 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Approach to The Detection and Classification of Skin Diseases
Nov 21, 2024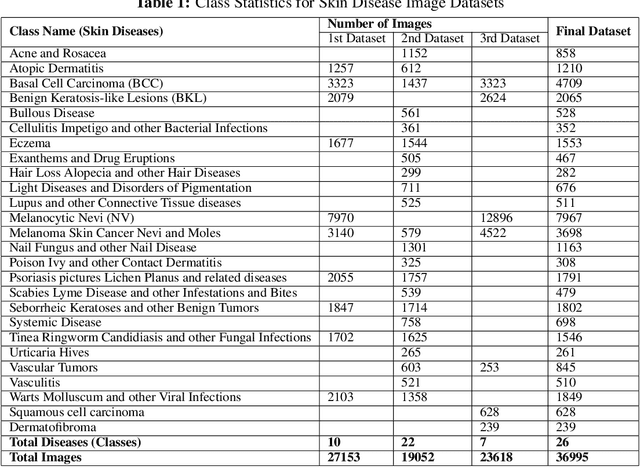
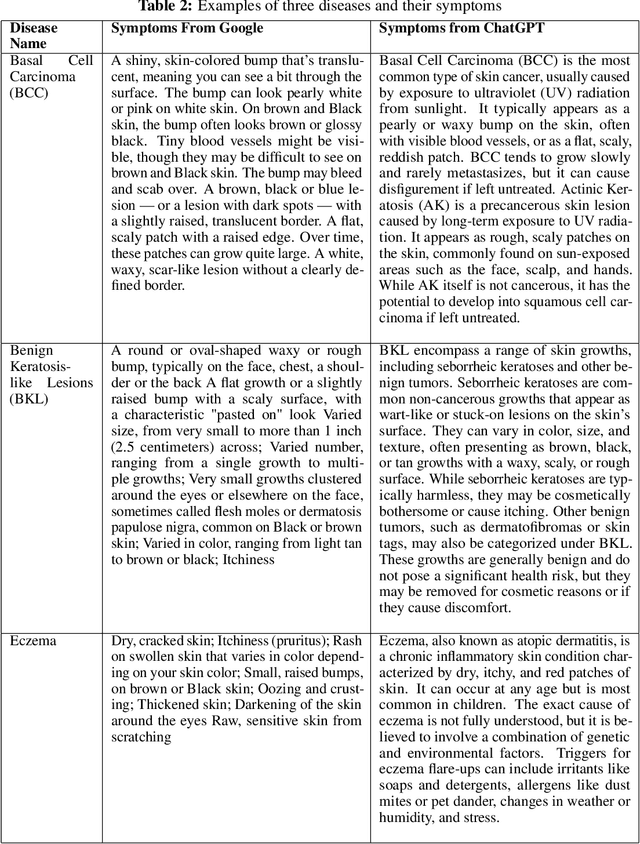
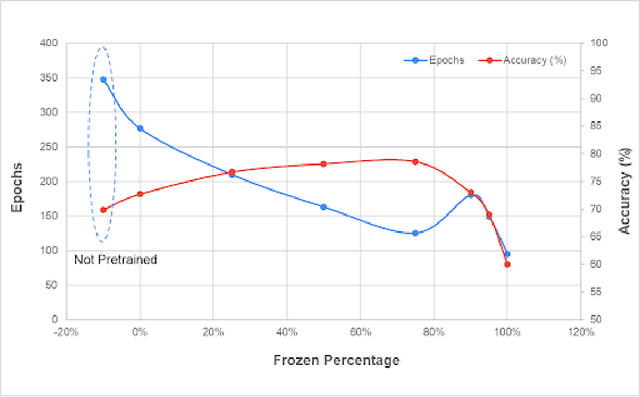
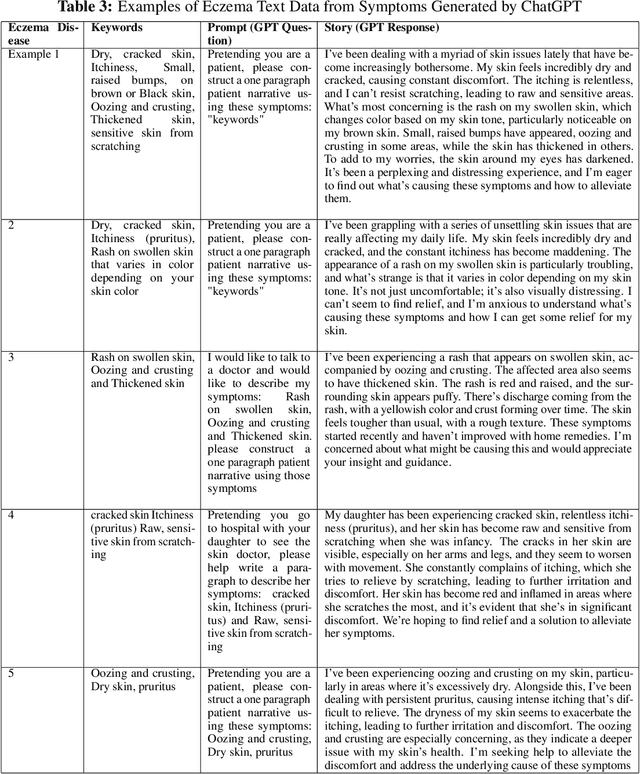
According to PBS, nearly one-third of Americans lack access to primary care services, and another forty percent delay going to avoid medical costs. As a result, many diseases are left undiagnosed and untreated, even if the disease shows many physical symptoms on the skin. With the rise of AI, self-diagnosis and improved disease recognition have become more promising than ever; in spite of that, existing methods suffer from a lack of large-scale patient databases and outdated methods of study, resulting in studies being limited to only a few diseases or modalities. This study incorporates readily available and easily accessible patient information via image and text for skin disease classification on a new dataset of 26 skin disease types that includes both skin disease images (37K) and associated patient narratives. Using this dataset, baselines for various image models were established that outperform existing methods. Initially, the Resnet-50 model was only able to achieve an accuracy of 70% but, after various optimization techniques, the accuracy was improved to 80%. In addition, this study proposes a novel fine-tuning strategy for sequence classification Large Language Models (LLMs), Chain of Options, which breaks down a complex reasoning task into intermediate steps at training time instead of inference. With Chain of Options and preliminary disease recommendations from the image