 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Progression of Memory State in Robotic Manipulation: An Object-Centric Perspective
Nov 18, 2025As embodied agents operate in increasingly complex environments, the ability to perceive, track, and reason about individual object instances over time becomes essential, especially in tasks requiring sequenced interactions with visually similar objects. In these non-Markovian settings, key decision cues are often hidden in object-specific histories rather than the current scene. Without persistent memory of prior interactions (what has been interacted with, where it has been, or how it has changed) visuomotor policies may fail, repeat past actions, or overlook completed ones. To surface this challenge, we introduce LIBERO-Mem, a non-Markovian task suite for stress-testing robotic manipulation under object-level partial observability. It combines short- and long-horizon object tracking with temporally sequenced subgoals, requiring reasoning beyond the current frame. However, vision-language-action (VLA) models often struggle in such settings, with token scaling quickly becoming intractable even for tasks spanning just a few hundred frames. We propose Embodied-SlotSSM, a slot-centric VLA framework built for temporal scalability. It maintains spatio-temporally consistent slot identities and leverages them through two mechanisms: (1) slot-state-space modeling for reconstructing short-term history, and (2) a relational encoder to align the input tokens with action decoding. Together, these components enable temporally grounded, context-aware action prediction. Experiments show Embodied-SlotSSM's baseline performance on LIBERO-Mem and general tasks, offering a scalable solution for non-Markovian reasoning in object-centric robotic policies.
SlotVLA: Towards Modeling of Object-Relation Representations in Robotic Manipulation
Nov 10, 2025Inspired by how humans reason over discrete objects and their relationships, we explore whether compact object-centric and object-relation representations can form a foundation for multitask robotic manipulation. Most existing robotic multitask models rely on dense embeddings that entangle both object and background cues, raising concerns about both efficiency and interpretability. In contrast, we study object-relation-centric