 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Approach to The Detection and Classification of Skin Diseases
Nov 21, 2024
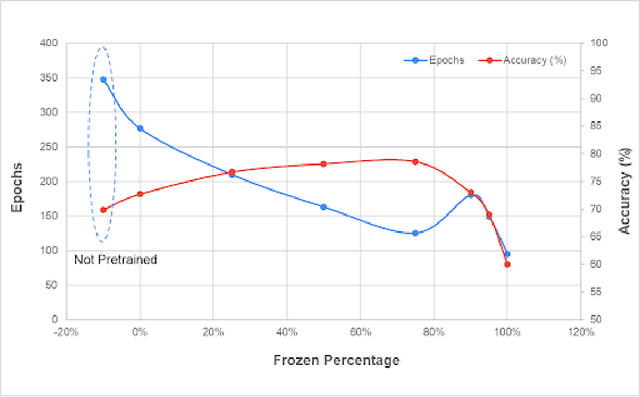
According to PBS, nearly one-third of Americans lack access to primary care services, and another forty percent delay going to avoid medical costs. As a result, many diseases are left undiagnosed and untreated, even if the disease shows many physical symptoms on the skin. With the rise of AI, self-diagnosis and improved disease recognition have become more promising than ever; in spite of that, existing methods suffer from a lack of large-scale patient databases and outdated methods of study, resulting in studies being limited to only a few diseases or modalities. This study incorporates readily available and easily accessible patient information via image and text for skin disease classification on a new dataset of 26 skin disease types that includes both skin disease images (37K) and associated patient narratives. Using this dataset, baselines for various image models were established that outperform existing methods. Initially, the Resnet-50 model was only able to achieve an accuracy of 70% but, after various optimization techniques, the accuracy was improved to 80%. In addition, this study proposes a novel fine-tuning strategy for sequence classification Large Language Models (LLMs), Chain of Options, which breaks down a complex reasoning task into intermediate steps at training time instead of inference. With Chain of Options and preliminary disease recommendations from the image model, this method achieves state of the art accuracy 91% in diagnosing patient skin disease given just an image of the afflicted area as well as a patient description of the symptoms (such as itchiness or dizziness). Through this research, an earlier diagnosis of skin diseases can occur, and clinicians can work with deep learning models to give a more accurate diagnosis, improving quality of life and saving lives.
Soft Expectation and Deep Maximization for Image Feature Detection
Apr 21, 2021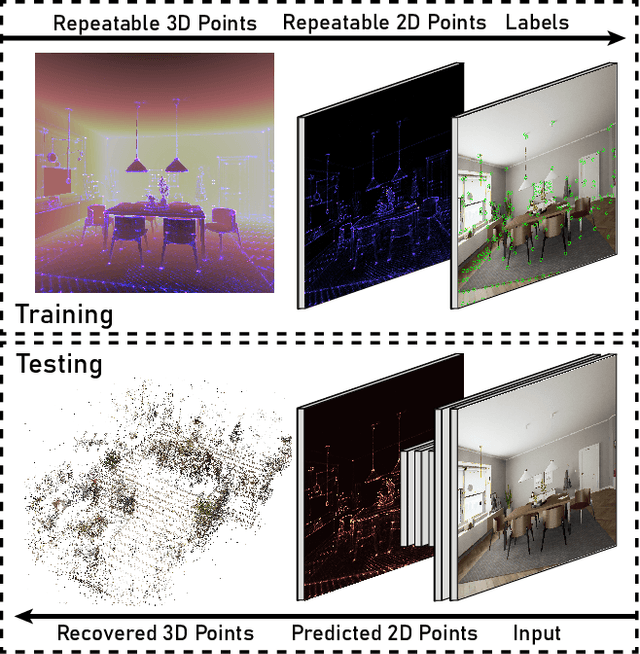
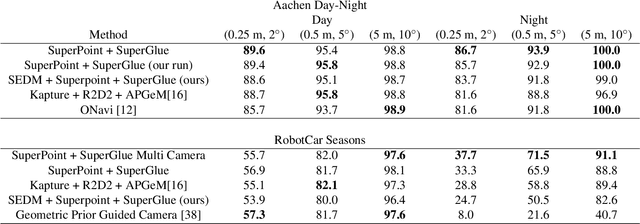
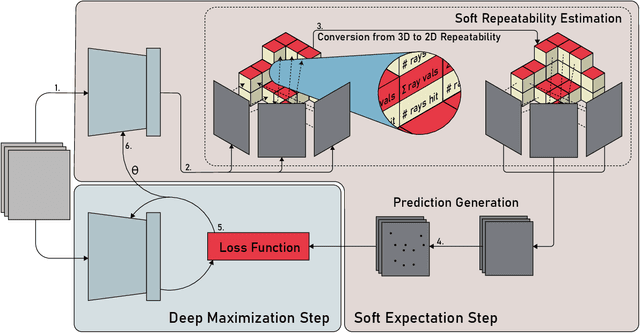
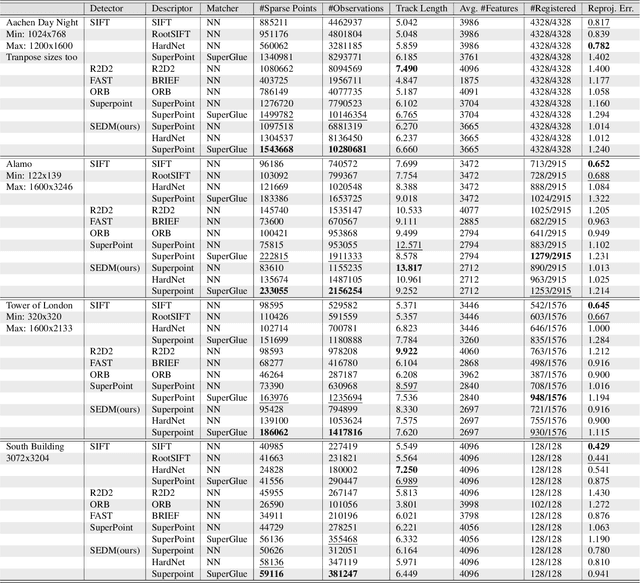
Central to the application of many multi-view geometry algorithms is the extraction of matching points between multiple viewpoints, enabling classical tasks such as camera pose estimation and 3D reconstruction. Over the decades, many approaches that characterize these points have been proposed based on hand-tuned appearance models and more recently data-driven learning methods. We propose SEDM, an iterative semi-supervised