 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePianoFlow: Music-Aware Streaming Piano Motion Generation with Bimanual Coordination
Apr 14, 2026Audio-driven bimanual piano motion generation requires precise modeling of complex musical structures and dynamic cross-hand coordination. However, existing methods often rely on acoustic-only representations lacking symbolic priors, employ inflexible interaction mechanisms, and are limited to computationally expensive short-sequence generation. To address these limitations, we propose PianoFlow, a flow-matching framework for precise and coordinated bimanual piano motion synthesis. Our approach strategically leverages MIDI as a privileged modality during training, distilling these structured musical priors to achieve deep semantic understanding while maintaining audio-only inference. Furthermore, we introduce an asymmetric role-gated interaction module to explicitly capture dynamic cross-hand coordination through role-aware attention and temporal gating. To enable real-time streaming generation for arbitrarily long sequences, we design an autoregressive flow continuation scheme that ensures seamless cross-chunk temporal coherence. Extensive experiments on the PianoMotion10M dataset demonstrate that PianoFlow achieves superior quantitative and qualitative performance, while accelerating inference by over 9\times compared to previous methods.
FURINA: Free from Unmergeable Router via LINear Aggregation of mixed experts
Sep 18, 2025


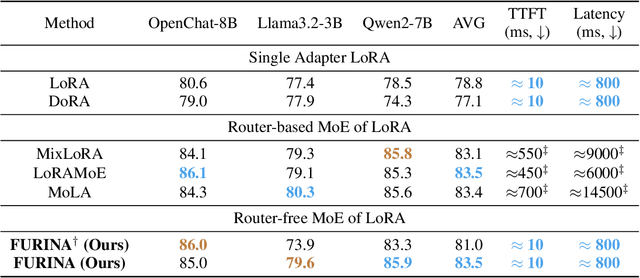
The Mixture of Experts (MoE) paradigm has been successfully integrated into Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning (PEFT), delivering performance gains with minimal parameter overhead. However, a key limitation of existing MoE-LoRA methods is their reliance on a discrete router, which prevents the integration of the MoE components into the backbone model. To overcome this, we propose FURINA, a novel Free from Unmergeable Router framework based on the LINear Aggregation of experts. FURINA eliminates the router by introducing a Self-Routing mechanism. This is achieved through three core innovations: (1) decoupled learning of the direction and magnitude for LoRA adapters, (2) a shared learnable magnitude vector for consistent activation scaling, and (3) expert selection loss that encourages divergent expert activation. The proposed mechanism leverages the angular similarity between the input and each adapter's directional component to activate experts, which are then scaled by the shared magnitude vector. This design allows the output norm to naturally reflect the importance of each expert, thereby enabling dynamic, router-free routing. The expert selection loss further sharpens this behavior by encouraging sparsity and aligning it with standard MoE activation patterns. We also introduce a shared expert within the MoE-LoRA block that provides stable, foundational knowledge. To the best of our knowledge, FURINA is the first router-free, MoE-enhanced LoRA method that can be fully merged into the backbone model, introducing zero additional inference-time cost or complexity. Extensive experiments demonstrate that FURINA not only significantly outperforms standard LoRA but also matches or surpasses the performance of existing MoE-LoRA methods, while eliminating the extra inference-time overhead of MoE.
CAD-Judge: Toward Efficient Morphological Grading and Verification for Text-to-CAD Generation
Aug 06, 2025Computer-Aided Design (CAD) models are widely used across industrial design, simulation, and manufacturing processes. Text-to-CAD systems aim to generate editable, general-purpose CAD models from textual descriptions, significantly reducing the complexity and entry barrier associated with traditional CAD workflows. However, rendering CAD models can be slow, and deploying VLMs to review CAD models can be expensive and may introduce reward hacking that degrades the systems. To address these challenges, we propose CAD-Judge, a novel, verifiable reward system for efficient and effective CAD preference grading and grammatical validation. We adopt the Compiler-as-a-Judge Module (CJM) as a fast, direct reward signal, optimizing model alignment by maximizing generative utility through prospect theory. To further improve the robustness of Text-to-CAD in the testing phase, we introduce a simple yet effective agentic CAD generation approach and adopt the Compiler-as-a-Review Module (CRM), which efficiently verifies the generated CAD models, enabling the system to refine them accordingly. Extensive experiments on challenging CAD datasets demonstrate that our method achieves state-of-the-art performance while maintaining superior efficiency.
AdaFV: Accelerating VLMs with Self-Adaptive Cross-Modality Attention Mixture
Jan 16, 2025



