 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe AI Pentad, the CHARME$^{2}$D Model, and an Assessment of Current-State AI Regulation
Mar 08, 2025



Artificial Intelligence (AI) has made remarkable progress in the past few years with AI-enabled applications beginning to permeate every aspect of our society. Despite the widespread consensus on the need to regulate AI, there remains a lack of a unified approach to framing, developing, and assessing AI regulations. Many of the existing methods take a value-based approach, for example, accountability, fairness, free from bias, transparency, and trust. However, these methods often face challenges at the outset due to disagreements in academia over the subjective nature of these definitions. This paper aims to establish a unifying model for AI regulation from the perspective of core AI components. We first introduce the AI Pentad, which comprises the five essential components of AI: humans and organizations, algorithms, data, computing, and energy. We then review AI regulatory enablers, including AI registration and disclosure, AI monitoring, and AI enforcement mechanisms. Subsequently, we present the CHARME$^{2}$D Model to explore further the relationship between the AI Pentad and AI regulatory enablers. Finally, we apply the CHARME$^{2}$D model to assess AI regulatory efforts in the European Union (EU), China, the United Arab Emirates (UAE), the United Kingdom (UK), and the United States (US), highlighting their strengths, weaknesses, and gaps. This comparative evaluation offers insights for future legislative work in the AI domain.
AdaFV: Accelerating VLMs with Self-Adaptive Cross-Modality Attention Mixture
Jan 16, 2025



The success of VLMs often relies on the dynamic high-resolution schema that adaptively augments the input images to multiple crops, so that the details of the images can be retained. However, such approaches result in a large number of redundant visual tokens, thus significantly reducing the efficiency of the VLMs. To improve the VLMs' efficiency without introducing extra training costs, many research works are proposed to reduce the visual tokens by filtering the uninformative visual tokens or aggregating their information. Some approaches propose to reduce the visual tokens according to the self-attention of VLMs, which are biased, to result in inaccurate responses. The token reduction approaches solely rely on visual cues are text-agnostic, and fail to focus on the areas that are most relevant to the question, especially when the queried objects are non-salient to the image. In this work, we first conduct experiments to show that the original text embeddings are aligned with the visual tokens, without bias on the tailed visual tokens. We then propose a self-adaptive cross-modality attention mixture mechanism that dynamically leverages the effectiveness of visual saliency and text-to-image similarity in the pre-LLM layers to select the visual tokens that are informative. Extensive experiments demonstrate that the proposed approach achieves state-of-the-art training-free VLM acceleration performance, especially when the reduction rate is sufficiently large.
DenseGNN: universal and scalable deeper graph neural networks for high-performance property prediction in crystals and molecules
Jan 05, 2025Generative models generate vast numbers of hypothetical materials, necessitating fast, accurate models for property prediction. Graph Neural Networks (GNNs) excel in this domain but face challenges like high training costs, domain adaptation issues, and over-smoothing. We introduce DenseGNN, which employs Dense Connectivity Network (DCN), Hierarchical Node-Edge-Graph Residual Networks (HRN), and Local Structure Order Parameters Embedding (LOPE) to address these challenges. DenseGNN achieves state-of-the-art performance on datasets such as JARVIS-DFT, Materials Project, and QM9, improving the performance of models like GIN, Schnet, and Hamnet on materials datasets. By optimizing atomic embeddings and reducing computational costs, DenseGNN enables deeper architectures and surpasses other GNNs in crystal structure distinction, approaching X-ray diffraction method accuracy. This advances materials discovery and design.
* DenseGNN optimizes computational efficiency and accuracy in predicting material properties using DCN, HRN, and LOPE. It enhances transferability and overcomes over-smoothing, enabling deep architectures. Performance improvements on JARVIS-DFT, Materials Project, and QM9 datasets advance materials discovery and design
SLIM: Let LLM Learn More and Forget Less with Soft LoRA and Identity Mixture
Oct 10, 2024