learning process that flips the question and first looks for repeatable 3D points, then trains a detector to localize them in image space. Our technique poses the problem as one of expectation maximization (EM), where the likelihood of the detector locating the 3D points is the objective function to be maximized. We utilize the geometry of the scene to refine the estimates of the location of these 3D points and produce a new pseudo ground truth during the expectation step, then train a detector to predict this pseudo ground truth in the maximization step. We apply our detector to standard benchmarks in visual localization, sparse 3D reconstruction, and mean matching accuracy. Our results show that this new model trained using SEDM is able to better localize the underlying 3D points in a scene, improving mean SfM quality by $-0.15\pm0.11$ mean reprojection error when compared to SuperPoint or $-0.38\pm0.23$ when compared to R2D2.
Training Deep Neural Networks to Detect Repeatable 2D Features Using Large Amounts of 3D World Capture Data
Dec 09, 2019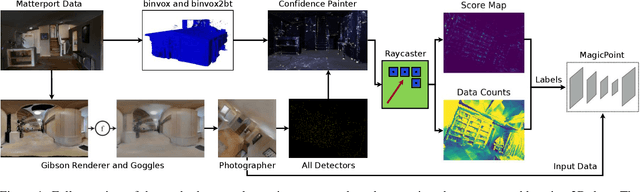



Image space feature detection is the act of selecting points or parts of an image that are easy to distinguish from the surrounding image region. By combining a repeatable point detection with a descriptor, parts of an image can be matched with one another, which is useful in applications like estimating pose from camera input or rectifying images. Recently, precise indoor tracking has started to become important for Augmented and Virtual reality as it is necessary to allow positioning of a headset in 3D space without the need for external tracking devices. Several modern feature detectors use homographies to simulate different viewpoints, not only to train feature detection and description, but test them as well. The problem is that, often, views of indoor spaces contain high depth disparity. This makes the approximation that a homography applied to an image represents a viewpoint change inaccurate. We claim that in order to train detectors to work well in indoor environments, they must be robust to this type of geometry, and repeatable under true viewpoint change instead of homographies. Here we focus on the problem of detecting repeatable feature locations under true viewpoint change. To this end, we generate labeled 2D images from a photo-realistic 3D dataset. These images are used for training a neural network based feature detector. We further present an algorithm for automatically generating labels of repeatable 2D features, and present a fast, easy to use test algorithm for evaluating a detector in an 3D environment.
