 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVER: Exact Volumetric Ellipsoid Rendering for Real-time View Synthesis
Oct 02, 2024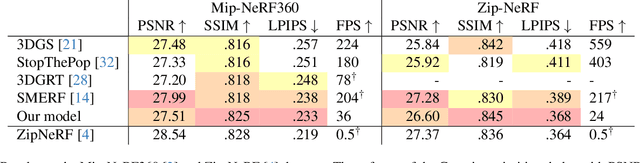
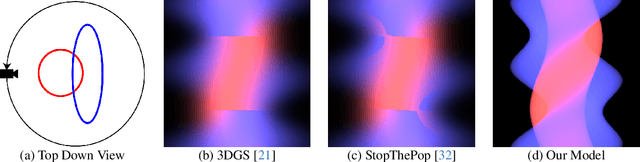
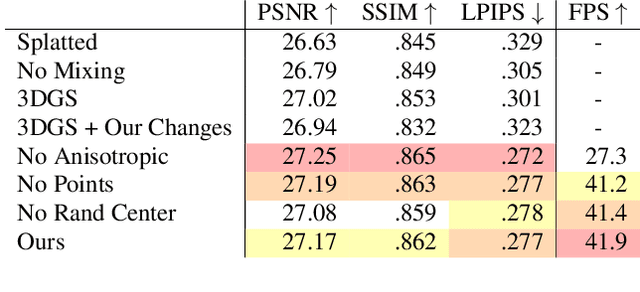
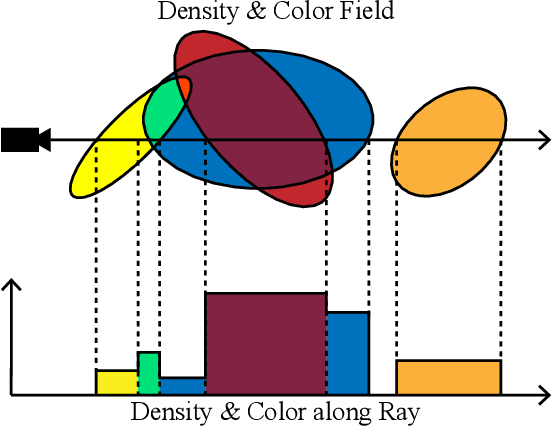
We present Exact Volumetric Ellipsoid Rendering (EVER), a method for real-time differentiable emission-only volume rendering. Unlike recent rasterization based approach by 3D Gaussian Splatting (3DGS), our primitive based representation allows for exact volume rendering, rather than alpha compositing 3D Gaussian billboards. As such, unlike 3DGS our formulation does not suffer from popping artifacts and view dependent density, but still achieves frame rates of $\sim\!30$ FPS at 720p on an NVIDIA RTX4090. Since our approach is built upon ray tracing it enables effects such as defocus blur and camera distortion (e.g. such as from fisheye cameras), which are difficult to achieve by rasterization. We show that our method is more accurate with fewer blending issues than 3DGS and follow-up work on view-consistent rendering, especially on the challenging large-scale scenes from the Zip-NeRF dataset where it achieves sharpest results among real-time techniques.
Neural Microfacet Fields for Inverse Rendering
Mar 31, 2023



We present Neural Microfacet Fields, a method for recovering materials, geometry, and environment illumination from images of a scene. Our method uses a microfacet reflectance model within a volumetric setting by treating each sample along the ray as a (potentially non-opaque) surface. Using surface-based Monte Carlo rendering in a volumetric setting enables our method to perform inverse rendering efficiently by combining decades of research in surface-based light transport with recent advances in volume rendering for view synthesis. Our approach outperforms prior work in inverse rendering, capturing high fidelity geometry and high frequency illumination details; its novel view synthesis results are on par with state-of-the-art methods that do not recover illumination or materials.
