 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCBSchemaGen: Constraint-Guided Schematic Design via LLM for Printed Circuit Boards (PCB)
Jan 31, 2026Printed Circuit Board (PCB) schematic design plays an essential role in all areas of electronic industries. Unlike prior works that focus on digital or analog circuits alone, PCB design must handle heterogeneous digital, analog, and power signals while adhering to real-world IC packages and pin constraints. Automated PCB schematic design remains unexplored due to the scarcity of open-source data and the absence of simulation-based verification. We introduce PCBSchemaGen, the first training-free framework for PCB schematic design that comprises LLM agent and Constraint-guided synthesis. Our approach makes three contributions: 1. an LLM-based code generation paradigm with iterative feedback with domain-specific prompts. 2. a verification framework leveraging a real-world IC datasheet derived Knowledge Graph (KG) and Subgraph Isomorphism encoding pin-role semantics and topological constraints. 3. an extensive experiment on 23 PCB schematic tasks spanning digital, analog, and power domains. Results demonstrate that PCBSchemaGen significantly improves design accuracy and computational efficiency.
R^3: Replay, Reflection, and Ranking Rewards for LLM Reinforcement Learning
Jan 27, 2026Large reasoning models (LRMs) aim to solve diverse and complex problems through structured reasoning. Recent advances in group-based policy optimization methods have shown promise in enabling stable advantage estimation without reliance on process-level annotations. However, these methods rely on advantage gaps induced by high-quality samples within the same batch, which makes the training process fragile and inefficient when intra-group advantages collapse under challenging tasks. To address these problems, we propose a reinforcement learning mechanism named \emph{\textbf{R^3}} that along three directions: (1) a \emph{cross-context \underline{\textbf{R}}eplay} strategy that maintains the intra-group advantage by recalling valuable examples from historical trajectories of the same query, (2) an \emph{in-context self-\underline{\textbf{R}}eflection} mechanism enabling models to refine outputs by leveraging past failures, and (3) a \emph{structural entropy \underline{\textbf{R}}anking reward}, which assigns relative rewards to truncated or failed samples by ranking responses based on token-level entropy patterns, capturing both local exploration and global stability. We implement our method on Deepseek-R1-Distill-Qwen-1.5B and train it on the DeepscaleR-40k in the math domain. Experiments demonstrate our method achieves SoTA performance on several math benchmarks, representing significant improvements and fewer reasoning tokens over the base models. Code and model will be released.
CoThink: Token-Efficient Reasoning via Instruct Models Guiding Reasoning Models
May 28, 2025Large language models (LLMs) benefit from increased test-time compute, a phenomenon known as test-time scaling. However, reasoning-optimized models often overthink even simple problems, producing excessively verbose outputs and leading to low token efficiency. By comparing these models with equally sized instruct models, we identify two key causes of this verbosity: (1) reinforcement learning reduces the information density of forward reasoning, and (2) backward chain-of thought training encourages redundant and often unnecessary verification steps. Since LLMs cannot assess the difficulty of a given problem, they tend to apply the same cautious reasoning strategy across all tasks, resulting in inefficient overthinking. To address this, we propose CoThink, an embarrassingly simple pipeline: an instruct model first drafts a high-level solution outline; a reasoning model then works out the solution. We observe that CoThink enables dynamic adjustment of reasoning depth based on input difficulty. Evaluated with three reasoning models DAPO, DeepSeek-R1, and QwQ on three datasets GSM8K, MATH500, and AIME24, CoThink reduces total token generation by 22.3% while maintaining pass@1 accuracy within a 0.42% margin on average. With reference to the instruct model, we formally define reasoning efficiency and observe a potential reasoning efficiency scaling law in LLMs.