Improving Usability, Efficiency, and Safety of UAV Path Planning through a Virtual Reality Interface
Apr 18, 2019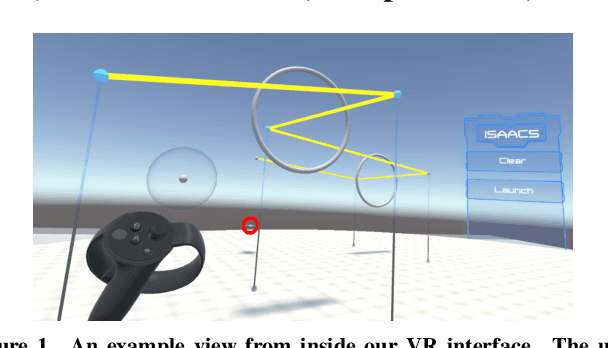
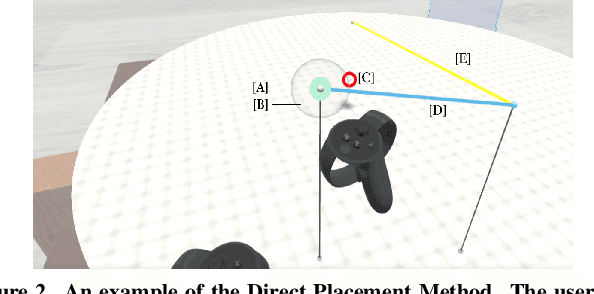
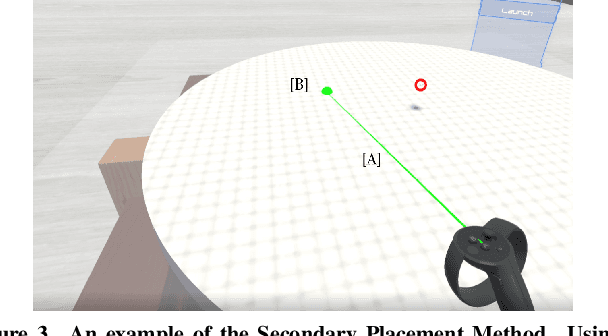
As the capability and complexity of UAVs continue to increase, the human-robot interface community has a responsibility to design better ways of specifying the complex 3D flight paths necessary for instructing them. Immersive interfaces, such as those afforded by virtual reality (VR), have several unique traits which may improve the user's ability to perceive and specify 3D information. These traits include stereoscopic depth cues which induce a sense of physical space as well as six degrees of freedom (DoF) natural head-pose and gesture interactions. This work introduces an open-source platform for 3D aerial path planning in VR and compares it to existing UAV piloting interfaces. Our study has found statistically significant improvements in safety and subjective usability over a manual control interface, while achieving a statistically significant efficiency improvement over a 2D touchscreen interface. The results illustrate that immersive interfaces provide a viable alternative to touchscreen interfaces for UAV path planning.
Loop Closure Detection with RGB-D Feature Pyramid Siamese Networks
Nov 25, 2018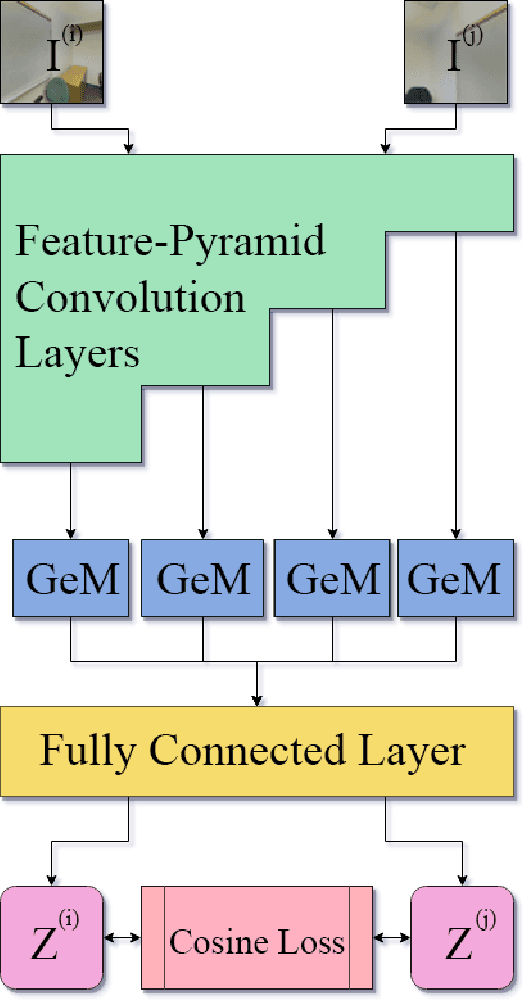



In visual Simultaneous Localization And Mapping (SLAM), detecting loop closures has been an important but difficult task. Currently, most solutions are based on the bag-of-words approach. Yet the possibility of deep neural network application to this task has not been fully explored due to the lack of appropriate architecture design and of sufficient training data. In this paper we demonstrate the applicability of deep neural networks by addressing both issues. Specifically we show that a feature pyramid Siamese neural network can achieve state-of-the-art performance on pairwise loop closure detection. The network is trained and tested on large-scale RGB-D datasets with a novel automatic loop closure labeling algorithm. Each image pair is labelled by how much the images overlap, allowing loop closure to be computed directly rather than by labor intensive manual labeling. We present an algorithm to adopt any large-scale generic RGB-D dataset for use in training deep loop-closure networks. We show for the first time that deep neural networks are capable of detecting loop closures, and we provide a method for generating large-scale datasets for use in evaluating and training loop closure detectors.