Soft Expectation and Deep Maximization for Image Feature Detection
Apr 21, 2021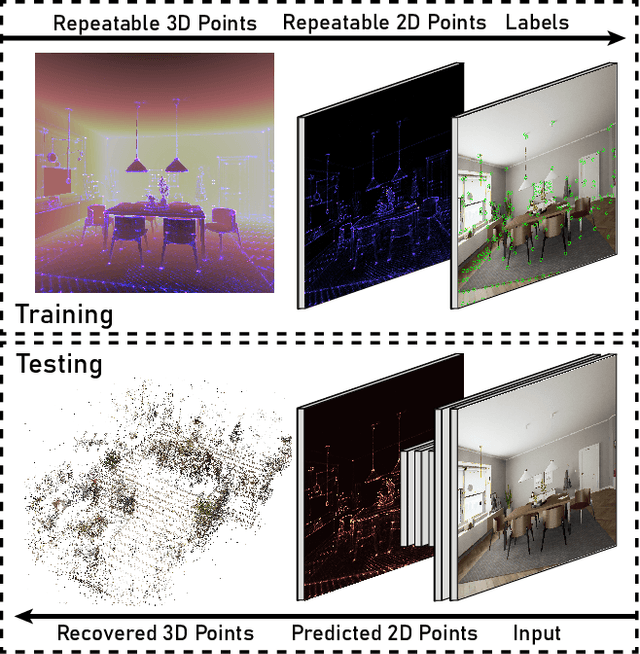
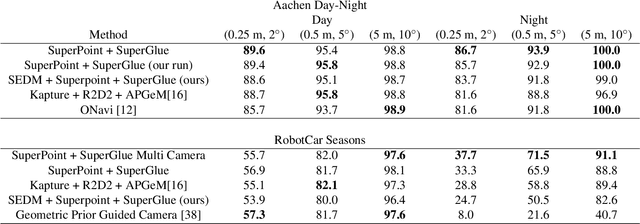
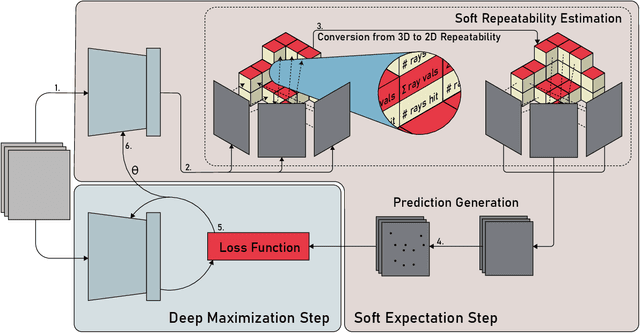
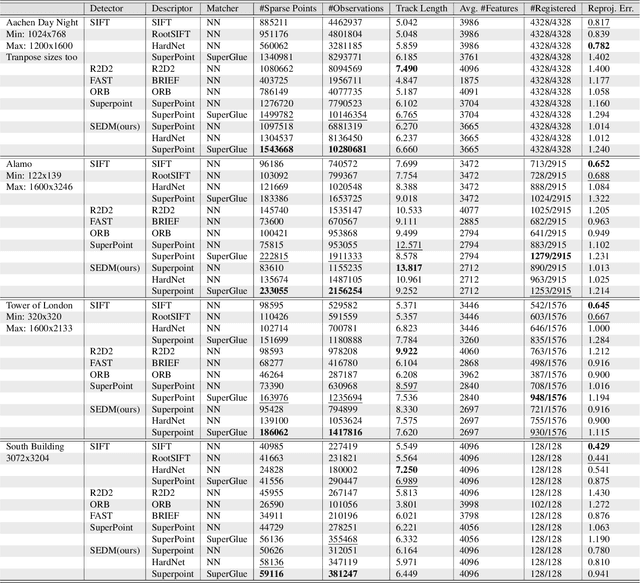
Central to the application of many multi-view geometry algorithms is the extraction of matching points between multiple viewpoints, enabling classical tasks such as camera pose estimation and 3D reconstruction. Over the decades, many approaches that characterize these points have been proposed based on hand-tuned appearance models and more recently data-driven learning methods. We propose SEDM, an iterative semi-supervised learning process that flips the question and first looks for repeatable 3D points, then trains a detector to localize them in image space. Our technique poses the problem as one of expectation maximization (EM), where the likelihood of the detector locating the 3D points is the objective function to be maximized. We utilize the geometry of the scene to refine the estimates of the location of these 3D points and produce a new pseudo ground truth during the expectation step, then train a detector to predict this pseudo ground truth in the maximization step. We apply our detector to standard benchmarks in visual localization, sparse 3D reconstruction, and mean matching accuracy. Our results show that this new model trained using SEDM is able to better localize the underlying 3D points in a scene, improving mean SfM quality by $-0.15\pm0.11$ mean reprojection error when compared to SuperPoint or $-0.38\pm0.23$ when compared to R2D2.
