 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Local Features with Context Aggregation for Visual Localization
Paper and Code
May 30, 2020
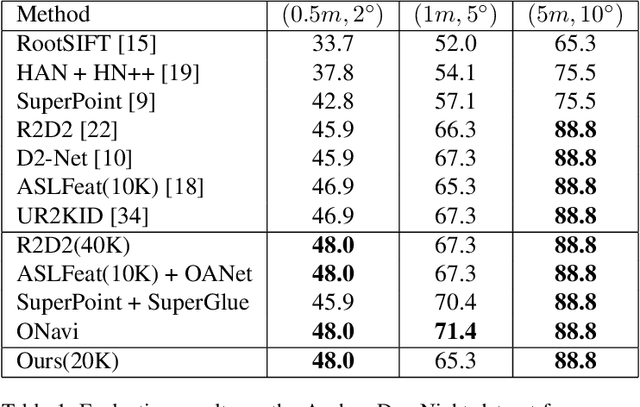
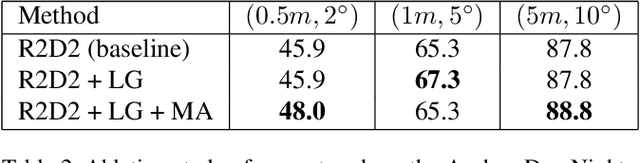

Keypoint detection and description is fundamental yet important in many vision applications. Most existing methods use detect-then-describe or detect-and-describe strategy to learn local features without considering their context information. Consequently, it is challenging for these methods to learn robust local features. In this paper, we focus on the fusion of low-level textual information and high-level semantic context information to improve the discrimitiveness of local features. Specifically, we first estimate a score map to represent the distribution of potential keypoints according to the quality of descriptors of all pixels. Then, we extract and aggregate multi-scale high-level semantic features based by the guidance of the score map. Finally, the low-level local features and high-level semantic features are fused and refined using a residual module. Experiments on the challenging local feature benchmark dataset demonstrate that our method achieves the state-of-the-art performance in the local feature challenge of the visual localization benchmark.