 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
FineCIR: Explicit Parsing of Fine-Grained Modification Semantics for Composed Image Retrieval
Mar 27, 2025
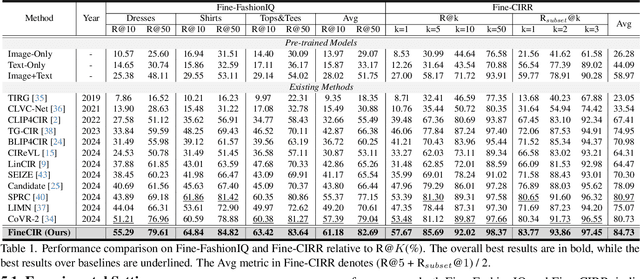
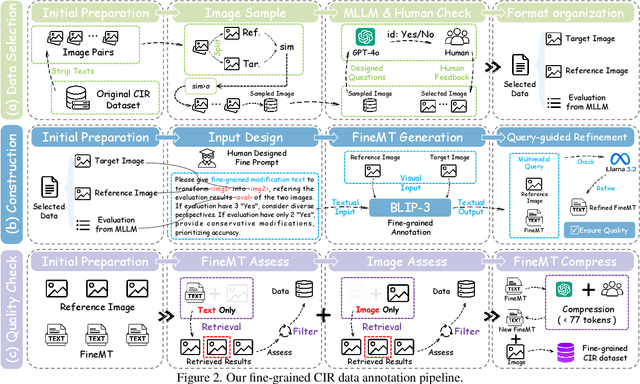
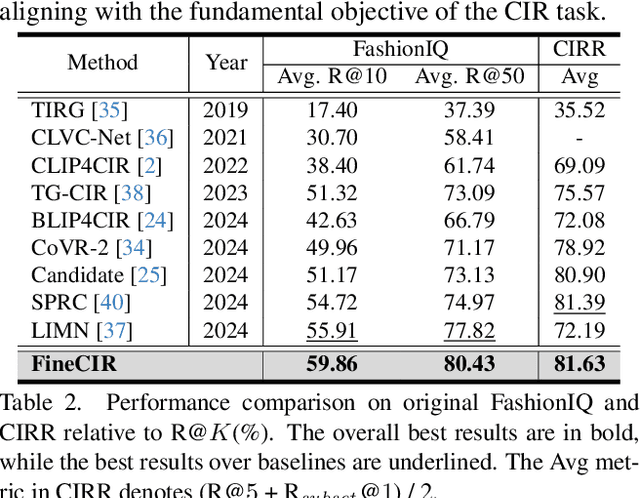
Composed Image Retrieval (CIR) facilitates image retrieval through a multimodal query consisting of a reference image and modification text. The reference image defines the retrieval context, while the modification text specifies desired alterations. However, existing CIR datasets predominantly employ coarse-grained modification text (CoarseMT), which inadequately captures fine-grained retrieval intents. This limitation introduces two key challenges: (1) ignoring detailed differences leads to imprecise positive samples, and (2) greater ambiguity arises when retrieving visually similar images. These issues degrade retrieval accuracy, necessitating manual result filtering or repeated queries. To address these limitations, we develop a robust fine-grained CIR data annotation pipeline that minimizes imprecise positive samples and enhances CIR systems' ability to discern modification intents accurately. Using this pipeline, we refine the FashionIQ and CIRR datasets to create two fine-grained CIR datasets: Fine-FashionIQ and Fine-CIRR. Furthermore, we introduce FineCIR, the first CIR framework explicitly designed to parse the modification text. FineCIR effectively captures fine-grained modification semantics and aligns them with ambiguous visual entities, enhancing retrieval precision. Extensive experiments demonstrate that FineCIR consistently outperforms state-of-the-art CIR baselines on both fine-grained and traditional CIR benchmark datasets. Our FineCIR code and fine-grained CIR datasets are available at https://github.com/SDU-L/FineCIR.git.