Training Deep Neural Networks to Detect Repeatable 2D Features Using Large Amounts of 3D World Capture Data
Dec 09, 2019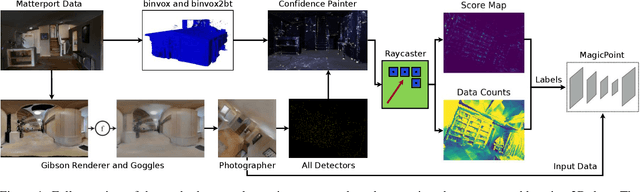



Image space feature detection is the act of selecting points or parts of an image that are easy to distinguish from the surrounding image region. By combining a repeatable point detection with a descriptor, parts of an image can be matched with one another, which is useful in applications like estimating pose from camera input or rectifying images. Recently, precise indoor tracking has started to become important for Augmented and Virtual reality as it is necessary to allow positioning of a headset in 3D space without the need for external tracking devices. Several modern feature detectors use homographies to simulate different viewpoints, not only to train feature detection and description, but test them as well. The problem is that, often, views of indoor spaces contain high depth disparity. This makes the approximation that a homography applied to an image represents a viewpoint change inaccurate. We claim that in order to train detectors to work well in indoor environments, they must be robust to this type of geometry, and repeatable under true viewpoint change instead of homographies. Here we focus on the problem of detecting repeatable feature locations under true viewpoint change. To this end, we generate labeled 2D images from a photo-realistic 3D dataset. These images are used for training a neural network based feature detector. We further present an algorithm for automatically generating labels of repeatable 2D features, and present a fast, easy to use test algorithm for evaluating a detector in an 3D environment.
Loop Closure Detection with RGB-D Feature Pyramid Siamese Networks
Nov 25, 2018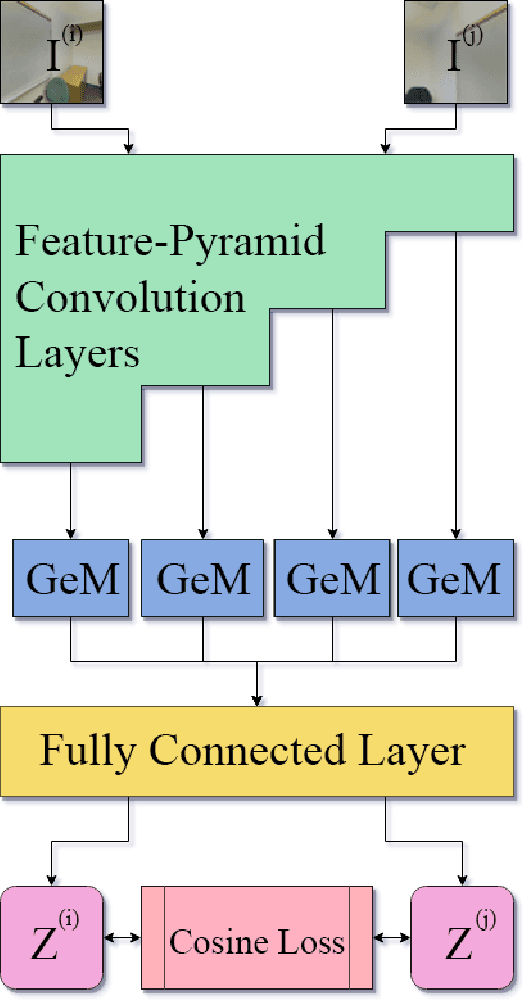



In visual Simultaneous Localization And Mapping (SLAM), detecting loop closures has been an important but difficult task. Currently, most solutions are based on the bag-of-words approach. Yet the possibility of deep neural network application to this task has not been fully explored due to the lack of appropriate architecture design and of sufficient training data. In this paper we demonstrate the applicability of deep neural networks by addressing both issues. Specifically we show that a feature pyramid Siamese neural network can achieve state-of-the-art performance on pairwise loop closure detection. The network is trained and tested on large-scale RGB-D datasets with a novel automatic loop closure labeling algorithm. Each image pair is labelled by how much the images overlap, allowing loop closure to be computed directly rather than by labor intensive manual labeling. We present an algorithm to adopt any large-scale generic RGB-D dataset for use in training deep loop-closure networks. We show for the first time that deep neural networks are capable of detecting loop closures, and we provide a method for generating large-scale datasets for use in evaluating and training loop closure detectors.