 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoRelight: Learning Joint Geometrical Relighting and Reconstruction with Flexible Multi-Modal Diffusion Transformers
Apr 22, 2026Relighting a person from a single photo is an attractive but ill-posed task, as a 2D image ambiguously entangles 3D geometry, intrinsic appearance, and illumination. Current methods either use sequential pipelines that suffer from error accumulation, or they do not explicitly leverage 3D geometry during relighting, which limits physical consistency. Since relighting and estimation of 3D geometry are mutually beneficial tasks, we propose a unified Multi-Modal Diffusion Transformer (DiT) that jointly solves for both: GeoRelight. We make this possible through two key technical contributions: isotropic NDC-Orthographic Depth (iNOD), a distortion-free 3D representation compatible with latent diffusion models; and a strategic mixed-data training method that combines synthetic and auto-labeled real data. By solving geometry and relighting jointly, GeoRelight achieves better performance than both sequential models and previous systems that ignored geometry.
Implementing Metric Temporal Answer Set Programming
Jan 28, 2026We develop a computational approach to Metric Answer Set Programming (ASP) to allow for expressing quantitative temporal constraints, like durations and deadlines. A central challenge is to maintain scalability when dealing with fine-grained timing constraints, which can significantly exacerbate ASP's grounding bottleneck. To address this issue, we leverage extensions of ASP with difference constraints, a simplified form of linear constraints, to handle time-related aspects externally. Our approach effectively decouples metric ASP from the granularity of time, resulting in a solution that is unaffected by time precision.
MHR: Momentum Human Rig
Nov 19, 2025We present MHR, a parametric human body model that combines the decoupled skeleton/shape paradigm of ATLAS with a flexible, modern rig and pose corrective system inspired by the Momentum library. Our model enables expressive, anatomically plausible human animation, supporting non-linear pose correctives, and is designed for robust integration in AR/VR and graphics pipelines.
Vision Foundation Models in Agriculture: Toward Domain-Specific Adaptation for Weed Herbicide Trials Assessment
Nov 06, 2025Herbicide field trials require accurate identification of plant species and assessment of herbicide-induced damage across diverse environments. While general-purpose vision foundation models have shown promising results in complex visual domains, their performance can be limited in agriculture, where fine-grained distinctions between species and damage types are critical. In this work, we adapt a general-purpose vision foundation model to herbicide trial characterization. Trained using a self-supervised learning approach on a large, curated agricultural dataset, the model learns rich and transferable representations optimized for herbicide trials images. Our domain-specific model significantly outperforms the best general-purpose foundation model in both species identification (F1 score improvement from 0.91 to 0.94) and damage classification (from 0.26 to 0.33). Under unseen conditions (new locations and other time), it achieves even greater gains (species identification from 0.56 to 0.66; damage classification from 0.17 to 0.27). In domain-shift scenarios, such as drone imagery, it maintains strong performance (species classification from 0.49 to 0.60). Additionally, we show that domain-specific pretraining enhances segmentation accuracy, particularly in low-annotation regimes. An annotation-efficiency analysis reveals that, under unseen conditions, the domain-specific model achieves 5.4% higher F1 score than the general-purpose model, while using 80% fewer labeled samples. These results demonstrate the generalization capabilities of domain-specific foundation models and their potential to significantly reduce manual annotation efforts, offering a scalable and automated solution for herbicide trial analysis.
From Field to Drone: Domain Drift Tolerant Automated Multi-Species and Damage Plant Semantic Segmentation for Herbicide Trials
Aug 11, 2025Field trials are vital in herbicide research and development to assess effects on crops and weeds under varied conditions. Traditionally, evaluations rely on manual visual assessments, which are time-consuming, labor-intensive, and subjective. Automating species and damage identification is challenging due to subtle visual differences, but it can greatly enhance efficiency and consistency. We present an improved segmentation model combining a general-purpose self-supervised visual model with hierarchical inference based on botanical taxonomy. Trained on a multi-year dataset (2018-2020) from Germany and Spain using digital and mobile cameras, the model was tested on digital camera data (year 2023) and drone imagery from the United States, Germany, and Spain (year 2024) to evaluate robustness under domain shift. This cross-device evaluation marks a key step in assessing generalization across platforms of the model. Our model significantly improved species identification (F1-score: 0.52 to 0.85, R-squared: 0.75 to 0.98) and damage classification (F1-score: 0.28 to 0.44, R-squared: 0.71 to 0.87) over prior methods. Under domain shift (drone images), it maintained strong performance with moderate degradation (species: F1-score 0.60, R-squared 0.80; damage: F1-score 0.41, R-squared 0.62), where earlier models failed. These results confirm the model's robustness and real-world applicability. It is now deployed in BASF's phenotyping pipeline, enabling large-scale, automated crop and weed monitoring across diverse geographies.