Distortion-aware Monocular Depth Estimation for Omnidirectional Images
Oct 18, 2020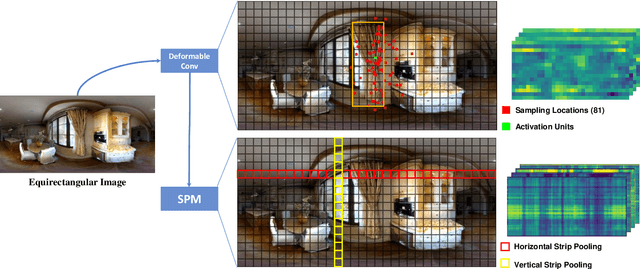
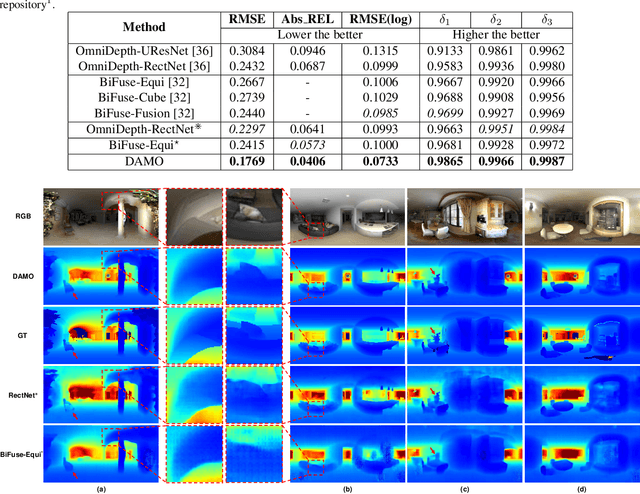
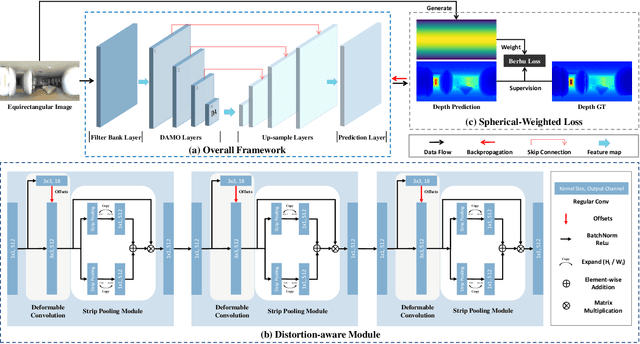
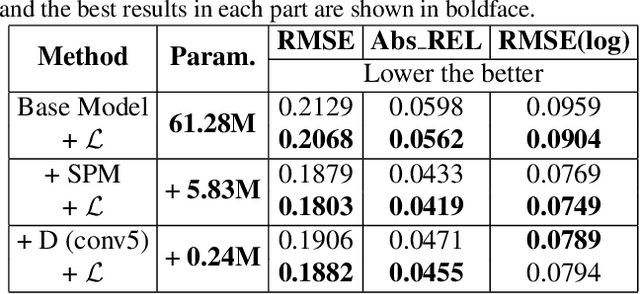
A main challenge for tasks on panorama lies in the distortion of objects among images. In this work, we propose a Distortion-Aware Monocular Omnidirectional (DAMO) dense depth estimation network to address this challenge on indoor panoramas with two steps. First, we introduce a distortion-aware module to extract calibrated semantic features from omnidirectional images. Specifically, we exploit deformable convolution to adjust its sampling grids to geometric variations of distorted objects on panoramas and then utilize a strip pooling module to sample against horizontal distortion introduced by inverse gnomonic projection. Second, we further introduce a plug-and-play spherical-aware weight matrix for our objective function to handle the uneven distribution of areas projected from a sphere. Experiments on the 360D dataset show that the proposed method can effectively extract semantic features from distorted panoramas and alleviate the supervision bias caused by distortion. It achieves state-of-the-art performance on the 360D dataset with high efficiency.
Learning Local Features with Context Aggregation for Visual Localization
May 30, 2020
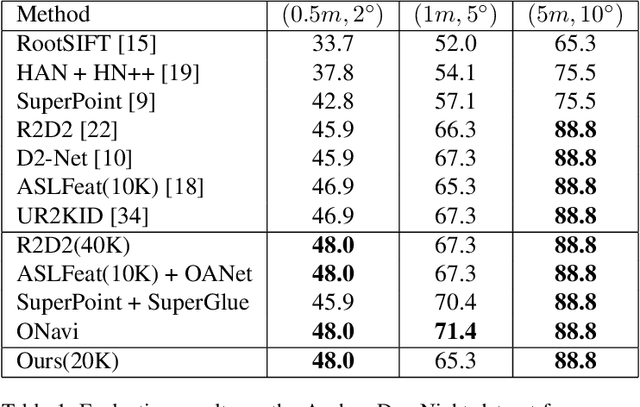
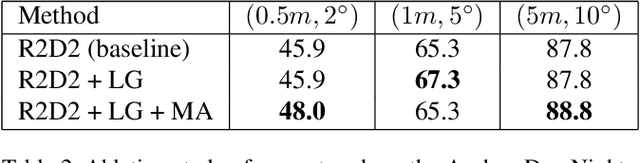

Keypoint detection and description is fundamental yet important in many vision applications. Most existing methods use detect-then-describe or detect-and-describe strategy to learn local features without considering their context information. Consequently, it is challenging for these methods to learn robust local features. In this paper, we focus on the fusion of low-level textual information and high-level semantic context information to improve the discrimitiveness of local features. Specifically, we first estimate a score map to represent the distribution of potential keypoints according to the quality of descriptors of all pixels. Then, we extract and aggregate multi-scale high-level semantic features based by the guidance of the score map. Finally, the low-level local features and high-level semantic features are fused and refined using a residual module. Experiments on the challenging local feature benchmark dataset demonstrate that our method achieves the state-of-the-art performance in the local feature challenge of the visual localization benchmark.