 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFus3D: Decoding Consolidated 3D Geometry from Feed-forward Geometry Transformer Latents
Mar 26, 2026We propose a feed-forward method for dense Signed Distance Field (SDF) regression from unstructured image collections in less than three seconds, without camera calibration or post-hoc fusion. Our key insight is that the intermediate feature space of pretrained multi-view feed-forward geometry transformers already encodes a powerful joint world representation; yet, existing pipelines discard it, routing features through per-view prediction heads before assembling 3D geometry post-hoc, which discards valuable completeness information and accumulates inaccuracies. We instead perform 3D extraction directly from geometry transformer features via learned volumetric extraction: voxelized canonical embeddings that progressively absorb multi-view geometry information through interleaved cross- and self-attention into a structured volumetric latent grid. A simple convolutional decoder then maps this grid to a dense SDF. We additionally propose a scalable, validity-aware supervision scheme directly using SDFs derived from depth maps or 3D assets, tackling practical issues like non-watertight meshes. Our approach yields complete and well-defined distance values across sparse- and dense-view settings and demonstrates geometrically plausible completions. Code and further material can be found at https://lorafib.github.io/fus3d.
StochasticSplats: Stochastic Rasterization for Sorting-Free 3D Gaussian Splatting
Mar 31, 20253D Gaussian splatting (3DGS) is a popular radiance field method, with many application-specific extensions. Most variants rely on the same core algorithm: depth-sorting of Gaussian splats then rasterizing in primitive order. This ensures correct alpha compositing, but can cause rendering artifacts due to built-in approximations. Moreover, for a fixed representation, sorted rendering offers little control over render cost and visual fidelity. For example, and counter-intuitively, rendering a lower-resolution image is not necessarily faster. In this work, we address the above limitations by combining 3D Gaussian splatting with stochastic rasterization. Concretely, we leverage an unbiased Monte Carlo estimator of the volume rendering equation. This removes the need for sorting, and allows for accurate 3D blending of overlapping Gaussians. The number of Monte Carlo samples further imbues 3DGS with a way to trade off computation time and quality. We implement our method using OpenGL shaders, enabling efficient rendering on modern GPU hardware. At a reasonable visual quality, our method renders more than four times faster than sorted rasterization.
Does 3D Gaussian Splatting Need Accurate Volumetric Rendering?
Feb 26, 2025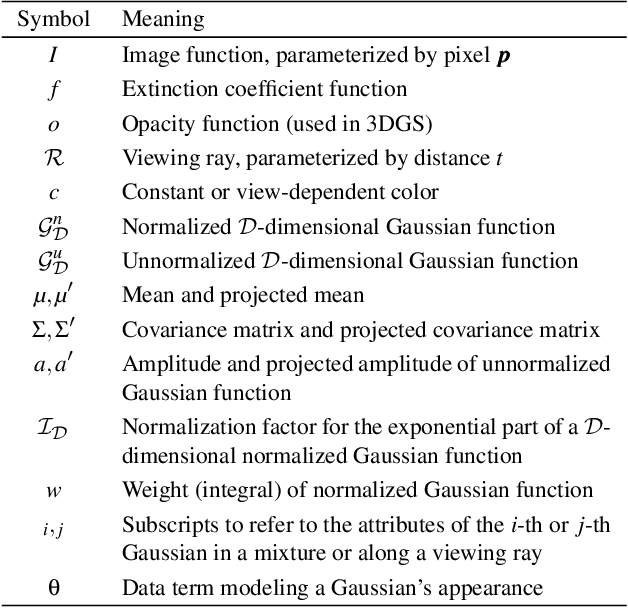