representations as a pathway to more structured, efficient, and explainable visuomotor control. Our contributions are two-fold. First, we introduce LIBERO+, a fine-grained benchmark dataset designed to enable and evaluate object-relation reasoning in robotic manipulation. Unlike prior datasets, LIBERO+ provides object-centric annotations that enrich demonstrations with box- and mask-level labels as well as instance-level temporal tracking, supporting compact and interpretable visuomotor representations. Second, we propose SlotVLA, a slot-attention-based framework that captures both objects and their relations for action decoding. It uses a slot-based visual tokenizer to maintain consistent temporal object representations, a relation-centric decoder to produce task-relevant embeddings, and an LLM-driven module that translates these embeddings into executable actions. Experiments on LIBERO+ demonstrate that object-centric slot and object-relation slot representations drastically reduce the number of required visual tokens, while providing competitive generalization. Together, LIBERO+ and SlotVLA provide a compact, interpretable, and effective foundation for advancing object-relation-centric robotic manipulation.
An Encode-then-Decompose Approach to Unsupervised Time Series Anomaly Detection on Contaminated Training Data--Extended Version
Oct 21, 2025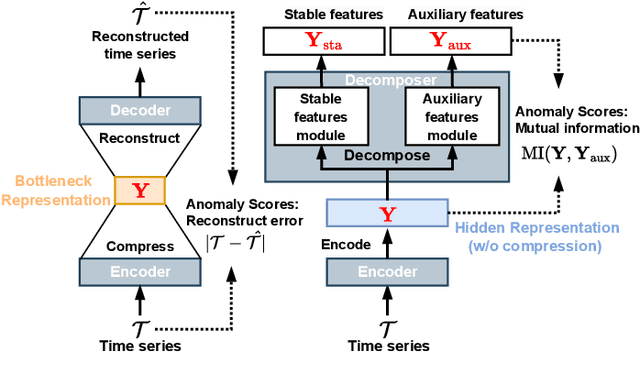
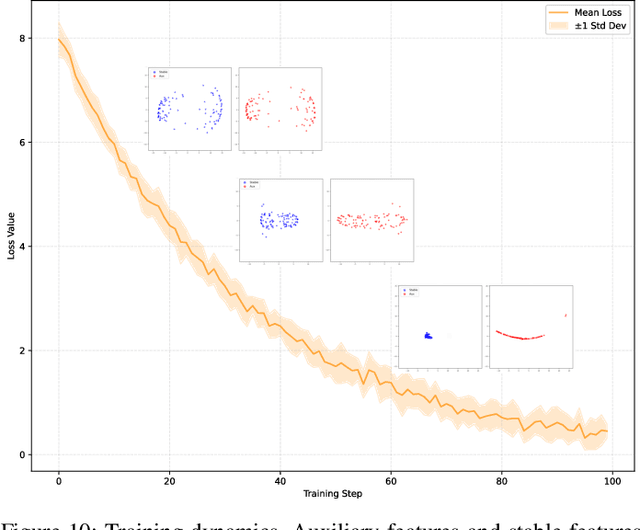
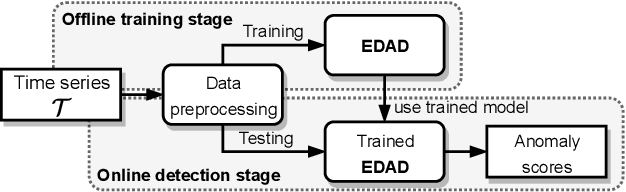
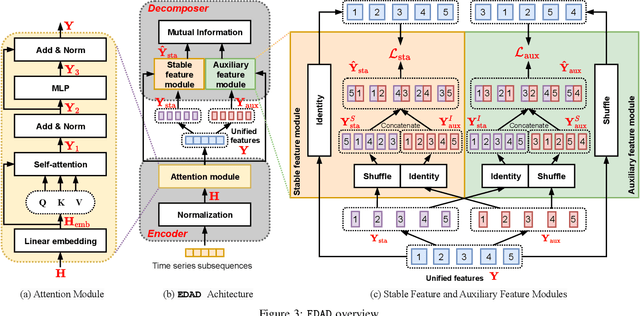
Time series anomaly detection is important in modern large-scale systems and is applied in a variety of domains to analyze and monitor the operation of diverse systems. Unsupervised approaches have received widespread interest, as they do not require anomaly labels during training, thus avoiding potentially high costs and having wider applications. Among these, autoencoders have received extensive attention. They use reconstruction errors from compressed representations to define anomaly scores. However, representations learned by autoencoders are sensitive to anomalies in training time series, causing reduced accuracy. We propose a novel encode-then-decompose paradigm, where we decompose the encoded representation into stable and auxiliary representations, thereby enhancing the robustness when training with