The success of VLMs often relies on the dynamic high-resolution schema that adaptively augments the input images to multiple crops, so that the details of the images can be retained. However, such approaches result in a large number of redundant visual tokens, thus significantly reducing the efficiency of the VLMs. To improve the VLMs' efficiency without introducing extra training costs, many research works are proposed to reduce the visual tokens by filtering the uninformative visual tokens or aggregating their information. Some approaches propose to reduce the visual tokens according to the self-attention of VLMs, which are biased, to result in inaccurate responses. The token reduction approaches solely rely on visual cues are text-agnostic, and fail to focus on the areas that are most relevant to the question, especially when the queried objects are non-salient to the image. In this work, we first conduct experiments to show that the original text embeddings are aligned with the visual tokens, without bias on the tailed visual tokens. We then propose a self-adaptive cross-modality attention mixture mechanism that dynamically leverages the effectiveness of visual saliency and text-to-image similarity in the pre-LLM layers to select the visual tokens that are informative. Extensive experiments demonstrate that the proposed approach achieves state-of-the-art training-free VLM acceleration performance, especially when the reduction rate is sufficiently large.
SLIM: Let LLM Learn More and Forget Less with Soft LoRA and Identity Mixture
Oct 10, 2024



Although many efforts have been made, it is still a challenge to balance the training budget, downstream performance, and the general capabilities of the LLMs in many applications. Training the whole model for downstream tasks is expensive, and could easily result in catastrophic forgetting. By introducing parameter-efficient fine-tuning (PEFT), the training cost could be reduced, but it still suffers from forgetting, and limits the learning on the downstream tasks. To efficiently fine-tune the LLMs with less limitation to their downstream performance while mitigating the forgetting of general capabilities, we propose a novel mixture of expert (MoE) framework based on Soft LoRA and Identity Mixture (SLIM), that allows dynamic routing between LoRA adapters and skipping connection, enables the suppression of forgetting. We adopt weight-yielding with sliding clustering for better out-of-domain distinguish to enhance the routing. We also propose to convert the mixture of low-rank adapters to the model merging formulation and introduce fast dynamic merging of LoRA adapters to keep the general capabilities of the base model. Extensive experiments demonstrate that the proposed SLIM is comparable to the state-of-the-art PEFT approaches on the downstream tasks while achieving the leading performance in mitigating catastrophic forgetting.
ESP-Zero: Unsupervised enhancement of zero-shot classification for Extremely Sparse Point cloud
Apr 30, 2024


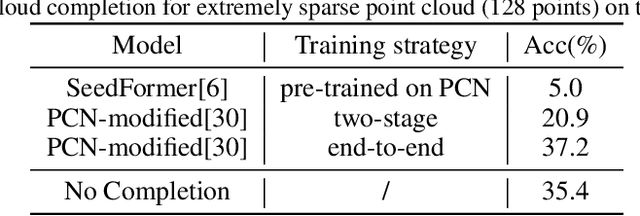
In recent years, zero-shot learning has attracted the focus of many researchers, due to its flexibility and generality. Many approaches have been proposed to achieve the zero-shot classification of the point clouds for 3D object understanding, following the schema of CLIP. However, in the real world, the point clouds could be extremely sparse, dramatically limiting the effectiveness of the 3D point cloud encoders, and resulting in the misalignment of point cloud features and text embeddings. To the point cloud encoders to fit the extremely sparse point clouds without re-running the pre-training procedure which could be time-consuming and expensive, in this work, we propose an unsupervised model adaptation approach to enhance the point cloud encoder for the extremely sparse point clouds. We propose a novel fused-cross attention layer that expands the pre-trained self-attention layer with additional learnable tokens and attention blocks, which effectively modifies the point cloud features while maintaining the alignment between point cloud features and text embeddings. We also propose a complementary learning-based self-distillation schema that encourages the modified features to be pulled apart from the irrelevant text embeddings without overfitting the feature space to the observed text embeddings. Extensive experiments demonstrate that the proposed approach effectively increases the zero-shot capability on extremely sparse point clouds, and overwhelms other state-of-the-art model adaptation approaches.
V2VSSC: A 3D Semantic Scene Completion Benchmark for Perception with Vehicle to Vehicle Communication
Feb 07, 2024



