 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Dynamics for Full Body Avatar Animation
May 20, 2026Pose-driven full-body avatars built on neural rendering produce high-quality novel views of a captured subject. Yet loose clothing and other dynamic elements deform in ways pose alone cannot explain: the same pose can correspond to many different states, because their motion depends on history, inertia, and contact. Explicit simulation and layered-garment methods can model such dynamics, but they require either a dedicated garment template, which raw multi-view capture does not naturally provide, or a test-time physics simulator with non-trivial runtime cost. A parallel line of work learns data-driven clothing avatars that avoid explicit garment layers. These methods add an auxiliary latent for variation beyond pose; at inference, they fix it, regress it from pose, or retrieve it from training data, without explicitly modeling how the latent evolves with its own dynamics. Additionally, even in everyday motion with loose clothing, existing architectures often struggle to capture fine-grained detail, producing blurry renderings and temporal artifacts. We augment a pose-conditioned 3D Gaussian avatar with a transformer-based decoder and a dynamics residual latent that captures temporal appearance and geometry variation beyond the driving signals. At inference, a learned latent dynamics model evolves the residual latent from a short pose history and the previous latent state. The model decomposes each update into driving, restoring, and dissipative forces, producing temporally coherent, history-dependent rollouts with negligible added cost. Different initial conditions yield diverse yet plausible motion trajectories, and the force decomposition exposes controls such as stiffness. Across nine captured sequences of everyday motion with diverse loose garments, quantitative metrics and a perceptual user study show improved animation quality over recent data-driven baselines.
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
3DGH: 3D Head Generation with Composable Hair and Face
Jun 25, 2025We present 3DGH, an unconditional generative model for 3D human heads with composable hair and face components. Unlike previous work that entangles the modeling of hair and face, we propose to separate them using a novel data representation with template-based 3D Gaussian Splatting, in which deformable hair geometry is introduced to capture the geometric variations across different hairstyles. Based on this data representation, we design a 3D GAN-based architecture with dual generators and employ a cross-attention mechanism to model the inherent correlation between hair and face. The model is trained on synthetic renderings using carefully designed objectives to stabilize training and facilitate hair-face separation. We conduct extensive experiments to validate the design choice of 3DGH, and evaluate it both qualitatively and quantitatively by comparing with several state-of-the-art 3D GAN methods, demonstrating its effectiveness in unconditional full-head image synthesis and composable 3D hairstyle editing. More details will be available on our project page: https://c-he.github.io/projects/3dgh/.
A Repulsive Force Unit for Garment Collision Handling in Neural Networks
Jul 28, 2022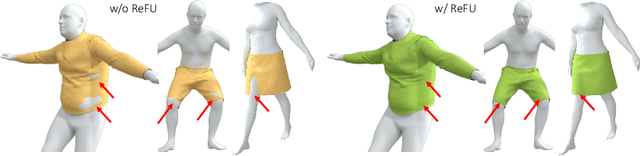
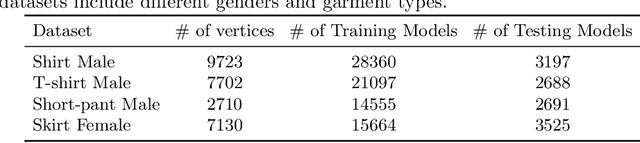
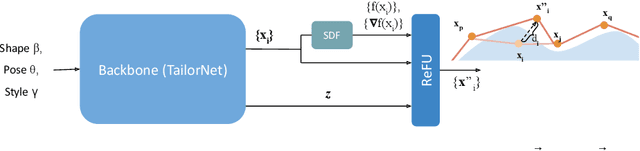
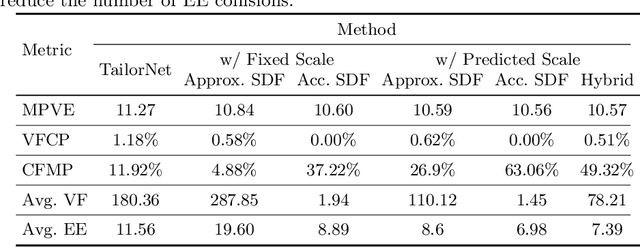
Despite recent success, deep learning-based methods for predicting 3D garment deformation under body motion suffer from interpenetration problems between the garment and the body. To address this problem, we propose a novel collision handling neural network layer called Repulsive Force Unit (ReFU). Based on the signed distance function (SDF) of the underlying body and the current garment vertex positions, ReFU predicts the per-vertex offsets that push any interpenetrating vertex to a collision-free configuration while preserving the fine geometric details. We show that ReFU is differentiable with trainable parameters and can be integrated into different network backbones that predict 3D garment deformations. Our experiments show that ReFU significantly reduces the number of collisions between the body and the garment and better preserves geometric details compared to prior methods based on collision loss or post-processing optimization.
