 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY3D-Bench: Generation of 3D Assets
Feb 03, 2026While recent advances in neural representations and generative models have revolutionized 3D content creation, the field remains constrained by significant data processing bottlenecks. To address this, we introduce HY3D-Bench, an open-source ecosystem designed to establish a unified, high-quality foundation for 3D generation. Our contributions are threefold: (1) We curate a library of 250k high-fidelity 3D objects distilled from large-scale repositories, employing a rigorous pipeline to deliver training-ready artifacts, including watertight meshes and multi-view renderings; (2) We introduce structured part-level decomposition, providing the granularity essential for fine-grained perception and controllable editing; and (3) We bridge real-world distribution gaps via a scalable AIGC synthesis pipeline, contributing 125k synthetic assets to enhance diversity in long-tail categories. Validated empirically through the training of Hunyuan3D-2.1-Small, HY3D-Bench democratizes access to robust data resources, aiming to catalyze innovation across 3D perception, robotics, and digital content creation.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
A Unified Hierarchical Framework for Fine-grained Cross-view Geo-localization over Large-scale Scenarios
May 12, 2025Cross-view geo-localization is a promising solution for large-scale localization problems, requiring the sequential execution of retrieval and metric localization tasks to achieve fine-grained predictions. However, existing methods typically focus on designing standalone models for these two tasks, resulting in inefficient collaboration and increased training overhead. In this paper, we propose UnifyGeo, a novel unified hierarchical geo-localization framework that integrates retrieval and metric localization tasks into a single network. Specifically, we first employ a unified learning strategy with shared parameters to jointly learn multi-granularity representation, facilitating mutual reinforcement between these two tasks. Subsequently, we design a re-ranking mechanism guided by a dedicated loss function, which enhances geo-localization performance by improving both retrieval accuracy and metric localization references. Extensive experiments demonstrate that UnifyGeo significantly outperforms the state-of-the-arts in both task-isolated and task-associated settings. Remarkably, on the challenging VIGOR benchmark, which supports fine-grained localization evaluation, the 1-meter-level localization recall rate improves from 1.53\% to 39.64\% and from 0.43\% to 25.58\% under same-area and cross-area evaluations, respectively. Code will be made publicly available.
Decoupling Makes Weakly Supervised Local Feature Better
Jan 08, 2022
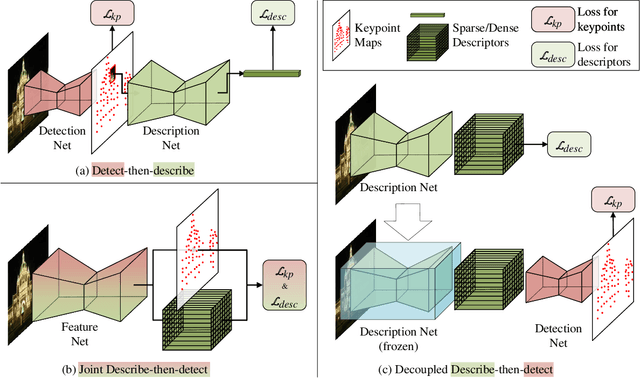

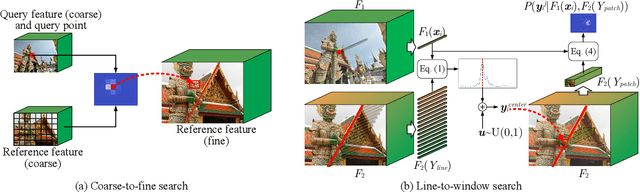
Weakly supervised learning can help local feature methods to overcome the obstacle of acquiring a large-scale dataset with densely labeled correspondences. However, since weak supervision cannot distinguish the losses caused by the detection and description steps, directly conducting weakly supervised learning within a joint describe-then-detect pipeline suffers limited performance. In this paper, we propose a decoupled describe-then-detect pipeline tailored for weakly supervised local feature learning. Within our pipeline, the detection step is decoupled from the description step and postponed until discriminative and robust descriptors are learned. In addition, we introduce a line-to-window search strategy to explicitly use the camera pose information for better descriptor learning. Extensive experiments show that our method, namely PoSFeat (Camera Pose Supervised Feature), outperforms previous fully and weakly supervised methods and achieves state-of-the-art performance on a wide range of downstream tasks.