contaminated time series. In addition, we propose a novel mutual information based metric to replace the reconstruction errors for identifying anomalies. Our proposal demonstrates competitive or state-of-the-art performance on eight commonly used multi- and univariate time series benchmarks and exhibits robustness to time series with different contamination ratios.
TEAM: Topological Evolution-aware Framework for Traffic Forecasting--Extended Version
Oct 24, 2024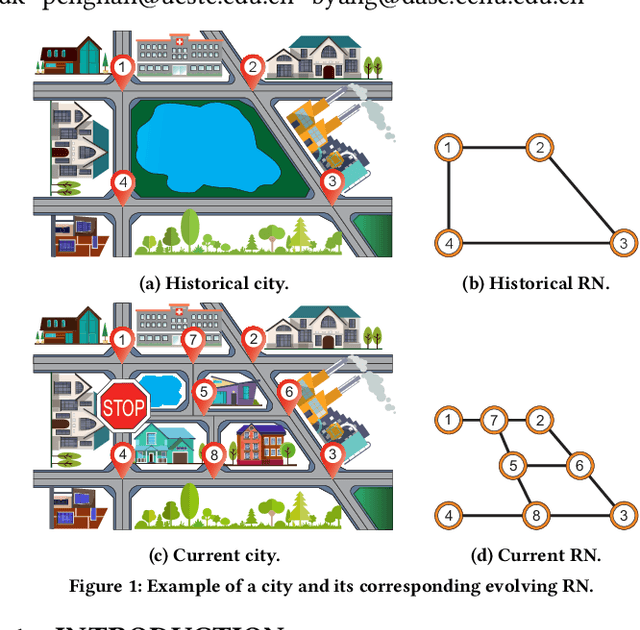
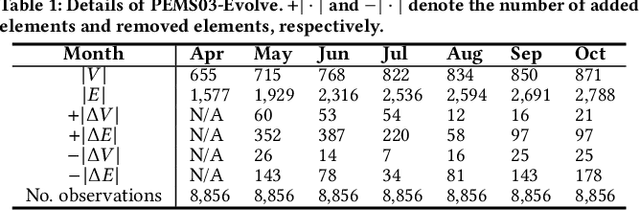
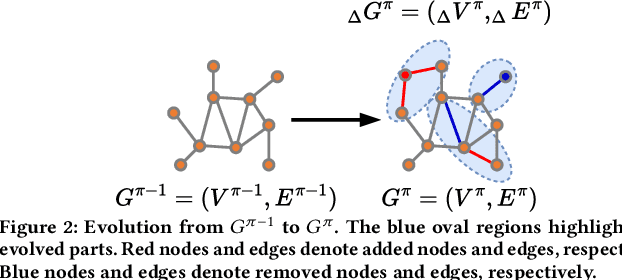
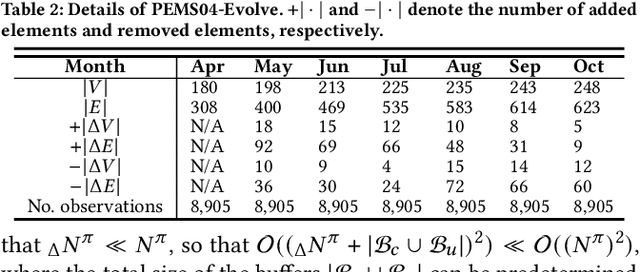
Due to the global trend towards urbanization, people increasingly move to and live in cities that then continue to grow. Traffic forecasting plays an important role in the intelligent transportation systems of cities as well as in spatio-temporal data mining. State-of-the-art forecasting is achieved by deep-learning approaches due to their ability to contend with complex spatio-temporal dynamics. However, existing methods assume the input is fixed-topology road networks and static traffic time series. These assumptions fail to align with urbanization, where time series are collected continuously and road networks evolve over time. In such settings, deep-learning models require frequent re-initialization and re-training, imposing high computational costs. To enable much more efficient training without jeopardizing model accuracy, we propose the Topological Evolution-aware Framework (TEAM) for traffic forecasting that incorporates convolution and attention. This combination of mechanisms enables better adaptation to newly collected time series, while being able to maintain learned knowledge from old time series. TEAM features a continual learning module based on the Wasserstein metric that acts as a buffer that can identify the most stable and the most changing network nodes. Then, only data related to stable nodes is employed for re-training when consolidating a model. Further, only data of new nodes and their adjacent nodes as well as data pertaining to changing nodes are used to re-train the model. Empirical studies with two real-world traffic datasets offer evidence that TEAM is capable of much lower re-training costs than existing methods are, without jeopardizing forecasting accuracy.