3DGH: 3D Head Generation with Composable Hair and Face
Jun 25, 2025We present 3DGH, an unconditional generative model for 3D human heads with composable hair and face components. Unlike previous work that entangles the modeling of hair and face, we propose to separate them using a novel data representation with template-based 3D Gaussian Splatting, in which deformable hair geometry is introduced to capture the geometric variations across different hairstyles. Based on this data representation, we design a 3D GAN-based architecture with dual generators and employ a cross-attention mechanism to model the inherent correlation between hair and face. The model is trained on synthetic renderings using carefully designed objectives to stabilize training and facilitate hair-face separation. We conduct extensive experiments to validate the design choice of 3DGH, and evaluate it both qualitatively and quantitatively by comparing with several state-of-the-art 3D GAN methods, demonstrating its effectiveness in unconditional full-head image synthesis and composable 3D hairstyle editing. More details will be available on our project page: https://c-he.github.io/projects/3dgh/.
Compiling Metric Temporal Answer Set Programming
Jun 09, 2025We develop a computational approach to Metric Answer Set Programming (ASP) to allow for expressing quantitative temporal constrains, like durations and deadlines. A central challenge is to maintain scalability when dealing with fine-grained timing constraints, which can significantly exacerbate ASP's grounding bottleneck. To address this issue, we leverage extensions of ASP with difference constraints, a simplified form of linear constraints, to handle time-related aspects externally. Our approach effectively decouples metric ASP from the granularity of time, resulting in a solution that is unaffected by time precision.
FRESA:Feedforward Reconstruction of Personalized Skinned Avatars from Few Images
Mar 24, 2025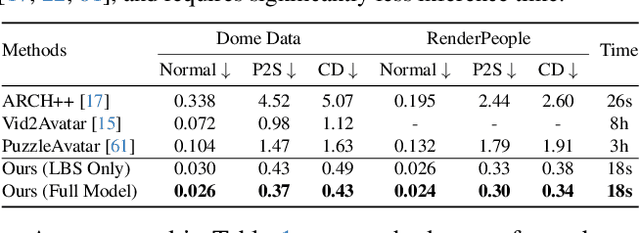
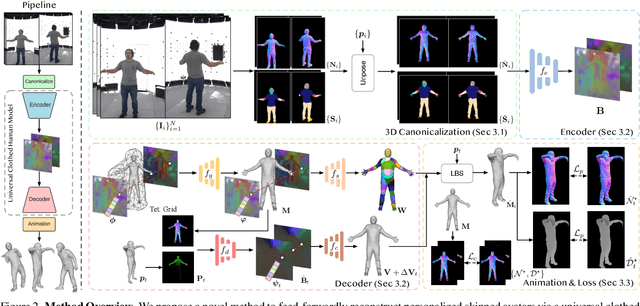
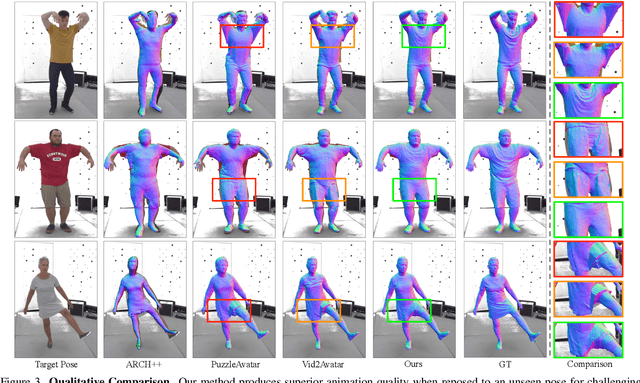
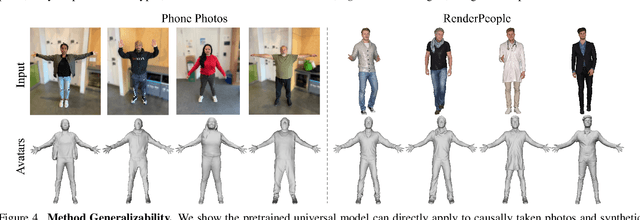
We present a novel method for reconstructing personalized 3D human avatars with realistic animation from only a few images. Due to the large variations in body shapes, poses, and cloth types, existing methods mostly require hours of per-subject optimization during inference, which limits their practical applications. In contrast, we learn a universal prior from over a thousand clothed humans to achieve instant feedforward generation and zero-shot generalization. Specifically, instead of rigging the avatar with shared skinning weights, we jointly infer personalized avatar shape, skinning weights, and pose-dependent deformations, which effectively improves overall geometric fidelity and reduces deformation artifacts. Moreover, to normalize pose variations and resolve coupled ambiguity between canonical shapes and skinning weights, we design a 3D canonicalization process to produce pixel-aligned initial conditions, which helps to reconstruct fine-grained geometric details. We then propose a multi-frame feature aggregation to robustly reduce artifacts introduced in canonicalization and fuse a plausible avatar preserving person-specific identities. Finally, we train the model in an end-to-end framework on a large-scale capture dataset, which contains diverse human subjects paired with high-quality 3D scans. Extensive experiments show that our method generates more authentic reconstruction and animation than state-of-the-arts, and can be directly generalized to inputs from casually taken phone photos. Project page and code is available at https://github.com/rongakowang/FRESA.
