 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreResQ-R1: Towards Fine-Grained Rank-and-Score Reinforcement Learning for Visual Quality Assessment via Preference-Response Disentangled Policy Optimization
Nov 07, 2025Visual Quality Assessment (QA) seeks to predict human perceptual judgments of visual fidelity. While recent multimodal large language models (MLLMs) show promise in reasoning about image and video quality, existing approaches mainly rely on supervised fine-tuning or rank-only objectives, resulting in shallow reasoning, poor score calibration, and limited cross-domain generalization. We propose PreResQ-R1, a Preference-Response Disentangled Reinforcement Learning framework that unifies absolute score regression and relative ranking consistency within a single reasoning-driven optimization scheme. Unlike prior QA methods, PreResQ-R1 introduces a dual-branch reward formulation that separately models intra-sample response coherence and inter-sample preference alignment, optimized via Group Relative Policy Optimization (GRPO). This design encourages fine-grained, stable, and interpretable chain-of-thought reasoning about perceptual quality. To extend beyond static imagery, we further design a global-temporal and local-spatial data flow strategy for Video Quality Assessment. Remarkably, with reinforcement fine-tuning on only 6K images and 28K videos, PreResQ-R1 achieves state-of-the-art results across 10 IQA and 5 VQA benchmarks under both SRCC and PLCC metrics, surpassing by margins of 5.30% and textbf2.15% in IQA task, respectively. Beyond quantitative gains, it produces human-aligned reasoning traces that reveal the perceptual cues underlying quality judgments. Code and model are available.
Capture, Canonicalize, Splat: Zero-Shot 3D Gaussian Avatars from Unstructured Phone Images
Oct 15, 2025We present a novel, zero-shot pipeline for creating hyperrealistic, identity-preserving 3D avatars from a few unstructured phone images. Existing methods face several challenges: single-view approaches suffer from geometric inconsistencies and hallucinations, degrading identity preservation, while models trained on synthetic data fail to capture high-frequency details like skin wrinkles and fine hair, limiting realism. Our method introduces two key contributions: (1) a generative canonicalization module that processes multiple unstructured views into a standardized, consistent representation, and (2) a transformer-based model trained on a new, large-scale dataset of high-fidelity Gaussian splatting avatars derived from dome captures of real people. This "Capture, Canonicalize, Splat" pipeline produces static quarter-body avatars with compelling realism and robust identity preservation from unstructured photos.
3DGH: 3D Head Generation with Composable Hair and Face
Jun 25, 2025We present 3DGH, an unconditional generative model for 3D human heads with composable hair and face components. Unlike previous work that entangles the modeling of hair and face, we propose to separate them using a novel data representation with template-based 3D Gaussian Splatting, in which deformable hair geometry is introduced to capture the geometric variations across different hairstyles. Based on this data representation, we design a 3D GAN-based architecture with dual generators and employ a cross-attention mechanism to model the inherent correlation between hair and face. The model is trained on synthetic renderings using carefully designed objectives to stabilize training and facilitate hair-face separation. We conduct extensive experiments to validate the design choice of 3DGH, and evaluate it both qualitatively and quantitatively by comparing with several state-of-the-art 3D GAN methods, demonstrating its effectiveness in unconditional full-head image synthesis and composable 3D hairstyle editing. More details will be available on our project page: https://c-he.github.io/projects/3dgh/.
FRESA:Feedforward Reconstruction of Personalized Skinned Avatars from Few Images
Mar 24, 2025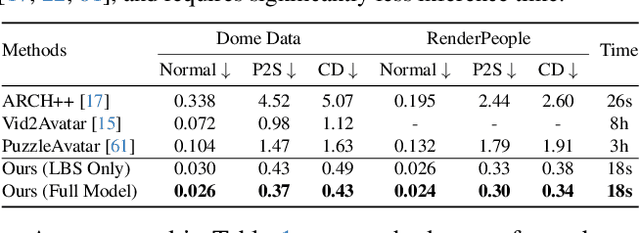
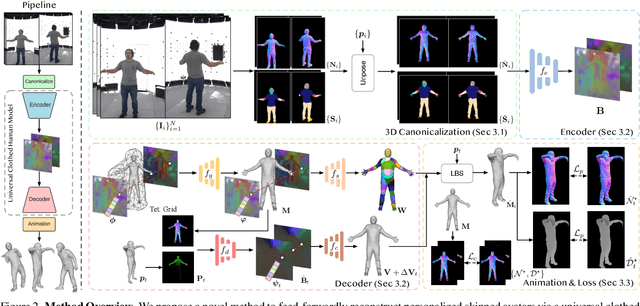
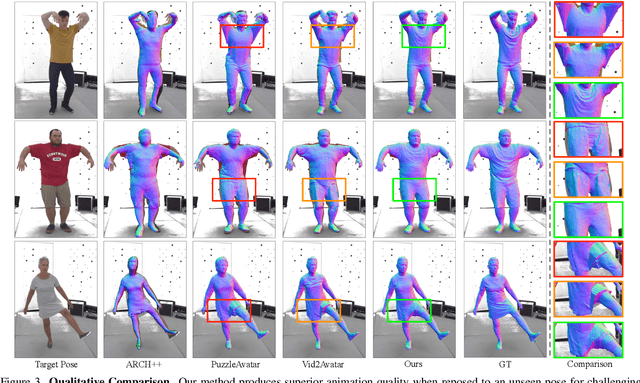
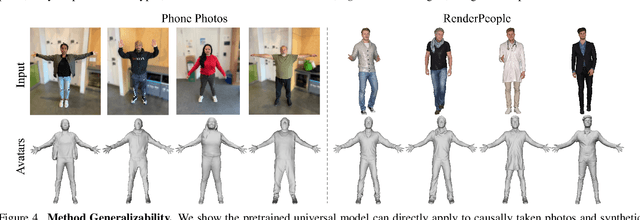