If an LLM Were a Character, Would It Know Its Own Story? Evaluating Lifelong Learning in LLMs
Mar 30, 2025Large language models (LLMs) can carry out human-like dialogue, but unlike humans, they are stateless due to the superposition property. However, during multi-turn, multi-agent interactions, LLMs begin to exhibit consistent, character-like behaviors, hinting at a form of emergent lifelong learning. Despite this, existing benchmarks often fail to capture these dynamics, primarily focusing on static, open-ended evaluations. To address this gap, we introduce LIFESTATE-BENCH, a benchmark designed to assess lifelong learning in LLMs. It features two episodic datasets: Hamlet and a synthetic script collection, rich in narrative structure and character interactions. Our fact checking evaluation probes models' self-awareness, episodic memory retrieval, and relationship tracking, across both parametric and non-parametric approaches. Experiments on models like Llama3.1-8B, GPT-4-turbo, and DeepSeek R1, we demonstrate that nonparametric methods significantly outperform parametric ones in managing stateful learning. However, all models exhibit challenges with catastrophic forgetting as interactions extend, highlighting the need for further advancements in lifelong learning.
Position-Aware Depth Decay Decoding ($D^3$): Boosting Large Language Model Inference Efficiency
Mar 11, 2025



Due to the large number of parameters, the inference phase of Large Language Models (LLMs) is resource-intensive. Unlike traditional model compression, which needs retraining, recent dynamic computation methods show that not all components are required for inference, enabling a training-free pipeline. In this paper, we focus on the dynamic depth of LLM generation. A token-position aware layer skipping framework is proposed to save 1.5x times operations efficiently while maintaining performance. We first observed that tokens predicted later have lower perplexity and thus require less computation. Then, we propose a training-free algorithm called Position-Aware Depth Decay Decoding ($D^3$), which leverages a power-law decay function, $\left\lfloor L \times (\alpha^i) \right\rfloor$, to determine the number of layers to retain when generating token $T_i$. Remarkably, without any retraining, the $D^3$ achieves success across a wide range of generation tasks for the first time. Experiments on large language models (\ie the Llama) with $7 \sim 70$ billion parameters show that $D^3$ can achieve an average 1.5x speedup compared with the full-inference pipeline while maintaining comparable performance with nearly no performance drop ($<1\%$) on the GSM8K and BBH benchmarks.
Grid and Road Expressions Are Complementary for Trajectory Representation Learning
Nov 22, 2024



Trajectory representation learning (TRL) maps trajectories to vectors that can be used for many downstream tasks. Existing TRL methods use either grid trajectories, capturing movement in free space, or road trajectories, capturing movement in a road network, as input. We observe that the two types of trajectories are complementary, providing either region and location information or providing road structure and movement regularity. Therefore, we propose a novel multimodal TRL method, dubbed GREEN, to jointly utilize Grid and Road trajectory Expressions for Effective representatioN learning. In particular, we transform raw GPS trajectories into both grid and road trajectories and tailor two encoders to capture their respective information. To align the two encoders such that they complement each other, we adopt a contrastive loss to encourage them to produce similar embeddings for the same raw trajectory and design a mask language model (MLM) loss to use grid trajectories to help reconstruct masked road trajectories. To learn the final trajectory representation, a dual-modal interactor is used to fuse the outputs of the two encoders via cross-attention. We compare GREEN with 7 state-of-the-art TRL methods for 3 downstream tasks, finding that GREEN consistently outperforms all baselines and improves the accuracy of the best-performing baseline by an average of 15.99\%.