Semantic scene completion (SSC) has recently gained popularity because it can provide both semantic and geometric information that can be used directly for autonomous vehicle navigation. However, there are still challenges to overcome. SSC is often hampered by occlusion and short-range perception due to sensor limitations, which can pose safety risks. This paper proposes a fundamental solution to this problem by leveraging vehicle-to-vehicle (V2V) communication. We propose the first generalized collaborative SSC framework that allows autonomous vehicles to share sensing information from different sensor views to jointly perform SSC tasks. To validate the proposed framework, we further build V2VSSC, the first V2V SSC benchmark, on top of the large-scale V2V perception dataset OPV2V. Extensive experiments demonstrate that by leveraging V2V communication, the SSC performance can be increased by 8.3% on geometric metric IoU and 6.0% mIOU.
Rethinking Precision of Pseudo Label: Test-Time Adaptation via Complementary Learning
Jan 15, 2023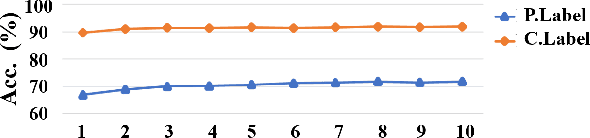

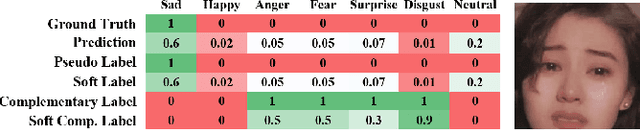
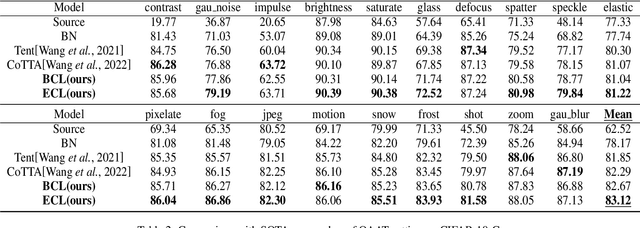
In this work, we propose a novel complementary learning approach to enhance test-time adaptation (TTA), which has been proven to exhibit good performance on testing data with distribution shifts such as corruptions. In test-time adaptation tasks, information from the source domain is typically unavailable and the model has to be optimized without supervision for test-time samples. Hence, usual methods assign labels for unannotated data with the prediction by a well-trained source model in an unsupervised learning framework. Previous studies have employed unsupervised objectives, such as the entropy of model predictions, as optimization targets to effectively learn features for test-time samples. However, the performance of the model is easily compromised by the quality of pseudo-labels, since inaccuracies in pseudo-labels introduce noise to the model. Therefore, we propose to leverage the "less probable categories" to decrease the risk of incorrect pseudo-labeling. The complementary label is introduced to designate these categories. We highlight that the risk function of complementary labels agrees with their Vanilla loss formula under the conventional true label distribution. Experiments show that the proposed learning algorithm achieves state-of-the-art performance on different datasets and experiment settings.
Enabling Augmented Segmentation and Registration in Ultrasound-Guided Spinal Surgery via Realistic Ultrasound Synthesis from Diagnostic CT Volume
Jan 05, 2023This paper aims to tackle the issues on unavailable or insufficient clinical US data and meaningful annotation to enable bone segmentation and registration for US-guided spinal surgery. While the US is not a standard paradigm for spinal surgery, the scarcity of intra-operative clinical US data is an insurmountable bottleneck in training a neural network. Moreover, due to the characteristics of US imaging, it is difficult to clearly annotate bone surfaces which causes the trained neural network missing its attention to the details. Hence, we propose an In silico bone US simulation framework that synthesizes realistic US images from diagnostic CT volume. Afterward, using these simulated bone US we train a lightweight vision transformer model that can achieve accurate and on-the-fly bone segmentation for spinal sonography. In the validation experiments, the realistic US simulation was conducted by deriving from diagnostic spinal CT volume to facilitate a radiation-free US-guided pedicle screw placement procedure. When it is employed for training bone segmentation task, the Chamfer distance achieves 0.599mm; when it is applied for CT-US registration, the associated bone segmentation accuracy achieves 0.93 in Dice, and the registration accuracy based on the segmented point cloud is 0.13~3.37mm in a complication-free manner. While bone US images exhibit strong echoes at the medium interface, it may enable the model indistinguishable between thin interfaces and bone surfaces by simply relying on small neighborhood information. To overcome these shortcomings, we propose to utilize a Long-range Contrast Learning Module to fully explore the Long-range Contrast between the candidates and their surrounding pixels.