We present a novel method for reconstructing personalized 3D human avatars with realistic animation from only a few images. Due to the large variations in body shapes, poses, and cloth types, existing methods mostly require hours of per-subject optimization during inference, which limits their practical applications. In contrast, we learn a universal prior from over a thousand clothed humans to achieve instant feedforward generation and zero-shot generalization. Specifically, instead of rigging the avatar with shared skinning weights, we jointly infer personalized avatar shape, skinning weights, and pose-dependent deformations, which effectively improves overall geometric fidelity and reduces deformation artifacts. Moreover, to normalize pose variations and resolve coupled ambiguity between canonical shapes and skinning weights, we design a 3D canonicalization process to produce pixel-aligned initial conditions, which helps to reconstruct fine-grained geometric details. We then propose a multi-frame feature aggregation to robustly reduce artifacts introduced in canonicalization and fuse a plausible avatar preserving person-specific identities. Finally, we train the model in an end-to-end framework on a large-scale capture dataset, which contains diverse human subjects paired with high-quality 3D scans. Extensive experiments show that our method generates more authentic reconstruction and animation than state-of-the-arts, and can be directly generalized to inputs from casually taken phone photos. Project page and code is available at https://github.com/rongakowang/FRESA.
Vid2Avatar-Pro: Authentic Avatar from Videos in the Wild via Universal Prior
Mar 03, 2025We present Vid2Avatar-Pro, a method to create photorealistic and animatable 3D human avatars from monocular in-the-wild videos. Building a high-quality avatar that supports animation with diverse poses from a monocular video is challenging because the observation of pose diversity and view points is inherently limited. The lack of pose variations typically leads to poor generalization to novel poses, and avatars can easily overfit to limited input view points, producing artifacts and distortions from other views. In this work, we address these limitations by leveraging a universal prior model (UPM) learned from a large corpus of multi-view clothed human performance capture data. We build our representation on top of expressive 3D Gaussians with canonical front and back maps shared across identities. Once the UPM is learned to accurately reproduce the large-scale multi-view human images, we fine-tune the model with an in-the-wild video via inverse rendering to obtain a personalized photorealistic human avatar that can be faithfully animated to novel human motions and rendered from novel views. The experiments show that our approach based on the learned universal prior sets a new state-of-the-art in monocular avatar reconstruction by substantially outperforming existing approaches relying only on heuristic regularization or a shape prior of minimally clothed bodies (e.g., SMPL) on publicly available datasets.
LUCAS: Layered Universal Codec Avatars
Feb 27, 2025



Photorealistic 3D head avatar reconstruction faces critical challenges in modeling dynamic face-hair interactions and achieving cross-identity generalization, particularly during expressions and head movements. We present LUCAS, a novel Universal Prior Model (UPM) for codec avatar modeling that disentangles face and hair through a layered representation. Unlike previous UPMs that treat hair as an integral part of the head, our approach separates the modeling of the hairless head and hair into distinct branches. LUCAS is the first to introduce a mesh-based UPM, facilitating real-time rendering on devices. Our layered representation also improves the anchor geometry for precise and visually appealing Gaussian renderings. Experimental results indicate that LUCAS outperforms existing single-mesh and Gaussian-based avatar models in both quantitative and qualitative assessments, including evaluations on held-out subjects in zero-shot driving scenarios. LUCAS demonstrates superior dynamic performance in managing head pose changes, expression transfer, and hairstyle variations, thereby advancing the state-of-the-art in 3D head avatar reconstruction.