TEAM: Topological Evolution-aware Framework for Traffic Forecasting--Extended Version
Oct 24, 2024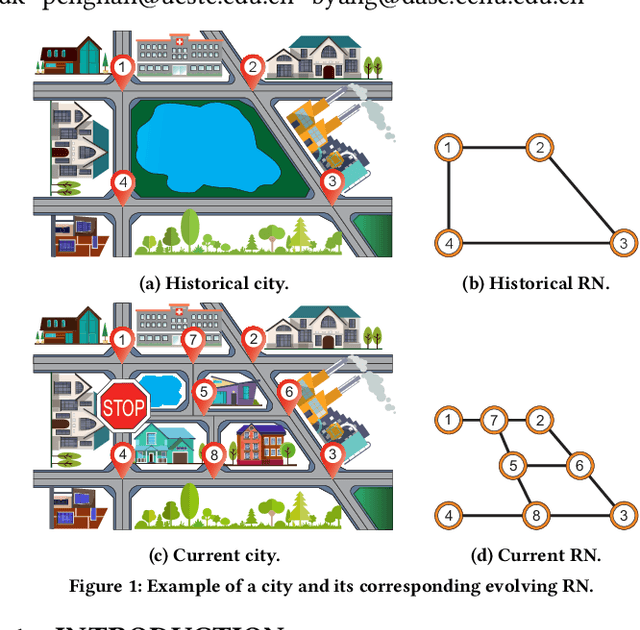
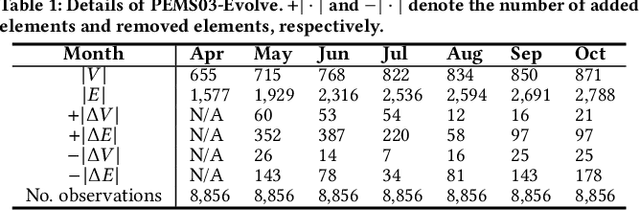
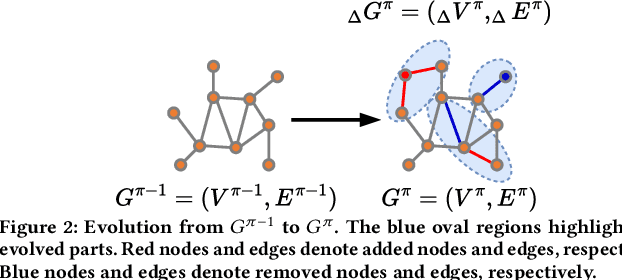
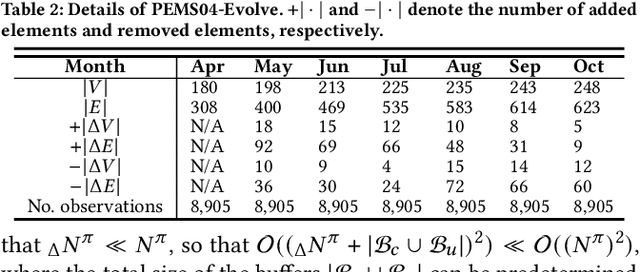
Due to the global trend towards urbanization, people increasingly move to and live in cities that then continue to grow. Traffic forecasting plays an important role in the intelligent transportation systems of cities as well as in spatio-temporal data mining. State-of-the-art forecasting is achieved by deep-learning approaches due to their ability to contend with complex spatio-temporal dynamics. However, existing methods assume the input is fixed-topology road networks and static traffic time series. These assumptions fail to align with urbanization, where time series are collected continuously and road networks evolve over time. In such settings, deep-learning models require frequent re-initialization and re-training, imposing high computational costs. To enable much more efficient training without jeopardizing model accuracy, we propose the Topological Evolution-aware Framework (TEAM) for traffic forecasting that incorporates convolution and attention. This combination of mechanisms enables better adaptation to newly collected time series, while being able to maintain learned knowledge from old time series. TEAM features a continual learning module based on the Wasserstein metric that acts as a buffer that can identify the most stable and the most changing network nodes. Then, only data related to stable nodes is employed for re-training when consolidating a model. Further, only data of new nodes and their adjacent nodes as well as data pertaining to changing nodes are used to re-train the model. Empirical studies with two real-world traffic datasets offer evidence that TEAM is capable of much lower re-training costs than existing methods are, without jeopardizing forecasting accuracy.