Active Learning of Neural Collision Handler for Complex 3D Mesh Deformations
Oct 08, 2021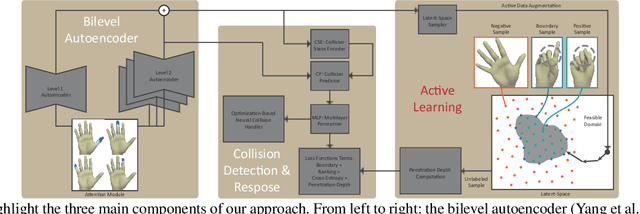
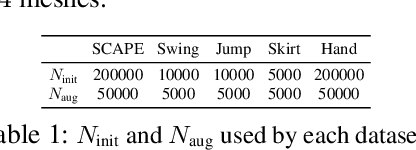
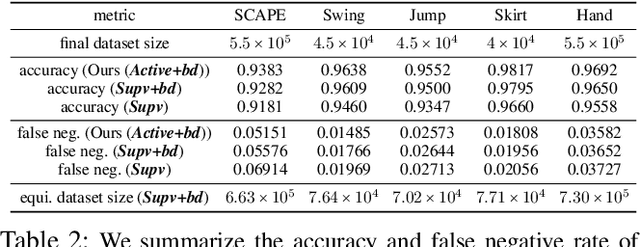
We present a robust learning algorithm to detect and handle collisions in 3D deforming meshes. Our collision detector is represented as a bilevel deep autoencoder with an attention mechanism that identifies colliding mesh sub-parts. We use a numerical optimization algorithm to resolve penetrations guided by the network. Our learned collision handler can resolve collisions for unseen, high-dimensional meshes with thousands of vertices. To obtain stable network performance in such large and unseen spaces, we progressively insert new collision data based on the errors in network inferences. We automatically label these data using an analytical collision detector and progressively fine-tune our detection networks. We evaluate our method for collision handling of complex, 3D meshes coming from several datasets with different shapes and topologies, including datasets corresponding to dressed and undressed human poses, cloth simulations, and human hand poses acquired using multiview capture systems. Our approach outperforms supervised learning methods and achieves $93.8-98.1\%$ accuracy compared to the groundtruth by analytic methods. Compared to prior learning methods, our approach results in a $5.16\%-25.50\%$ lower false negative rate in terms of collision checking and a $9.65\%-58.91\%$ higher success rate in collision handling.
Multiscale Mesh Deformation Component Analysis with Attention-based Autoencoders
Dec 04, 2020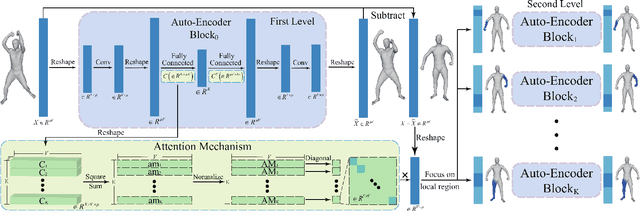
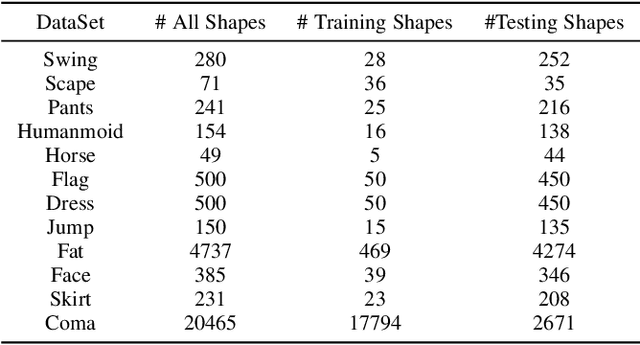

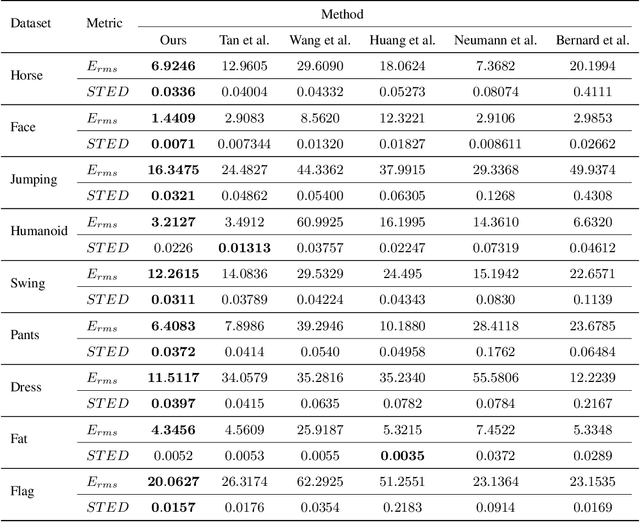
Deformation component analysis is a fundamental problem in geometry processing and shape understanding. Existing approaches mainly extract deformation components in local regions at a similar scale while deformations of real-world objects are usually distributed in a multi-scale manner. In this paper, we propose a novel method to exact multiscale deformation components automatically with a stacked attention-based autoencoder. The attention mechanism is designed to learn to softly weight multi-scale deformation components in active deformation regions, and the stacked attention-based autoencoder is learned to represent the deformation components at different scales. Quantitative and qualitative evaluations show that our method outperforms state-of-the-art methods. Furthermore, with the multiscale deformation components extracted by our method, the user can edit shapes in a coarse-to-fine fashion which facilitates effective modeling of new shapes.