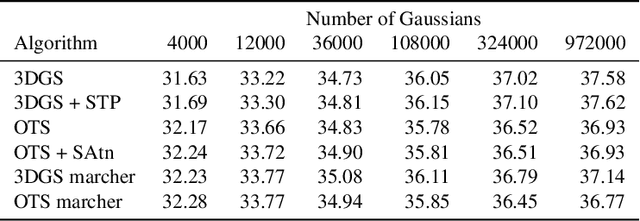
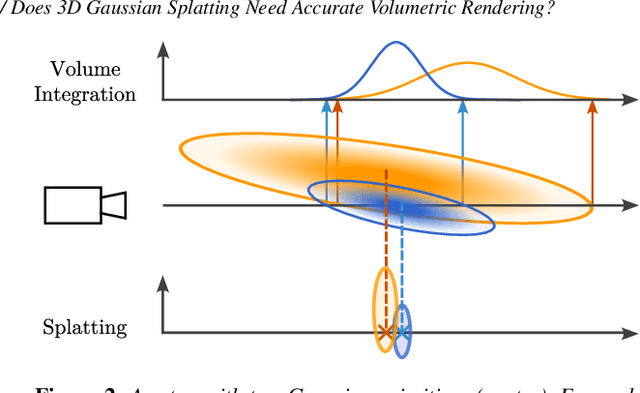
Since its introduction, 3D Gaussian Splatting (3DGS) has become an important reference method for learning 3D representations of a captured scene, allowing real-time novel-view synthesis with high visual quality and fast training times. Neural Radiance Fields (NeRFs), which preceded 3DGS, are based on a principled ray-marching approach for volumetric rendering. In contrast, while sharing a similar image formation model with NeRF, 3DGS uses a hybrid rendering solution that builds on the strengths of volume rendering and primitive rasterization. A crucial benefit of 3DGS is its performance, achieved through a set of approximations, in many cases with respect to volumetric rendering theory. A naturally arising question is whether replacing these approximations with more principled volumetric rendering solutions can improve the quality of 3DGS. In this paper, we present an in-depth analysis of the various approximations and assumptions used by the original 3DGS solution. We demonstrate that, while more accurate volumetric rendering can help for low numbers of primitives, the power of efficient optimization and the large number of Gaussians allows 3DGS to outperform volumetric rendering despite its approximations.
Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
Jan 12, 2025We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle two major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to state-of-the-art monocular methods that require thousands of real training images, SynShot significantly improves novel view and expression synthesis.
EVER: Exact Volumetric Ellipsoid Rendering for Real-time View Synthesis
Oct 02, 2024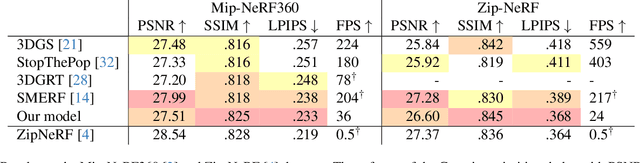
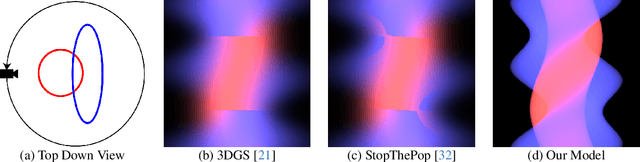
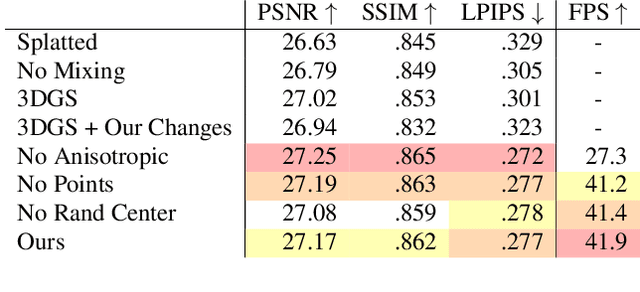
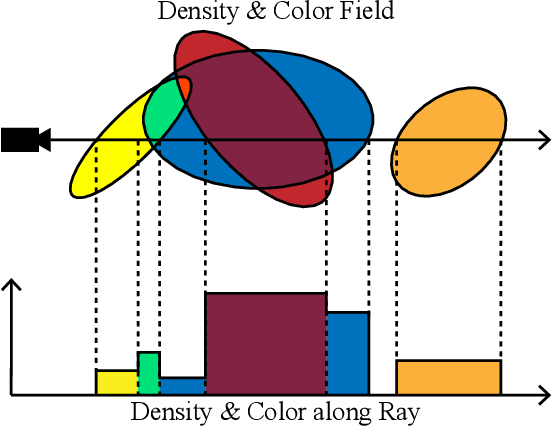
We present Exact Volumetric Ellipsoid Rendering (EVER), a method for real-time differentiable emission-only volume rendering. Unlike recent rasterization based approach by 3D Gaussian Splatting (3DGS), our primitive based representation allows for exact volume rendering, rather than alpha compositing 3D Gaussian billboards. As such, unlike 3DGS our formulation does not suffer from popping artifacts and view dependent density, but still achieves frame rates of $\sim\!30$ FPS at 720p on an NVIDIA RTX4090. Since our approach is built upon ray tracing it enables effects such as defocus blur and camera distortion (e.g. such as from fisheye cameras), which are difficult to achieve by rasterization. We show that our method is more accurate with fewer blending issues than 3DGS and follow-up work on view-consistent rendering, especially on the challenging large-scale scenes from the Zip-NeRF dataset where it achieves sharpest results among real-time techniques.