model, this method achieves state of the art accuracy 91% in diagnosing patient skin disease given just an image of the afflicted area as well as a patient description of the symptoms (such as itchiness or dizziness). Through this research, an earlier diagnosis of skin diseases can occur, and clinicians can work with deep learning models to give a more accurate diagnosis, improving quality of life and saving lives.
ActiveNeRF: Learning Accurate 3D Geometry by Active Pattern Projection
Aug 13, 2024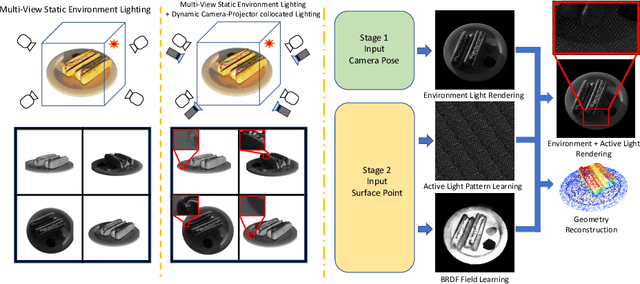

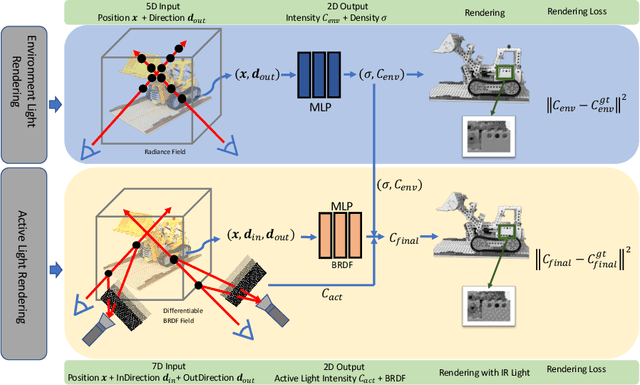

NeRFs have achieved incredible success in novel view synthesis. However, the accuracy of the implicit geometry is unsatisfactory because the passive static environmental illumination has low spatial frequency and cannot provide enough information for accurate geometry reconstruction. In this work, we propose ActiveNeRF, a 3D geometry reconstruction framework, which improves the geometry quality of NeRF by actively projecting patterns of high spatial frequency onto the scene using a projector which has a constant relative pose to the camera. We design a learnable active pattern rendering pipeline which jointly learns the scene geometry and the active pattern. We find that, by adding the active pattern and imposing its consistency across different views, our proposed method outperforms state of the art geometry reconstruction methods qualitatively and quantitatively in both simulation and real experiments. Code is avaliable at https://github.com/hcp16/active_nerf
ActiveZero: Mixed Domain Learning for Active Stereovision with Zero Annotation
Dec 06, 2021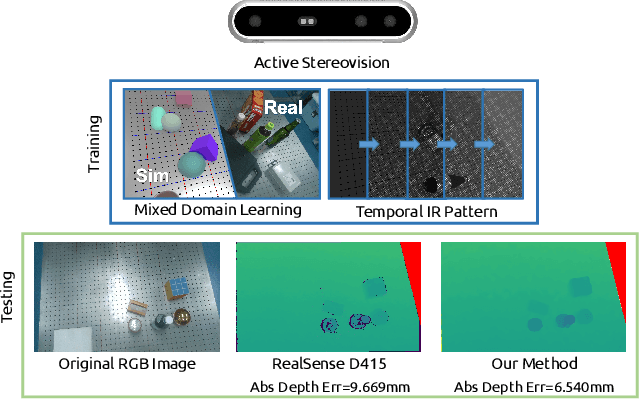
