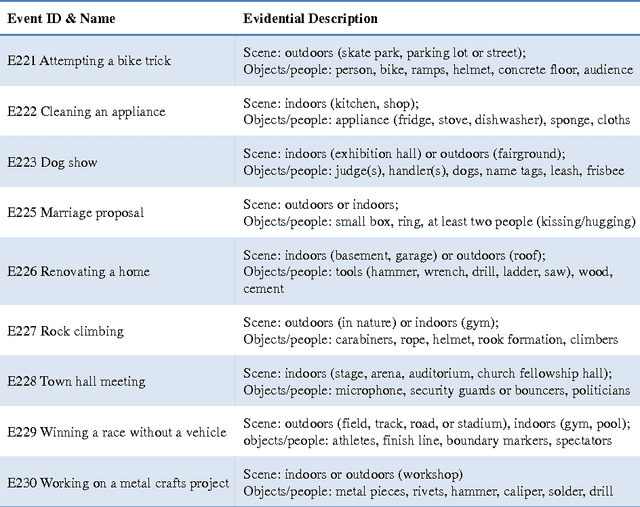

Multimedia event detection has been receiving increasing attention in recent years. Besides recognizing an event, the discovery of evidences (which is refered to as "recounting") is also crucial for user to better understand the searching result. Due to the difficulty of evidence annotation, only limited supervision of event labels are available for training a recounting model. To deal with the problem, we propose a weakly supervised evidence discovery method based on self-paced learning framework, which follows a learning process from easy "evidences" to gradually more complex ones, and simultaneously exploit more and more positive evidence samples from numerous weakly annotated video segments. Moreover, to evaluate our method quantitatively, we also propose two metrics, \textit{PctOverlap} and \textit{F1-score}, for measuring the performance of evidence localization specifically. The experiments are conducted on a subset of TRECVID MED dataset and demonstrate the promising results obtained by our method.
Skipping Word: A Character-Sequential Representation based Framework for Question Answering
Sep 02, 2016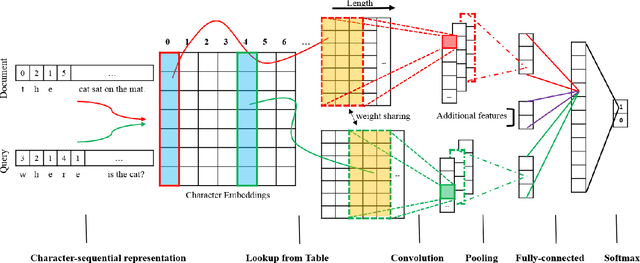
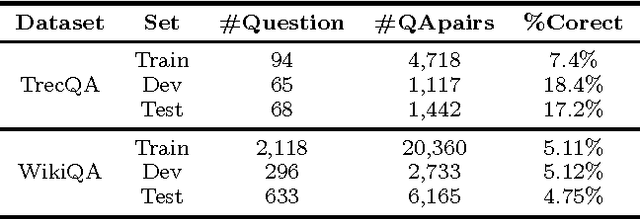

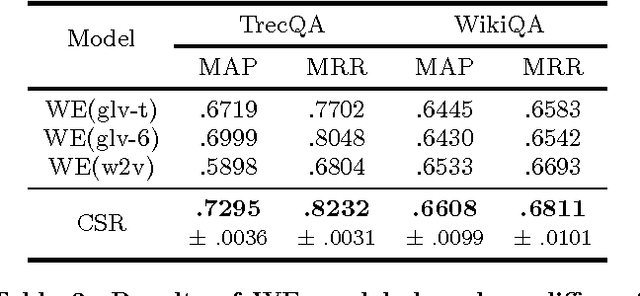
Recent works using artificial neural networks based on word distributed representation greatly boost the performance of various natural language learning tasks, especially question answering. Though, they also carry along with some attendant problems, such as corpus selection for embedding learning, dictionary transformation for different learning tasks, etc. In this paper, we propose to straightforwardly model sentences by means of character sequences, and then utilize convolutional neural networks to integrate character embedding learning together with point-wise answer selection training. Compared with deep models pre-trained on word embedding (WE) strategy, our character-sequential representation (CSR) based method shows a much simpler procedure and more stable performance across different benchmarks. Extensive experiments on two benchmark answer selection datasets exhibit the competitive performance compared with the state-of-the-art methods.
Learning Expressionlets via Universal Manifold Model for Dynamic Facial Expression Recognition
Nov 16, 2015


