 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Expectation and Deep Maximization for Image Feature Detection
Apr 21, 2021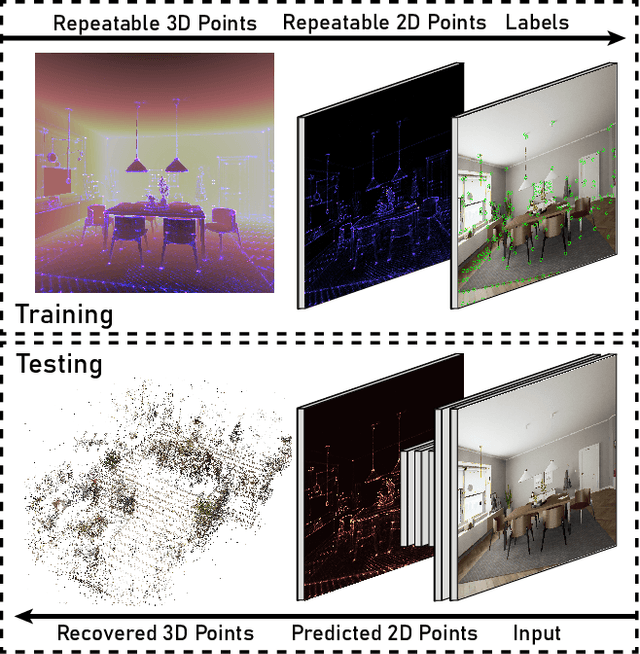
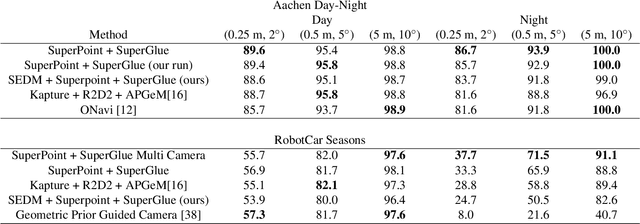
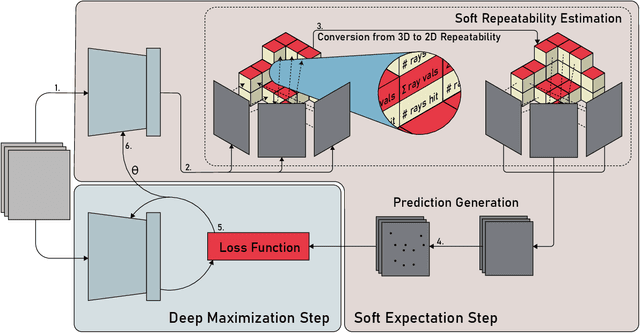
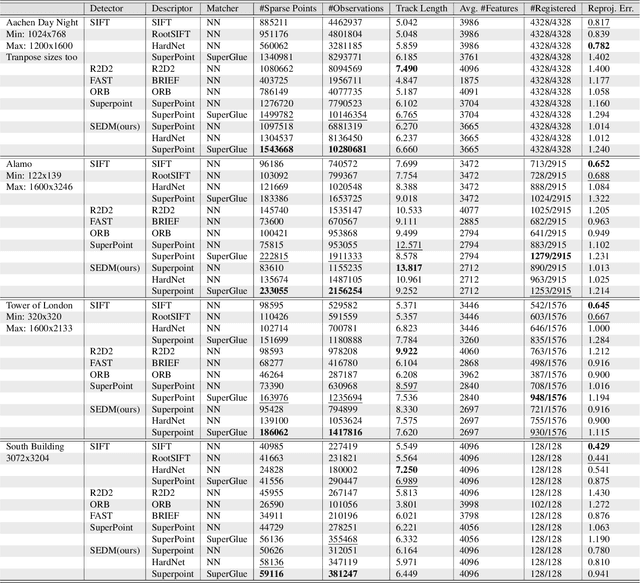
Central to the application of many multi-view geometry algorithms is the extraction of matching points between multiple viewpoints, enabling classical tasks such as camera pose estimation and 3D reconstruction. Over the decades, many approaches that characterize these points have been proposed based on hand-tuned appearance models and more recently data-driven learning methods. We propose SEDM, an iterative semi-supervised learning process that flips the question and first looks for repeatable 3D points, then trains a detector to localize them in image space. Our technique poses the problem as one of expectation maximization (EM), where the likelihood of the detector locating the 3D points is the objective function to be maximized. We utilize the geometry of the scene to refine the estimates of the location of these 3D points and produce a new pseudo ground truth during the expectation step, then train a detector to predict this pseudo ground truth in the maximization step. We apply our detector to standard benchmarks in visual localization, sparse 3D reconstruction, and mean matching accuracy. Our results show that this new model trained using SEDM is able to better localize the underlying 3D points in a scene, improving mean SfM quality by $-0.15\pm0.11$ mean reprojection error when compared to SuperPoint or $-0.38\pm0.23$ when compared to R2D2.