Relightable Full-Body Gaussian Codec Avatars
Jan 24, 2025



We propose Relightable Full-Body Gaussian Codec Avatars, a new approach for modeling relightable full-body avatars with fine-grained details including face and hands. The unique challenge for relighting full-body avatars lies in the large deformations caused by body articulation and the resulting impact on appearance caused by light transport. Changes in body pose can dramatically change the orientation of body surfaces with respect to lights, resulting in both local appearance changes due to changes in local light transport functions, as well as non-local changes due to occlusion between body parts. To address this, we decompose the light transport into local and non-local effects. Local appearance changes are modeled using learnable zonal harmonics for diffuse radiance transfer. Unlike spherical harmonics, zonal harmonics are highly efficient to rotate under articulation. This allows us to learn diffuse radiance transfer in a local coordinate frame, which disentangles the local radiance transfer from the articulation of the body. To account for non-local appearance changes, we introduce a shadow network that predicts shadows given precomputed incoming irradiance on a base mesh. This facilitates the learning of non-local shadowing between the body parts. Finally, we use a deferred shading approach to model specular radiance transfer and better capture reflections and highlights such as eye glints. We demonstrate that our approach successfully models both the local and non-local light transport required for relightable full-body avatars, with a superior generalization ability under novel illumination conditions and unseen poses.
URAvatar: Universal Relightable Gaussian Codec Avatars
Oct 31, 2024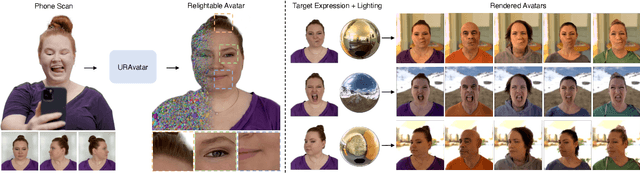

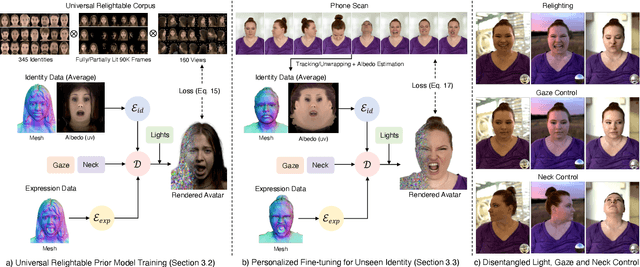
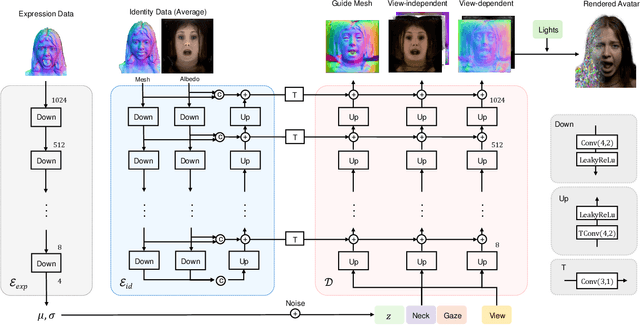
We present a new approach to creating photorealistic and relightable head avatars from a phone scan with unknown illumination. The reconstructed avatars can be animated and relit in real time with the global illumination of diverse environments. Unlike existing approaches that estimate parametric reflectance parameters via inverse rendering, our approach directly models learnable radiance transfer that incorporates global light transport in an efficient manner for real-time rendering. However, learning such a complex light transport that can generalize across identities is non-trivial. A phone scan in a single environment lacks sufficient information to infer how the head would appear in general environments. To address this, we build a universal relightable avatar model represented by 3D Gaussians. We train on hundreds of high-quality multi-view human scans with controllable point lights. High-resolution geometric guidance further enhances the reconstruction accuracy and generalization. Once trained, we finetune the pretrained model on a phone scan using inverse rendering to obtain a personalized relightable avatar. Our experiments establish the efficacy of our design, outperforming existing approaches while retaining real-time rendering capability.
NL2OR: Solve Complex Operations Research Problems Using Natural Language Inputs
Aug 14, 2024



Operations research (OR) uses mathematical models to enhance decision-making, but developing these models requires expert knowledge and can be time-consuming. Automated mathematical programming (AMP) has emerged to simplify this process, but existing systems have limitations. This paper introduces a novel methodology that uses recent advances in Large Language Model (LLM) to create and edit OR solutions from non-expert user queries expressed using Natural Language. This reduces the need for domain expertise and the time to formulate a problem. The paper presents an end-to-end pipeline, named NL2OR, that generates solutions to OR problems from natural language input, and shares experimental results on several important OR problems.
V2VSSC: A 3D Semantic Scene Completion Benchmark for Perception with Vehicle to Vehicle Communication
Feb 07, 2024Semantic scene completion (SSC) has recently gained popularity because it can provide both semantic and geometric information that can be used directly for autonomous vehicle navigation. However, there are still challenges to overcome. SSC is often hampered by occlusion and short-range perception due to sensor limitations, which can pose safety risks. This paper proposes a fundamental solution to this problem by leveraging vehicle-to-vehicle (V2V) communication. We propose the first generalized collaborative SSC framework that allows autonomous vehicles to share sensing information from different sensor views to jointly perform SSC tasks. To validate the proposed framework, we further build V2VSSC, the first V2V SSC benchmark, on top of the large-scale V2V perception dataset OPV2V. Extensive experiments demonstrate that by leveraging V2V communication, the SSC performance can be increased by 8.3% on geometric metric IoU and 6.0% mIOU.