Sketch: A Toolkit for Streamlining LLM Operations
Sep 05, 2024



Large language models (LLMs) represented by GPT family have achieved remarkable success. The characteristics of LLMs lie in their ability to accommodate a wide range of tasks through a generative approach. However, the flexibility of their output format poses challenges in controlling and harnessing the model's outputs, thereby constraining the application of LLMs in various domains. In this work, we present Sketch, an innovative toolkit designed to streamline LLM operations across diverse fields. Sketch comprises the following components: (1) a suite of task description schemas and prompt templates encompassing various NLP tasks; (2) a user-friendly, interactive process for building structured output LLM services tailored to various NLP tasks; (3) an open-source dataset for output format control, along with tools for dataset construction; and (4) an open-source model based on LLaMA3-8B-Instruct that adeptly comprehends and adheres to output formatting instructions. We anticipate this initiative to bring considerable convenience to LLM users, achieving the goal of ''plug-and-play'' for various applications. The components of Sketch will be progressively open-sourced at https://github.com/cofe-ai/Sketch.
Open-domain Implicit Format Control for Large Language Model Generation
Aug 08, 2024
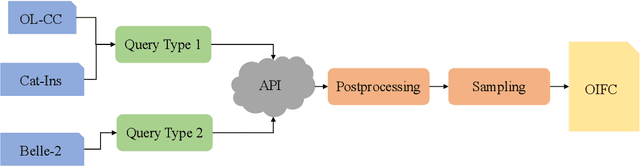
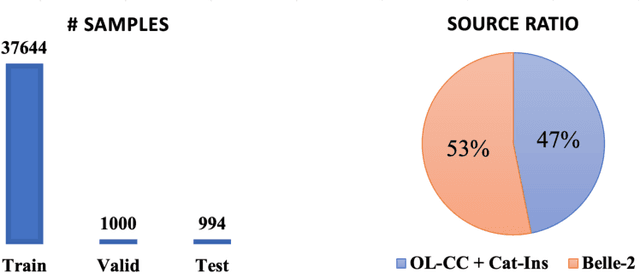

Controlling the format of outputs generated by large language models (LLMs) is a critical functionality in various applications. Current methods typically employ constrained decoding with rule-based automata or fine-tuning with manually crafted format instructions, both of which struggle with open-domain format requirements. To address this limitation, we introduce a novel framework for controlled generation in LLMs, leveraging user-provided, one-shot QA pairs. This study investigates LLMs' capabilities to follow open-domain, one-shot constraints and replicate the format of the example answers. We observe that this is a non-trivial problem for current LLMs. We also develop a dataset collection methodology for supervised fine-tuning that enhances the open-domain format control of LLMs without degrading output quality, as well as a benchmark on which we evaluate both the helpfulness and format correctness of LLM outputs. The resulting datasets, named OIFC-SFT, along with the related code, will be made publicly available at https://github.com/cofe-ai/OIFC.
PORCA: Root Cause Analysis with Partially
Jul 08, 2024



Root Cause Analysis (RCA) aims at identifying the underlying causes of system faults by uncovering and analyzing the causal structure from complex systems. It has been widely used in many application domains. Reliable diagnostic conclusions are of great importance in mitigating system failures and financial losses. However, previous studies implicitly assume a full observation of the system, which neglect the effect of partial observation (i.e., missing nodes and latent malfunction). As a result, they fail in deriving reliable RCA results. In this paper, we unveil the issues of unobserved confounders and heterogeneity in partial observation and come up with a new problem of root cause analysis with partially observed data. To achieve this, we propose PORCA, a novel RCA framework which can explore reliable root causes under both unobserved confounders and unobserved heterogeneity. PORCA leverages magnified score-based causal discovery to efficiently optimize acyclic directed mixed graph under unobserved confounders. In addition, we also develop a heterogeneity-aware scheduling strategy to provide adaptive sample weights. Extensive experimental results on one synthetic and two real-world datasets demonstrate the effectiveness and superiority of the proposed framework.