SpotlessSplats: Ignoring Distractors in 3D Gaussian Splatting
Jun 28, 2024
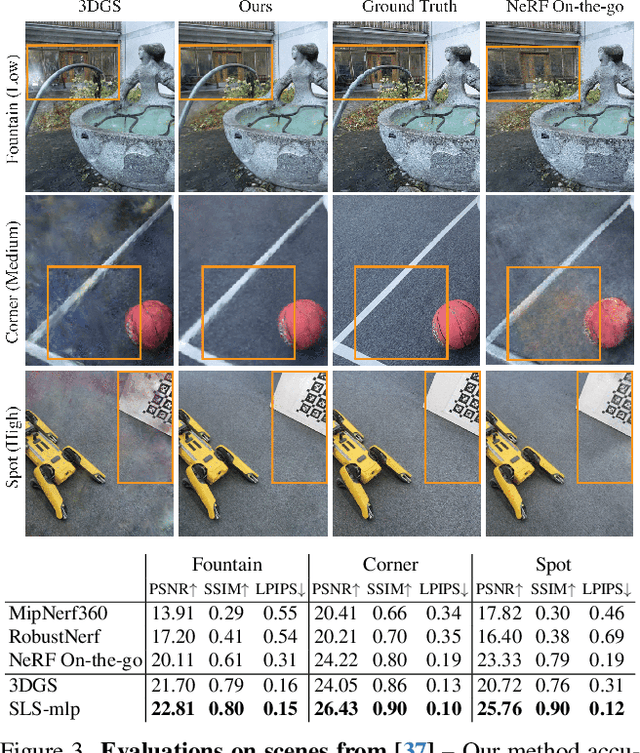

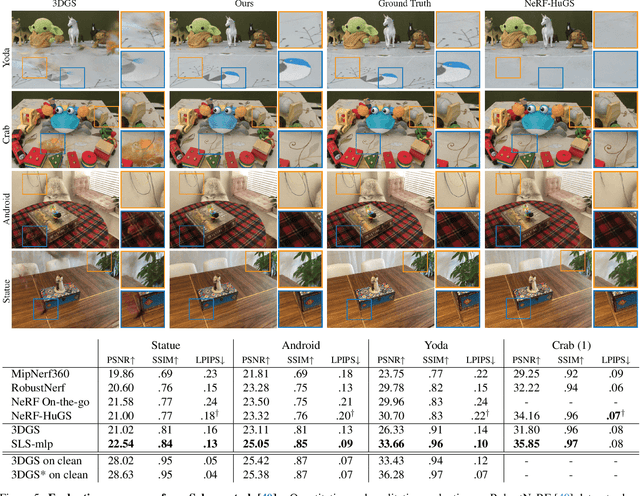
3D Gaussian Splatting (3DGS) is a promising technique for 3D reconstruction, offering efficient training and rendering speeds, making it suitable for real-time applications.However, current methods require highly controlled environments (no moving people or wind-blown elements, and consistent lighting) to meet the inter-view consistency assumption of 3DGS. This makes reconstruction of real-world captures problematic. We present SpotlessSplats, an approach that leverages pre-trained and general-purpose features coupled with robust optimization to effectively ignore transient distractors. Our method achieves state-of-the-art reconstruction quality both visually and quantitatively, on casual captures.