 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESP-Zero: Unsupervised enhancement of zero-shot classification for Extremely Sparse Point cloud
Apr 30, 2024


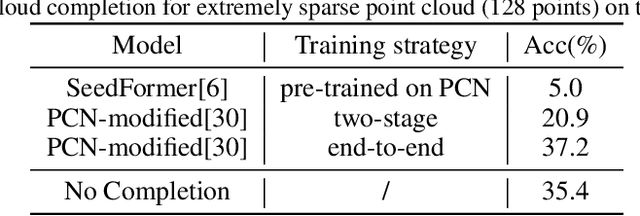
In recent years, zero-shot learning has attracted the focus of many researchers, due to its flexibility and generality. Many approaches have been proposed to achieve the zero-shot classification of the point clouds for 3D object understanding, following the schema of CLIP. However, in the real world, the point clouds could be extremely sparse, dramatically limiting the effectiveness of the 3D point cloud encoders, and resulting in the misalignment of point cloud features and text embeddings. To the point cloud encoders to fit the extremely sparse point clouds without re-running the pre-training procedure which could be time-consuming and expensive, in this work, we propose an unsupervised model adaptation approach to enhance the point cloud encoder for the extremely sparse point clouds. We propose a novel fused-cross attention layer that expands the pre-trained self-attention layer with additional learnable tokens and attention blocks, which effectively modifies the point cloud features while maintaining the alignment between point cloud features and text embeddings. We also propose a complementary learning-based self-distillation schema that encourages the modified features to be pulled apart from the irrelevant text embeddings without overfitting the feature space to the observed text embeddings. Extensive experiments demonstrate that the proposed approach effectively increases the zero-shot capability on extremely sparse point clouds, and overwhelms other state-of-the-art model adaptation approaches.
Speech Emotion Recognition Via CNN-Transforemr and Multidimensional Attention Mechanism
Mar 07, 2024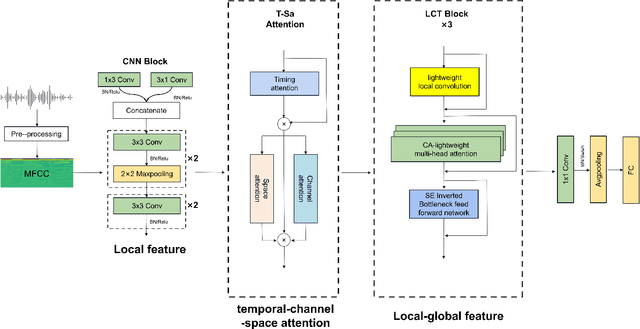
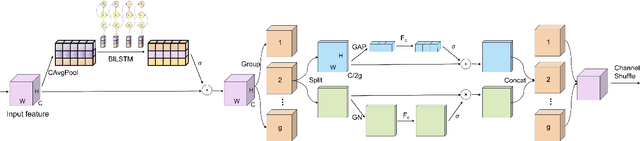
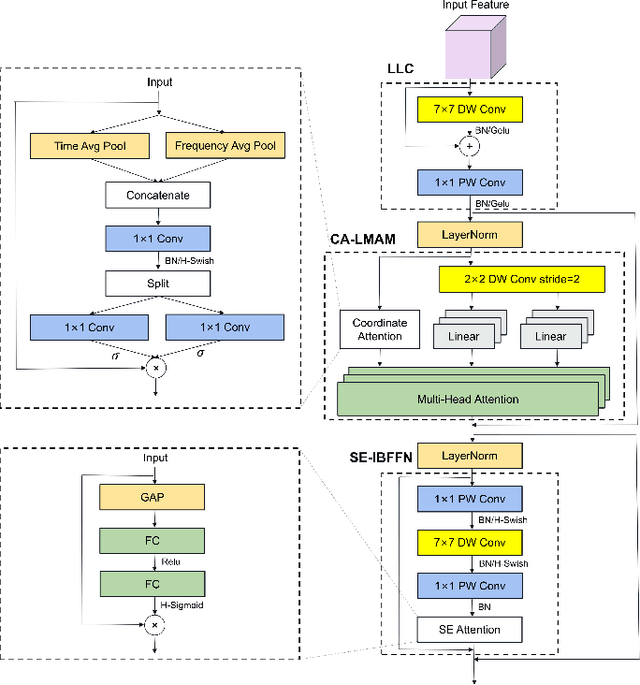
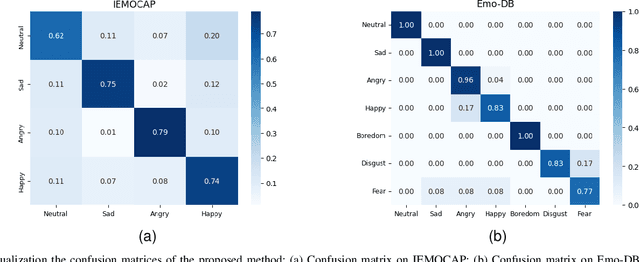
Speech Emotion Recognition (SER) is crucial in human-machine interactions. Mainstream approaches utilize Convolutional Neural Networks or Recurrent Neural Networks to learn local energy feature representations of speech segments from speech information, but struggle with capturing global information such as the duration of energy in speech. Some use Transformers to capture global information, but there is room for improvement in terms of parameter count and performance. Furthermore, existing attention mechanisms focus on spatial or channel dimensions, hindering learning of important temporal information in speech. In this paper, to model local and global information at different levels of granularity in speech and capture temporal, spatial and channel dependencies in speech signals, we propose a Speech Emotion Recognition network based on CNN-Transformer and multi-dimensional attention mechanisms. Specifically, a stack of CNN