Avat3r: Large Animatable Gaussian Reconstruction Model for High-fidelity 3D Head Avatars
Feb 27, 2025Traditionally, creating photo-realistic 3D head avatars requires a studio-level multi-view capture setup and expensive optimization during test-time, limiting the use of digital human doubles to the VFX industry or offline renderings. To address this shortcoming, we present Avat3r, which regresses a high-quality and animatable 3D head avatar from just a few input images, vastly reducing compute requirements during inference. More specifically, we make Large Reconstruction Models animatable and learn a powerful prior over 3D human heads from a large multi-view video dataset. For better 3D head reconstructions, we employ position maps from DUSt3R and generalized feature maps from the human foundation model Sapiens. To animate the 3D head, our key discovery is that simple cross-attention to an expression code is already sufficient. Finally, we increase robustness by feeding input images with different expressions to our model during training, enabling the reconstruction of 3D head avatars from inconsistent inputs, e.g., an imperfect phone capture with accidental movement, or frames from a monocular video. We compare Avat3r with current state-of-the-art methods for few-input and single-input scenarios, and find that our method has a competitive advantage in both tasks. Finally, we demonstrate the wide applicability of our proposed model, creating 3D head avatars from images of different sources, smartphone captures, single images, and even out-of-domain inputs like antique busts. Project website: https://tobias-kirschstein.github.io/avat3r/
Relightable Full-Body Gaussian Codec Avatars
Jan 24, 2025



We propose Relightable Full-Body Gaussian Codec Avatars, a new approach for modeling relightable full-body avatars with fine-grained details including face and hands. The unique challenge for relighting full-body avatars lies in the large deformations caused by body articulation and the resulting impact on appearance caused by light transport. Changes in body pose can dramatically change the orientation of body surfaces with respect to lights, resulting in both local appearance changes due to changes in local light transport functions, as well as non-local changes due to occlusion between body parts. To address this, we decompose the light transport into local and non-local effects. Local appearance changes are modeled using learnable zonal harmonics for diffuse radiance transfer. Unlike spherical harmonics, zonal harmonics are highly efficient to rotate under articulation. This allows us to learn diffuse radiance transfer in a local coordinate frame, which disentangles the local radiance transfer from the articulation of the body. To account for non-local appearance changes, we introduce a shadow network that predicts shadows given precomputed incoming irradiance on a base mesh. This facilitates the learning of non-local shadowing between the body parts. Finally, we use a deferred shading approach to model specular radiance transfer and better capture reflections and highlights such as eye glints. We demonstrate that our approach successfully models both the local and non-local light transport required for relightable full-body avatars, with a superior generalization ability under novel illumination conditions and unseen poses.