 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysHead: Simulation-Ready Gaussian Head Avatars
Apr 07, 2026Realistic digital avatars require expressive and dynamic hair motion; however, most existing head avatar methods assume rigid hair movement. These methods often fail to disentangle hair from the head, representing it as a simple outer shell and failing to capture its natural volumetric behavior. In this paper, we address these limitations by introducing PhysHead, a hybrid representation for animatable head avatars with realistic hair dynamics learned from multi-view video. At the core is a 3D Gaussian-based layered representation of the head. Our approach combines a 3D parametric mesh for the head with strand-based hair, which can be directly simulated using physics engines. For the appearance model, we employ Gaussian primitives attached to both the head mesh and hair segments. This representation enables the creation of photorealistic head avatars with dynamic hair behavior, such as wind-blown motion, overcoming the constraints of rigid hair in existing methods. However, these animation capabilities also require new training schemes. In particular, we propose the use of VLM-based models to generate appearance of regions that are occluded in the dynamic training sequences. In quantitative and qualitative studies, we demonstrate the capabilities of the proposed model and compare it with existing baselines. We show that our method can synthesize physically plausible hair motion besides expression and camera control.
Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
Jan 12, 2025We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle two major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to state-of-the-art monocular methods that require thousands of real training images, SynShot significantly improves novel view and expression synthesis.
Gaussian Eigen Models for Human Heads
Jul 05, 2024

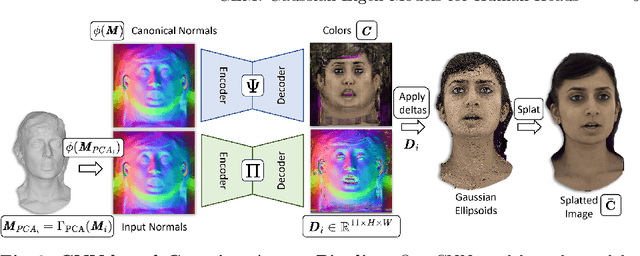
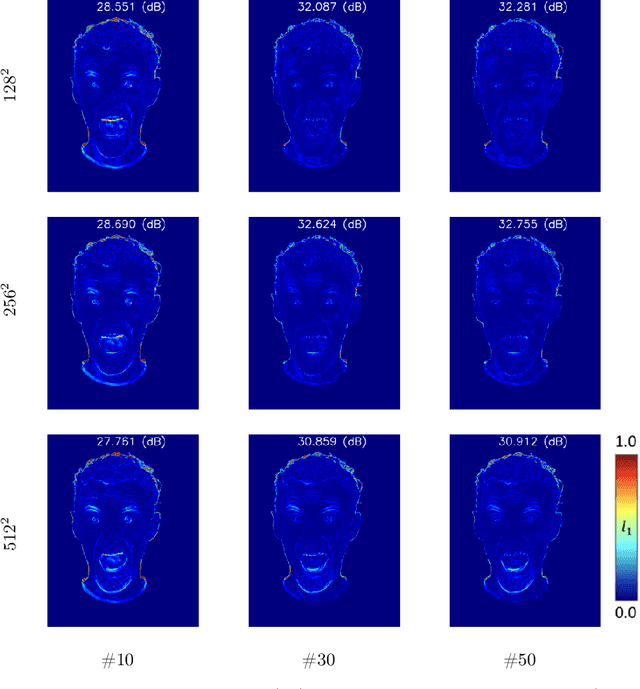
We present personalized Gaussian Eigen Models (GEMs) for human heads, a novel method that compresses dynamic 3D Gaussians into low-dimensional linear spaces. Our approach is inspired by the seminal work of Blanz and Vetter, where a mesh-based 3D morphable model (3DMM) is constructed from registered meshes. Based on dynamic 3D Gaussians, we create a lower-dimensional representation of primitives that applies to most 3DGS head avatars. Specifically, we propose a universal method to distill the appearance of a mesh-controlled UNet Gaussian avatar using an ensemble of linear eigenbasis. We replace heavy CNN-based architectures with a single linear layer improving speed and enabling a range of real-time downstream applications. To create a particular facial expression, one simply needs to perform a dot product between the eigen coefficients and the distilled basis. This efficient method removes the requirement for an input mesh during testing, enhancing simplicity and speed in expression generation. This process is highly efficient and supports real-time rendering on everyday devices, leveraging the effectiveness of standard Gaussian Splatting. In addition, we demonstrate how the GEM can be controlled using a ResNet-based regression architecture. We show and compare self-reenactment and cross-person reenactment to state-of-the-art 3D avatar methods, demonstrating higher quality and better control. A real-time demo showcases the applicability of the GEM representation.