QCore: Data-Efficient, On-Device Continual Calibration for Quantized Models -- Extended Version
Apr 22, 2024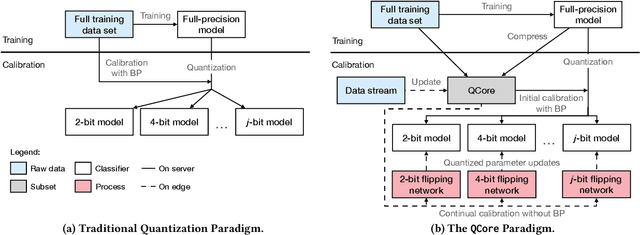

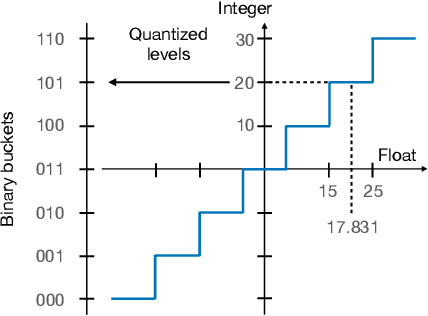
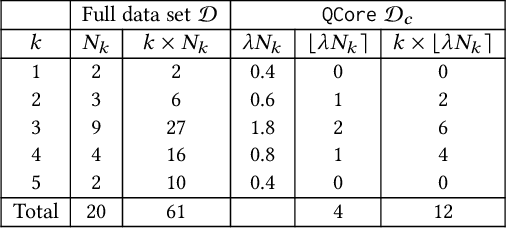
We are witnessing an increasing availability of streaming data that may contain valuable information on the underlying processes. It is thus attractive to be able to deploy machine learning models on edge devices near sensors such that decisions can be made instantaneously, rather than first having to transmit incoming data to servers. To enable deployment on edge devices with limited storage and computational capabilities, the full-precision parameters in standard models can be quantized to use fewer bits. The resulting quantized models are then calibrated using back-propagation and full training data to ensure accuracy. This one-time calibration works for deployments in static environments. However, model deployment in dynamic edge environments call for continual calibration to adaptively adjust quantized models to fit new incoming data, which may have different distributions. The first difficulty in enabling continual calibration on the edge is that the full training data may be too large and thus not always available on edge devices. The second difficulty is that the use of back-propagation on the edge for repeated calibration is too expensive. We propose QCore to enable continual calibration on the edge. First, it compresses the full training data into a small subset to enable effective calibration of quantized models with different bit-widths. We also propose means of updating the subset when new streaming data arrives to reflect changes in the environment, while not forgetting earlier training data. Second, we propose a small bit-flipping network that works with the subset to update quantized model parameters, thus enabling efficient continual calibration without back-propagation. An experimental study, conducted with real-world data in a continual learning setting, offers insight into the properties of QCore and shows that it is capable of outperforming strong baseline methods.
WAVER: Writing-style Agnostic Video Retrieval via Distilling Vision-Language Models Through Open-Vocabulary Knowledge
Dec 27, 2023Text-video retrieval, a prominent sub-field within the domain of multimodal information retrieval, has witnessed remarkable growth in recent years. However, existing methods assume video scenes are consistent with unbiased descriptions. These limitations fail to align with real-world scenarios since descriptions can be influenced by annotator biases, diverse writing styles, and varying textual perspectives. To overcome the aforementioned problems, we introduce WAVER, a cross-domain knowledge distillation framework via vision-language models through open-vocabulary knowledge designed to tackle the challenge of handling different writing styles in video descriptions. WAVER capitalizes on the open-vocabulary properties that lie in pre-trained vision-language models and employs an implicit knowledge distillation approach to transfer text-based knowledge from a teacher model to a vision-based student. Empirical studies conducted across four standard benchmark datasets, encompassing various settings, provide compelling evidence that WAVER can achieve state-of-the-art performance in text-video retrieval task while handling writing-style variations.
LightTS: Lightweight Time Series Classification with Adaptive Ensemble Distillation -- Extended Version
Feb 24, 2023Due to the sweeping digitalization of processes, increasingly vast amounts of time series data are being produced. Accurate classification of such time series facilitates decision making in multiple domains. State-of-the-art classification accuracy is often achieved by ensemble learning where results are synthesized from multiple base models. This characteristic implies that ensemble learning needs substantial computing resources, preventing their use in resource-limited environments, such as in edge devices. To extend the applicability of ensemble learning, we propose the LightTS framework that compresses large ensembles into lightweight models while ensuring competitive accuracy. First, we propose adaptive ensemble distillation that assigns adaptive weights to different base models such that their varying classification capabilities contribute purposefully to the training of the lightweight model. Second, we propose means of identifying Pareto optimal settings w.r.t. model accuracy and model size, thus enabling users with a space budget to select the most accurate lightweight model. We report on experiments using 128 real-world time series sets and different types of base models that justify key decisions in the design of LightTS and provide evidence that LightTS is able to outperform competitors.
