 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Volumetric Reconstruction for Clothed Humans
Jul 25, 2023



We present a novel method for reconstructing clothed humans from a sparse set of, e.g., 1 to 6 RGB images. Despite impressive results from recent works employing deep implicit representation, we revisit the volumetric approach and demonstrate that better performance can be achieved with proper system design. The volumetric representation offers significant advantages in leveraging 3D spatial context through 3D convolutions, and the notorious quantization error is largely negligible with a reasonably large yet affordable volume resolution, e.g., 512. To handle memory and computation costs, we propose a sophisticated coarse-to-fine strategy with voxel culling and subspace sparse convolution. Our method starts with a discretized visual hull to compute a coarse shape and then focuses on a narrow band nearby the coarse shape for refinement. Once the shape is reconstructed, we adopt an image-based rendering approach, which computes the colors of surface points by blending input images with learned weights. Extensive experimental results show that our method significantly reduces the mean point-to-surface (P2S) precision of state-of-the-art methods by more than 50% to achieve approximately 2mm accuracy with a 512 volume resolution. Additionally, images rendered from our textured model achieve a higher peak signal-to-noise ratio (PSNR) compared to state-of-the-art methods.
Decoupling Makes Weakly Supervised Local Feature Better
Jan 08, 2022
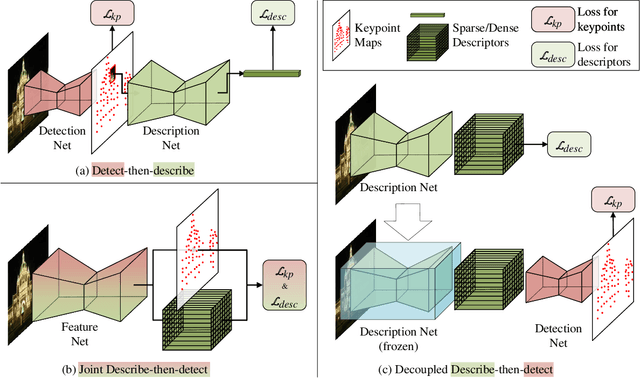

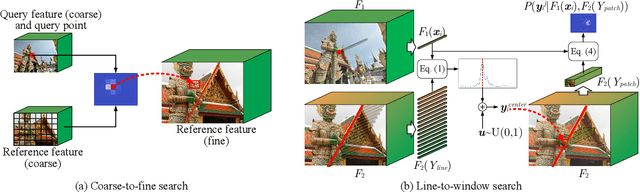
Weakly supervised learning can help local feature methods to overcome the obstacle of acquiring a large-scale dataset with densely labeled correspondences. However, since weak supervision cannot distinguish the losses caused by the detection and description steps, directly conducting weakly supervised learning within a joint describe-then-detect pipeline suffers limited performance. In this paper, we propose a decoupled describe-then-detect pipeline tailored for weakly supervised local feature learning. Within our pipeline, the detection step is decoupled from the description step and postponed until discriminative and robust descriptors are learned. In addition, we introduce a line-to-window search strategy to explicitly use the camera pose information for better descriptor learning. Extensive experiments show that our method, namely PoSFeat (Camera Pose Supervised Feature), outperforms previous fully and weakly supervised methods and achieves state-of-the-art performance on a wide range of downstream tasks.
ActiveZero: Mixed Domain Learning for Active Stereovision with Zero Annotation
Dec 06, 2021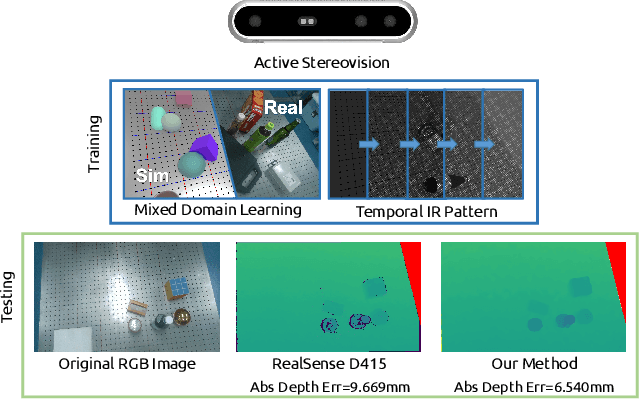
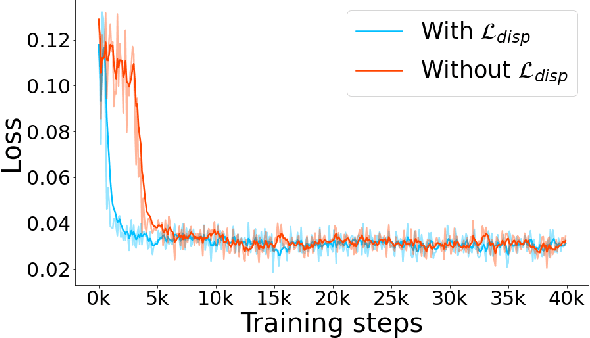
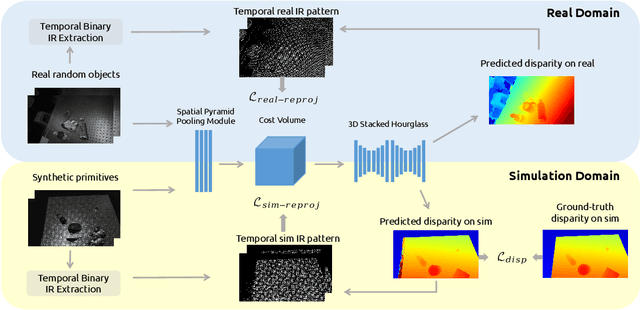
Traditional depth sensors generate accurate real world depth estimates that surpass even the most advanced learning approaches trained only on simulation domains. Since ground truth depth is readily available in the simulation domain but quite difficult to obtain in the real domain, we propose a method that leverages the best of both worlds. In this paper we present a new framework, ActiveZero, which is a mixed domain learning solution for active stereovision systems that requires no real world depth annotation. First, we demonstrate the transferability of our method to out-of-distribution real data by using a mixed domain learning strategy. In the simulation domain, we use a combination of supervised disparity loss and self-supervised losses on a shape primitives dataset. By contrast, in the real domain, we only use self-supervised losses on a dataset that is out-of-distribution from either training simulation data or test real data. Second, our method introduces a novel self-supervised loss called temporal IR reprojection to increase the robustness and accuracy of our reprojections in hard-to-perceive regions. Finally, we show how the method can be trained end-to-end and that each module is important for attaining the end result. Extensive qualitative and quantitative evaluations on real data demonstrate state of the art results that can even beat a commercial depth sensor.