blocks is dedicated to capturing local information in speech from a time-frequency perspective. In addition, a time-channel-space attention mechanism is used to enhance features across three dimensions. Moreover, we model local and global dependencies of feature sequences using large convolutional kernels with depthwise separable convolutions and lightweight Transformer modules. We evaluate the proposed method on IEMOCAP and Emo-DB datasets and show our approach significantly improves the performance over the state-of-the-art methods. Our code is available on https://github.com/SCNU-RISLAB/CNN-Transforemr-and-Multidimensional-Attention-Mechanism
V2VSSC: A 3D Semantic Scene Completion Benchmark for Perception with Vehicle to Vehicle Communication
Feb 07, 2024Semantic scene completion (SSC) has recently gained popularity because it can provide both semantic and geometric information that can be used directly for autonomous vehicle navigation. However, there are still challenges to overcome. SSC is often hampered by occlusion and short-range perception due to sensor limitations, which can pose safety risks. This paper proposes a fundamental solution to this problem by leveraging vehicle-to-vehicle (V2V) communication. We propose the first generalized collaborative SSC framework that allows autonomous vehicles to share sensing information from different sensor views to jointly perform SSC tasks. To validate the proposed framework, we further build V2VSSC, the first V2V SSC benchmark, on top of the large-scale V2V perception dataset OPV2V. Extensive experiments demonstrate that by leveraging V2V communication, the SSC performance can be increased by 8.3% on geometric metric IoU and 6.0% mIOU.
Explore the difficulty of words and its influential attributes based on the Wordle game
May 03, 2023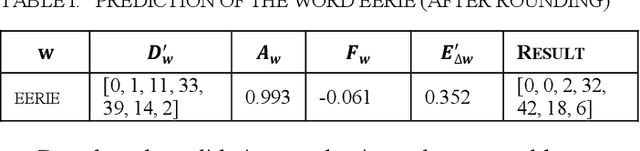

We adopt the distribution and expectation of guessing times in game Wordle as metrics to predict the difficulty of words and explore their influence factors. In order to predictthe difficulty distribution, we use Monte Carlo to simulate the guessing process of players and then narrow the gap between raw and actual distribution of guessing times for each word with Markov which generates the associativity of words. Afterwards, we take advantage of lasso regression to predict the deviation of guessing times expectation and quadratic programming to obtain the correction of the original distribution.To predict the difficulty levels, we first use hierarchical clustering to classify the difficulty levels based on the expectation of guessing times. Afterwards we downscale the variables of lexical attributes based on factor analysis. Significant factors include the number of neighboring words, letter similarity, sub-string similarity, and word frequency. Finally, we build the relationship between lexical attributes and difficulty levels through ordered logistic regression.