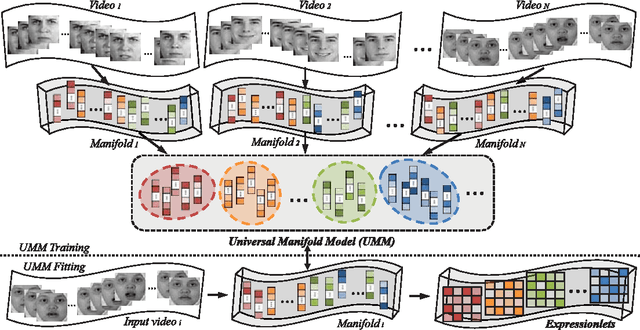
Facial expression is temporally dynamic event which can be decomposed into a set of muscle motions occurring in different facial regions over various time intervals. For dynamic expression recognition, two key issues, temporal alignment and semantics-aware dynamic representation, must be taken into account. In this paper, we attempt to solve both problems via manifold modeling of videos based on a novel mid-level representation, i.e. \textbf{expressionlet}. Specifically, our method contains three key stages: 1) each expression video clip is characterized as a spatial-temporal manifold (STM) formed by dense low-level features; 2) a Universal Manifold Model (UMM) is learned over all low-level features and represented as a set of local modes to statistically unify all the STMs. 3) the local modes on each STM can be instantiated by fitting to UMM, and the corresponding expressionlet is constructed by modeling the variations in each local mode. With above strategy, expression videos are naturally aligned both spatially and temporally. To enhance the discriminative power, the expressionlet-based STM representation is further processed with discriminant embedding. Our method is evaluated on four public expression databases, CK+, MMI, Oulu-CASIA, and FERA. In all cases, our method outperforms the known state-of-the-art by a large margin.
Learning Mid-level Words on Riemannian Manifold for Action Recognition
Nov 16, 2015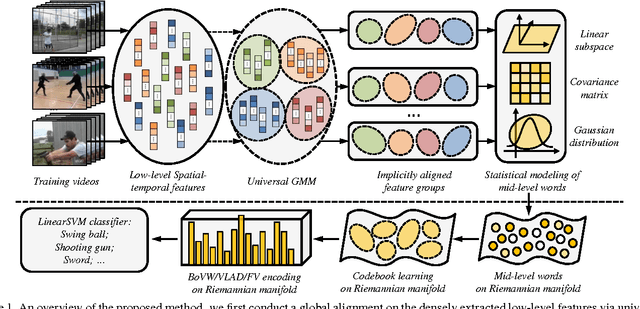



Human action recognition remains a challenging task due to the various sources of video data and large intra-class variations. It thus becomes one of the key issues in recent research to explore effective and robust representation to handle such challenges. In this paper, we propose a novel representation approach by constructing mid-level words in videos and encoding them on Riemannian manifold. Specifically, we first conduct a global alignment on the densely extracted low-level features to build a bank of corresponding feature groups, each of which can be statistically modeled as a mid-level word lying on some specific Riemannian manifold. Based on these mid-level words, we construct intrinsic Riemannian codebooks by employing K-Karcher-means clustering and Riemannian Gaussian Mixture Model, and consequently extend the Riemannian manifold version of three well studied encoding methods in Euclidean space, i.e. Bag of Visual Words (BoVW), Vector of Locally Aggregated Descriptors (VLAD), and Fisher Vector (FV), to obtain the final action video representations. Our method is evaluated in two tasks on four popular realistic datasets: action recognition on YouTube, UCF50, HMDB51 databases, and action similarity labeling on ASLAN database. In all cases, the reported results achieve very competitive performance with those most recent state-of-the-art works.