Sparsity and Robustness in Face Recognition
Nov 03, 2011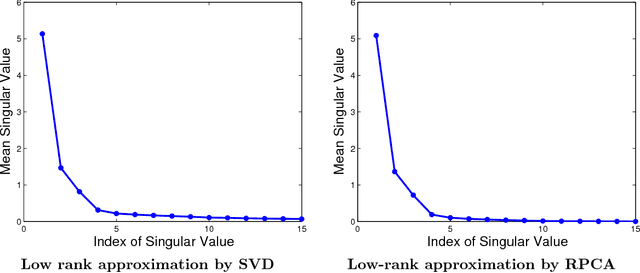
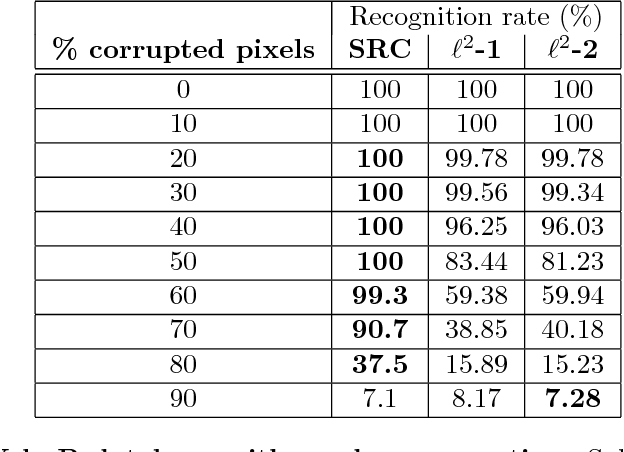
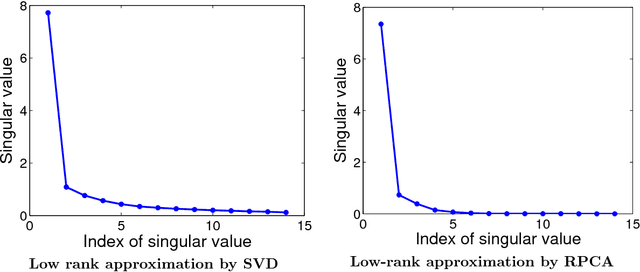
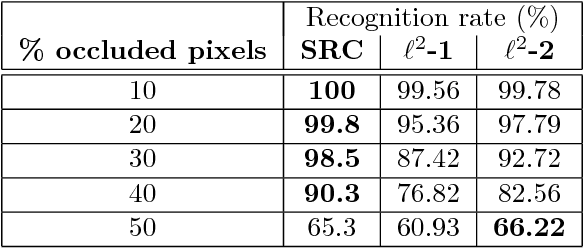
This report concerns the use of techniques for sparse signal representation and sparse error correction for automatic face recognition. Much of the recent interest in these techniques comes from the paper "Robust Face Recognition via Sparse Representation" by Wright et al. (2009), which showed how, under certain technical conditions, one could cast the face recognition problem as one of seeking a sparse representation of a given input face image in terms of a "dictionary" of training images and images of individual pixels. In this report, we have attempted to clarify some frequently encountered questions about this work and particularly, on the validity of using sparse representation techniques for face recognition.