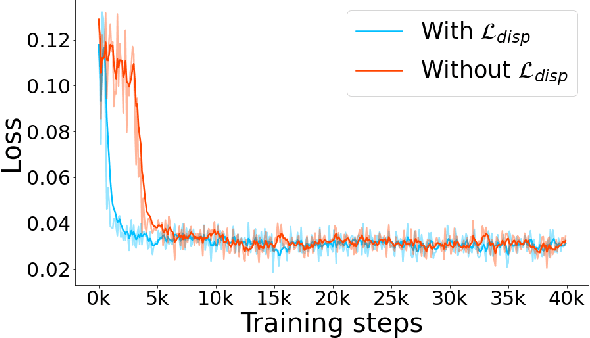
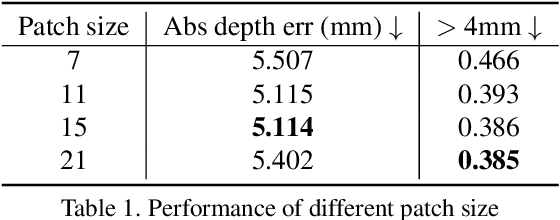
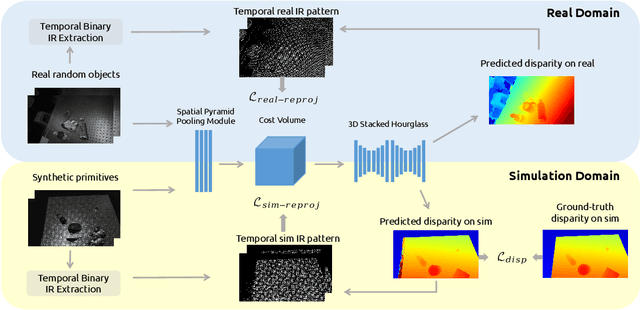
Traditional depth sensors generate accurate real world depth estimates that surpass even the most advanced learning approaches trained only on simulation domains. Since ground truth depth is readily available in the simulation domain but quite difficult to obtain in the real domain, we propose a method that leverages the best of both worlds. In this paper we present a new framework, ActiveZero, which is a mixed domain learning solution for active stereovision systems that requires no real world depth annotation. First, we demonstrate the transferability of our method to out-of-distribution real data by using a mixed domain learning strategy. In the simulation domain, we use a combination of supervised disparity loss and self-supervised losses on a shape primitives dataset. By contrast, in the real domain, we only use self-supervised losses on a dataset that is out-of-distribution from either training simulation data or test real data. Second, our method introduces a novel self-supervised loss called temporal IR reprojection to increase the robustness and accuracy of our reprojections in hard-to-perceive regions. Finally, we show how the method can be trained end-to-end and that each module is important for attaining the end result. Extensive qualitative and quantitative evaluations on real data demonstrate state of the art results that can even beat a commercial depth sensor.
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019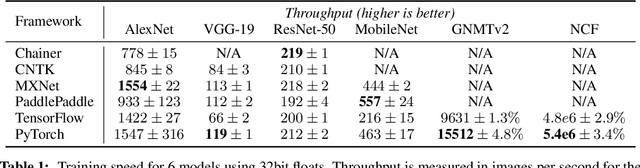

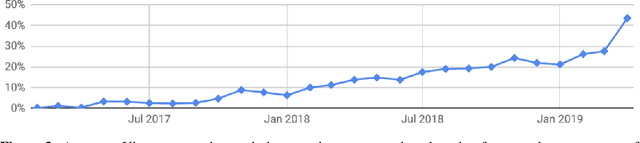
Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.