Distortion-aware Monocular Depth Estimation for Omnidirectional Images
Oct 18, 2020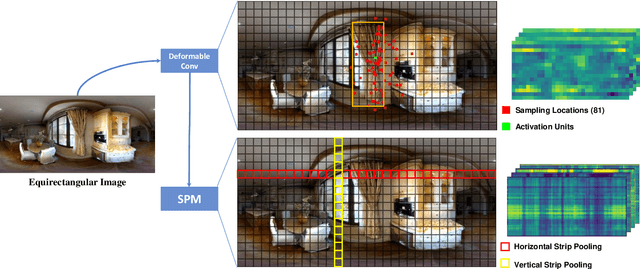
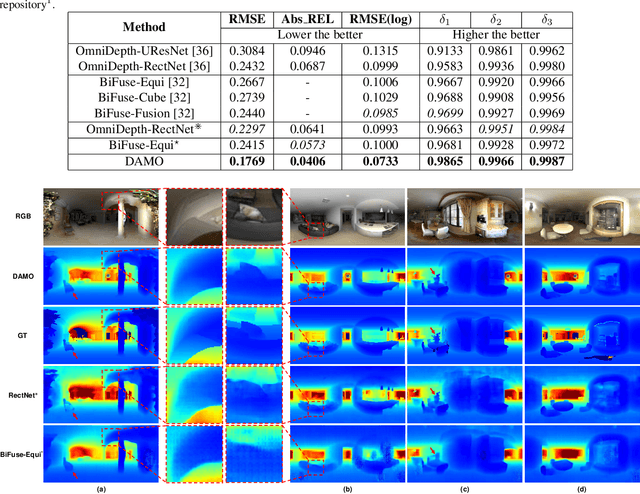
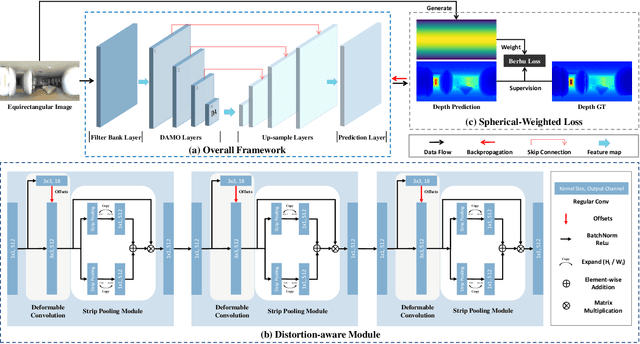
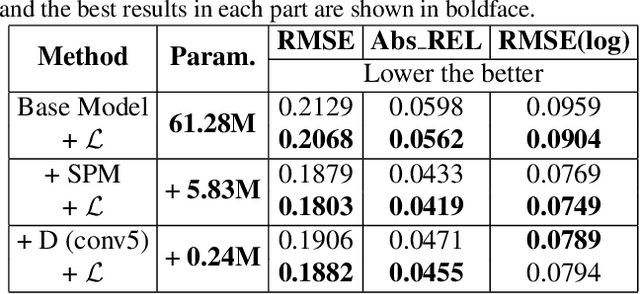
A main challenge for tasks on panorama lies in the distortion of objects among images. In this work, we propose a Distortion-Aware Monocular Omnidirectional (DAMO) dense depth estimation network to address this challenge on indoor panoramas with two steps. First, we introduce a distortion-aware module to extract calibrated semantic features from omnidirectional images. Specifically, we exploit deformable convolution to adjust its sampling grids to geometric variations of distorted objects on panoramas and then utilize a strip pooling module to sample against horizontal distortion introduced by inverse gnomonic projection. Second, we further introduce a plug-and-play spherical-aware weight matrix for our objective function to handle the uneven distribution of areas projected from a sphere. Experiments on the 360D dataset show that the proposed method can effectively extract semantic features from distorted panoramas and alleviate the supervision bias caused by distortion. It achieves state-of-the-art performance on the 360D dataset with high efficiency.
Learning Local Features with Context Aggregation for Visual Localization
May 30, 2020
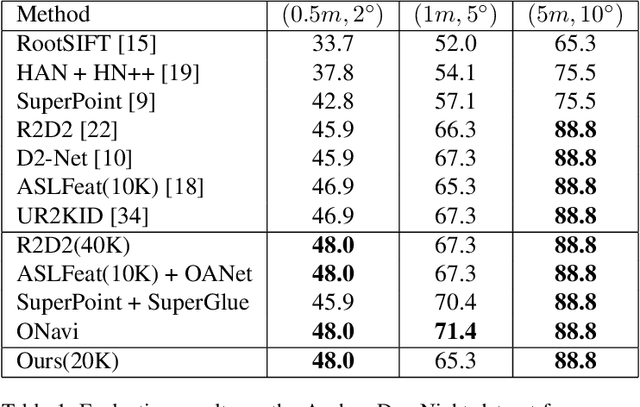
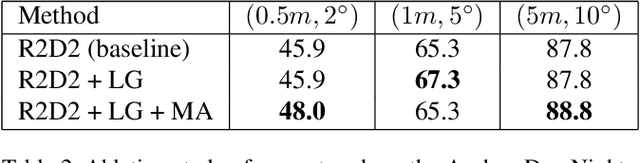

Keypoint detection and description is fundamental yet important in many vision applications. Most existing methods use detect-then-describe or detect-and-describe strategy to learn local features without considering their context information. Consequently, it is challenging for these methods to learn robust local features. In this paper, we focus on the fusion of low-level textual information and high-level semantic context information to improve the discrimitiveness of local features. Specifically, we first estimate a score map to represent the distribution of potential keypoints according to the quality of descriptors of all pixels. Then, we extract and aggregate multi-scale high-level semantic features based by the guidance of the score map. Finally, the low-level local features and high-level semantic features are fused and refined using a residual module. Experiments on the challenging local feature benchmark dataset demonstrate that our method achieves the state-of-the-art performance in the local feature challenge of the visual localization benchmark.