DeepMNavigate: Deep Reinforced Multi-Robot Navigation Unifying Local & Global Collision Avoidance
Oct 22, 2019

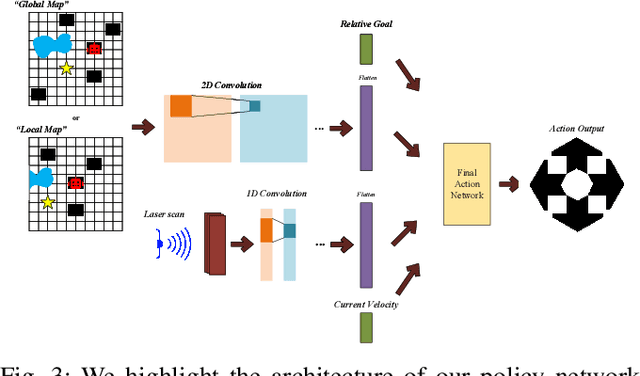
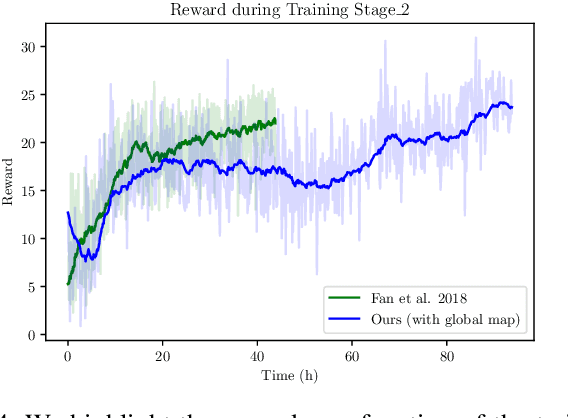
We present a novel algorithm (DeepMNavigate) for global multi-agent navigation in dense scenarios using deep reinforcement learning. Our approach uses local and global information for each robot based on motion information maps. We use a three-layer CNN that uses these maps as input and generate a suitable action to drive each robot to its goal position. Our approach is general, learns an optimal policy using a multi-scenario, multi-state training algorithm, and can directly handle raw sensor measurements for local observations. We demonstrate the performance on complex, dense benchmarks with narrow passages on environments with tens of agents. We highlight the algorithm's benefits over prior learning methods and geometric decentralized algorithms in complex scenarios.
Realtime Simulation of Thin-Shell Deformable Materials using CNN-Based Mesh Embedding
Sep 30, 2019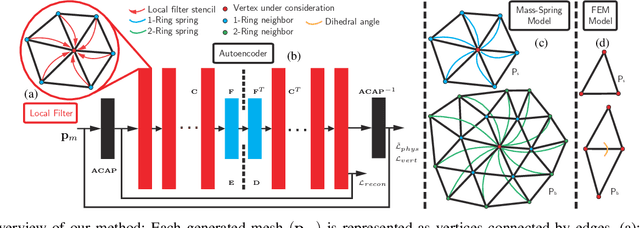

We address the problem of accelerating thin-shell deformable object simulations by dimension reduction. We present a new algorithm to embed a high-dimensional configuration space of deformable objects in a low-dimensional feature space, where the configurations of objects and feature points have approximate one-to-one mapping. Our key technique is a graph-based convolutional neural network (CNN) defined on meshes with arbitrary topologies and a new mesh embedding approach based on physics-inspired loss term. We have applied our approach to accelerate high-resolution thin shell simulations corresponding to cloth-like materials, where the configuration space has tens of thousands of degrees of freedom. We show that our physics-inspired embedding approach leads to higher accuracy compared with prior mesh embedding methods. Finally, we show that the temporal evolution of the mesh in the feature space can also be learned using a recurrent neural network (RNN) leading to fully learnable physics simulators. After training our learned simulator runs $10-100\times$ faster and the accuracy is high enough for robot manipulation tasks.