 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaFV: Accelerating VLMs with Self-Adaptive Cross-Modality Attention Mixture
Jan 16, 2025



The success of VLMs often relies on the dynamic high-resolution schema that adaptively augments the input images to multiple crops, so that the details of the images can be retained. However, such approaches result in a large number of redundant visual tokens, thus significantly reducing the efficiency of the VLMs. To improve the VLMs' efficiency without introducing extra training costs, many research works are proposed to reduce the visual tokens by filtering the uninformative visual tokens or aggregating their information. Some approaches propose to reduce the visual tokens according to the self-attention of VLMs, which are biased, to result in inaccurate responses. The token reduction approaches solely rely on visual cues are text-agnostic, and fail to focus on the areas that are most relevant to the question, especially when the queried objects are non-salient to the image. In this work, we first conduct experiments to show that the original text embeddings are aligned with the visual tokens, without bias on the tailed visual tokens. We then propose a self-adaptive cross-modality attention mixture mechanism that dynamically leverages the effectiveness of visual saliency and text-to-image similarity in the pre-LLM layers to select the visual tokens that are informative. Extensive experiments demonstrate that the proposed approach achieves state-of-the-art training-free VLM acceleration performance, especially when the reduction rate is sufficiently large.
SLIM: Let LLM Learn More and Forget Less with Soft LoRA and Identity Mixture
Oct 10, 2024



Although many efforts have been made, it is still a challenge to balance the training budget, downstream performance, and the general capabilities of the LLMs in many applications. Training the whole model for downstream tasks is expensive, and could easily result in catastrophic forgetting. By introducing parameter-efficient fine-tuning (PEFT), the training cost could be reduced, but it still suffers from forgetting, and limits the learning on the downstream tasks. To efficiently fine-tune the LLMs with less limitation to their downstream performance while mitigating the forgetting of general capabilities, we propose a novel mixture of expert (MoE) framework based on Soft LoRA and Identity Mixture (SLIM), that allows dynamic routing between LoRA adapters and skipping connection, enables the suppression of forgetting. We adopt weight-yielding with sliding clustering for better out-of-domain distinguish to enhance the routing. We also propose to convert the mixture of low-rank adapters to the model merging formulation and introduce fast dynamic merging of LoRA adapters to keep the general capabilities of the base model. Extensive experiments demonstrate that the proposed SLIM is comparable to the state-of-the-art PEFT approaches on the downstream tasks while achieving the leading performance in mitigating catastrophic forgetting.
ESP-Zero: Unsupervised enhancement of zero-shot classification for Extremely Sparse Point cloud
Apr 30, 2024


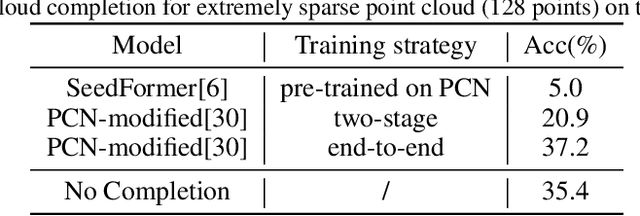
In recent years, zero-shot learning has attracted the focus of many researchers, due to its flexibility and generality. Many approaches have been proposed to achieve the zero-shot classification of the point clouds for 3D object understanding, following the schema of CLIP. However, in the real world, the point clouds could be extremely sparse, dramatically limiting the effectiveness of the 3D point cloud encoders, and resulting in the misalignment of point cloud features and text embeddings. To the point cloud encoders to fit the extremely sparse point clouds without re-running the pre-training procedure which could be time-consuming and expensive, in this work, we propose an unsupervised model adaptation approach to enhance the point cloud encoder for the extremely sparse point clouds. We propose a novel fused-cross attention layer that expands the pre-trained self-attention layer with additional learnable tokens and attention blocks, which effectively modifies the point cloud features while maintaining the alignment between point cloud features and text embeddings. We also propose a complementary learning-based self-distillation schema that encourages the modified features to be pulled apart from the irrelevant text embeddings without overfitting the feature space to the observed text embeddings. Extensive experiments demonstrate that the proposed approach effectively increases the zero-shot capability on extremely sparse point clouds, and overwhelms other state-of-the-art model adaptation approaches.