Although many efforts have been made, it is still a challenge to balance the training budget, downstream performance, and the general capabilities of the LLMs in many applications. Training the whole model for downstream tasks is expensive, and could easily result in catastrophic forgetting. By introducing parameter-efficient fine-tuning (PEFT), the training cost could be reduced, but it still suffers from forgetting, and limits the learning on the downstream tasks. To efficiently fine-tune the LLMs with less limitation to their downstream performance while mitigating the forgetting of general capabilities, we propose a novel mixture of expert (MoE) framework based on Soft LoRA and Identity Mixture (SLIM), that allows dynamic routing between LoRA adapters and skipping connection, enables the suppression of forgetting. We adopt weight-yielding with sliding clustering for better out-of-domain distinguish to enhance the routing. We also propose to convert the mixture of low-rank adapters to the model merging formulation and introduce fast dynamic merging of LoRA adapters to keep the general capabilities of the base model. Extensive experiments demonstrate that the proposed SLIM is comparable to the state-of-the-art PEFT approaches on the downstream tasks while achieving the leading performance in mitigating catastrophic forgetting.
RGB-D Salient Object Detection via 3D Convolutional Neural Networks
Jan 25, 2021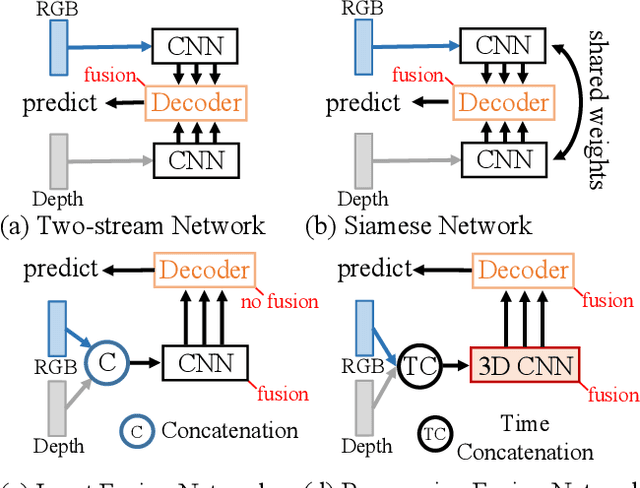



RGB-D salient object detection (SOD) recently has attracted increasing research interest and many deep learning methods based on encoder-decoder architectures have emerged. However, most existing RGB-D SOD models conduct feature fusion either in the single encoder or the decoder stage, which hardly guarantees sufficient cross-modal fusion ability. In this paper, we make the first attempt in addressing RGB-D SOD through 3D convolutional neural networks. The proposed model, named RD3D, aims at pre-fusion in the encoder stage and in-depth fusion in the decoder stage to effectively promote the full integration of RGB and depth streams. Specifically, RD3D first conducts pre-fusion across RGB and depth modalities through an inflated 3D encoder, and later provides in-depth feature fusion by designing a 3D decoder equipped with rich back-projection paths (RBPP) for leveraging the extensive aggregation ability of 3D convolutions. With such a progressive fusion strategy involving both the encoder and decoder, effective and thorough interaction between the two modalities can be exploited and boost the detection accuracy. Extensive experiments on six widely used benchmark datasets demonstrate that RD3D performs favorably against 14 state-of-the-art RGB-D SOD approaches in terms of four key evaluation metrics. Our code will be made publicly available: https://github.com/PPOLYpubki/RD3D.
A deep learning-based method for relative location prediction in CT scan images
Nov 21, 2017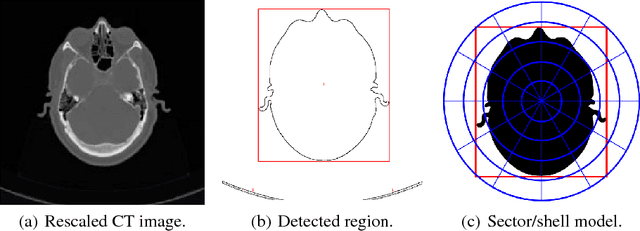
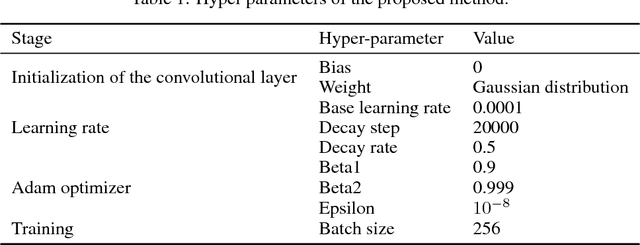

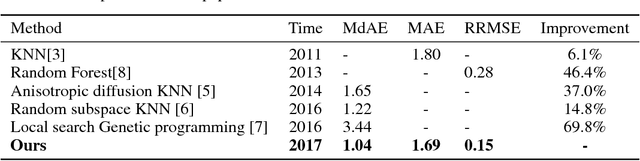
Relative location prediction in computed tomography (CT) scan images is a challenging problem. In this paper, a regression model based on one-dimensional convolutional neural networks is proposed to determine the relative location of a CT scan image both robustly and precisely. A public dataset is employed to validate the performance of the study's proposed method using a 5-fold cross validation. Experimental results demonstrate an excellent performance of the proposed model when compared with the state-of-the-art techniques, achieving a median absolute error of 1.04 cm and mean absolute error of 1.69 cm.