GAN-Avatar: Controllable Personalized GAN-based Human Head Avatar
Nov 22, 2023

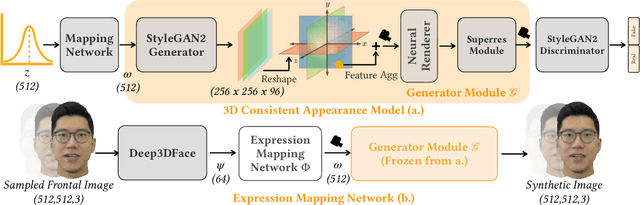
Digital humans and, especially, 3D facial avatars have raised a lot of attention in the past years, as they are the backbone of several applications like immersive telepresence in AR or VR. Despite the progress, facial avatars reconstructed from commodity hardware are incomplete and miss out on parts of the side and back of the head, severely limiting the usability of the avatar. This limitation in prior work stems from their requirement of face tracking, which fails for profile and back views. To address this issue, we propose to learn person-specific animatable avatars from images without assuming to have access to precise facial expression tracking. At the core of our method, we leverage a 3D-aware generative model that is trained to reproduce the distribution of facial expressions from the training data. To train this appearance model, we only assume to have a collection of 2D images with the corresponding camera parameters. For controlling the model, we learn a mapping from 3DMM facial expression parameters to the latent space of the generative model. This mapping can be learned by sampling the latent space of the appearance model and reconstructing the facial parameters from a normalized frontal view, where facial expression estimation performs well. With this scheme, we decouple 3D appearance reconstruction and animation control to achieve high fidelity in image synthesis. In a series of experiments, we compare our proposed technique to state-of-the-art monocular methods and show superior quality while not requiring expression tracking of the training data.
Drivable 3D Gaussian Avatars
Nov 14, 2023We present Drivable 3D Gaussian Avatars (D3GA), the first 3D controllable model for human bodies rendered with Gaussian splats. Current photorealistic drivable avatars require either accurate 3D registrations during training, dense input images during testing, or both. The ones based on neural radiance fields also tend to be prohibitively slow for telepresence applications. This work uses the recently presented 3D Gaussian Splatting (3DGS) technique to render realistic humans at real-time framerates, using dense calibrated multi-view videos as input. To deform those primitives, we depart from the commonly used point deformation method of linear blend skinning (LBS) and use a classic volumetric deformation method: cage deformations. Given their smaller size, we drive these deformations with joint angles and keypoints, which are more suitable for communication applications. Our experiments on nine subjects with varied body shapes, clothes, and motions obtain higher-quality results than state-of-the-art methods when using the same training and test data.
Instant Volumetric Head Avatars
Nov 22, 2022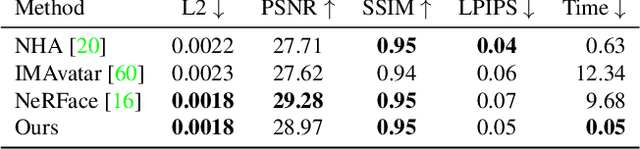
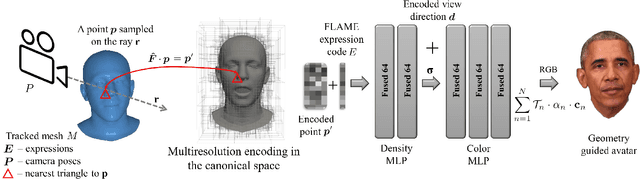

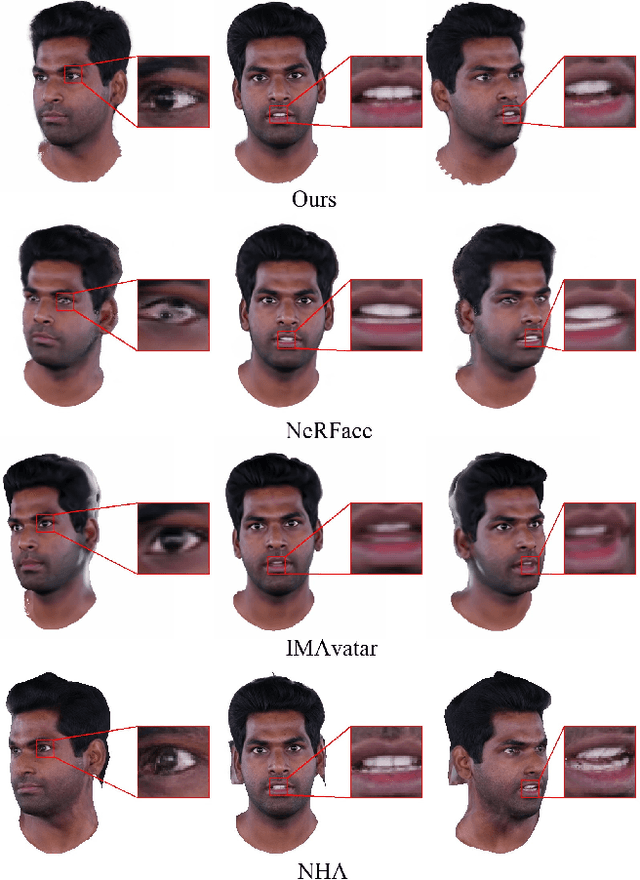
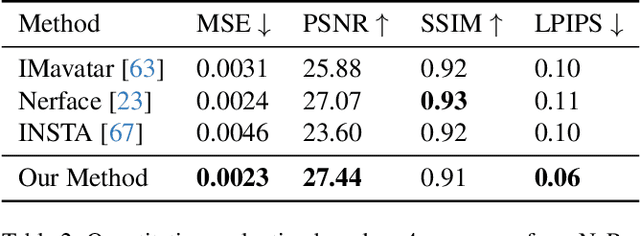
We present Instant Volumetric Head Avatars (INSTA), a novel approach for reconstructing photo-realistic digital avatars instantaneously. INSTA models a dynamic neural radiance field based on neural graphics primitives embedded around a parametric face model. Our pipeline is trained on a single monocular RGB portrait video that observes the subject under different expressions and views. While state-of-the-art methods take up to several days to train an avatar, our method can reconstruct a digital avatar in less than 10 minutes on modern GPU hardware, which is orders of magnitude faster than previous solutions. In addition, it allows for the interactive rendering of novel poses and expressions. By leveraging the geometry prior of the underlying parametric face model, we demonstrate that INSTA extrapolates to unseen poses. In quantitative and qualitative studies on various subjects, INSTA outperforms state-of-the-art methods regarding rendering quality and training time.
