 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2VSSC: A 3D Semantic Scene Completion Benchmark for Perception with Vehicle to Vehicle Communication
Feb 07, 2024



Semantic scene completion (SSC) has recently gained popularity because it can provide both semantic and geometric information that can be used directly for autonomous vehicle navigation. However, there are still challenges to overcome. SSC is often hampered by occlusion and short-range perception due to sensor limitations, which can pose safety risks. This paper proposes a fundamental solution to this problem by leveraging vehicle-to-vehicle (V2V) communication. We propose the first generalized collaborative SSC framework that allows autonomous vehicles to share sensing information from different sensor views to jointly perform SSC tasks. To validate the proposed framework, we further build V2VSSC, the first V2V SSC benchmark, on top of the large-scale V2V perception dataset OPV2V. Extensive experiments demonstrate that by leveraging V2V communication, the SSC performance can be increased by 8.3% on geometric metric IoU and 6.0% mIOU.
Robust Edge-Direct Visual Odometry based on CNN edge detection and Shi-Tomasi corner optimization
Oct 21, 2021

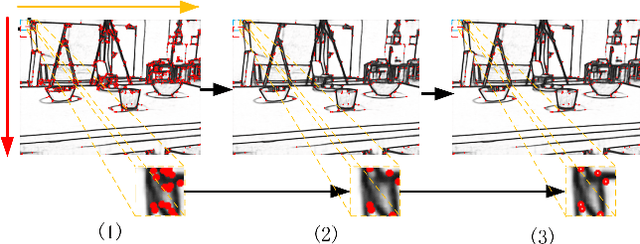
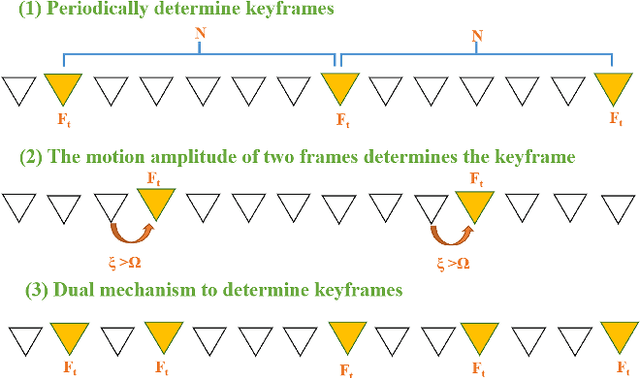
In this paper, we propose a robust edge-direct visual odometry (VO) based on CNN edge detection and Shi-Tomasi corner optimization. Four layers of pyramids were extracted from the image in the proposed method to reduce the motion error between frames. This solution used CNN edge detection and Shi-Tomasi corner optimization to extract information from the image. Then, the pose estimation is performed using the Levenberg-Marquardt (LM) algorithm and updating the keyframes. Our method was compared with the dense direct method, the improved direct method of Canny edge detection, and ORB-SLAM2 system on the RGB-D TUM benchmark. The experimental results indicate that our method achieves better robustness and accuracy.