Towards Metrical Reconstruction of Human Faces
Apr 13, 2022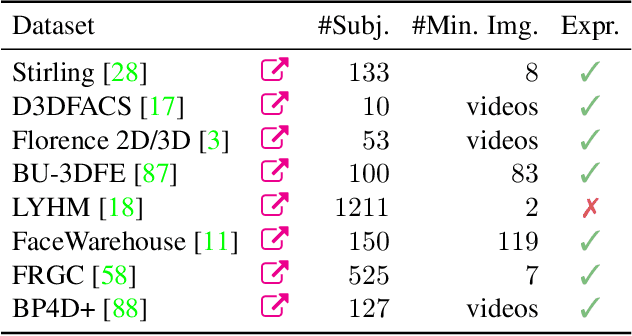
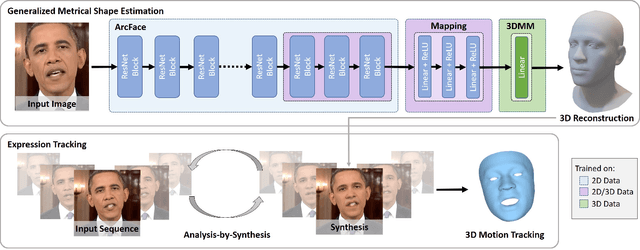
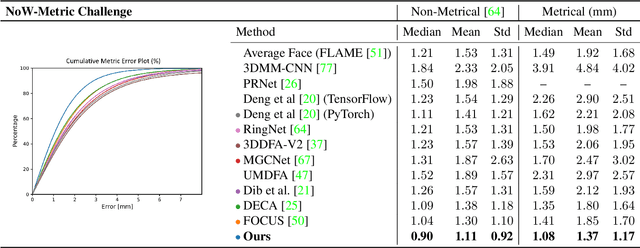
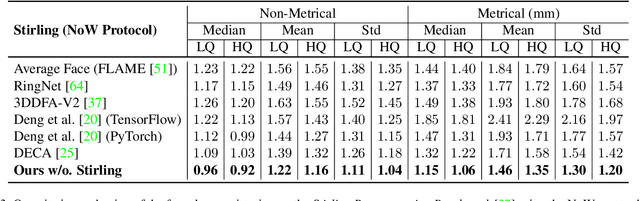
Face reconstruction and tracking is a building block of numerous applications in AR/VR, human-machine interaction, as well as medical applications. Most of these applications rely on a metrically correct prediction of the shape, especially, when the reconstructed subject is put into a metrical context (i.e., when there is a reference object of known size). A metrical reconstruction is also needed for any application that measures distances and dimensions of the subject (e.g., to virtually fit a glasses frame). State-of-the-art methods for face reconstruction from a single image are trained on large 2D image datasets in a self-supervised fashion. However, due to the nature of a perspective projection they are not able to reconstruct the actual face dimensions, and even predicting the average human face outperforms some of these methods in a metrical sense. To learn the actual shape of a face, we argue for a supervised training scheme. Since there exists no large-scale 3D dataset for this task, we annotated and unified small- and medium-scale databases. The resulting unified dataset is still a medium-scale dataset with more than 2k identities and training purely on it would lead to overfitting. To this end, we take advantage of a face recognition network pretrained on a large-scale 2D image dataset, which provides distinct features for different faces and is robust to expression, illumination, and camera changes. Using these features, we train our face shape estimator in a supervised fashion, inheriting the robustness and generalization of the face recognition network. Our method, which we call MICA (MetrIC fAce), outperforms the state-of-the-art reconstruction methods by a large margin, both on current non-metric benchmarks as well as on our metric benchmarks (15% and 24% lower average error on NoW, respectively).