A Comparative Study on Unsupervised Anomaly Detection for Time Series: Experiments and Analysis
Sep 10, 2022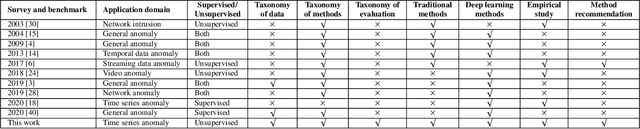
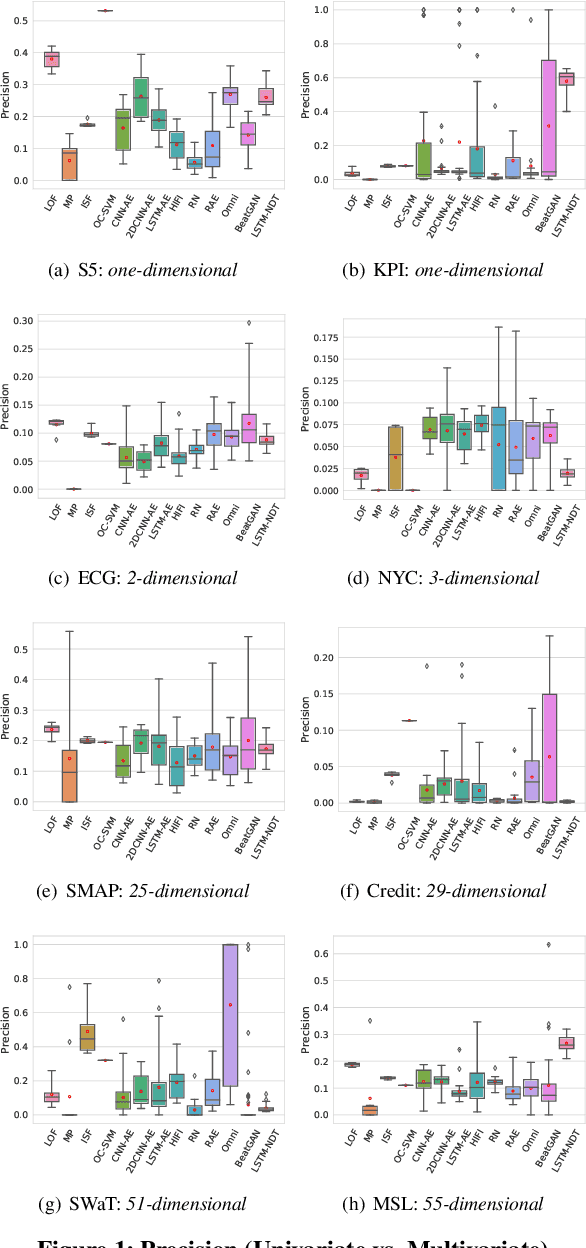
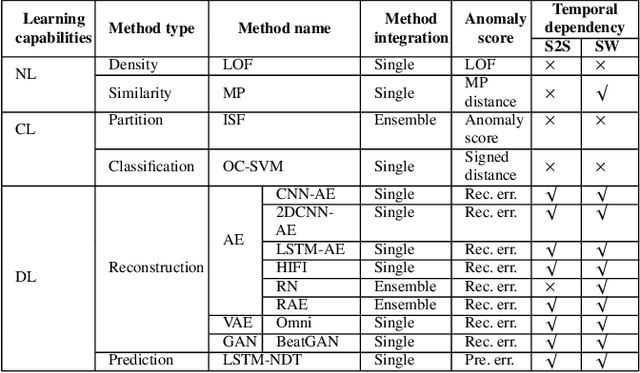

The continued digitization of societal processes translates into a proliferation of time series data that cover applications such as fraud detection, intrusion detection, and energy management, where anomaly detection is often essential to enable reliability and safety. Many recent studies target anomaly detection for time series data. Indeed, area of time series anomaly detection is characterized by diverse data, methods, and evaluation strategies, and comparisons in existing studies consider only part of this diversity, which makes it difficult to select the best method for a particular problem setting. To address this shortcoming, we introduce taxonomies for data, methods, and evaluation strategies, provide a comprehensive overview of unsupervised time series anomaly detection using the taxonomies, and systematically evaluate and compare state-of-the-art traditional as well as deep learning techniques. In the empirical study using nine publicly available datasets, we apply the most commonly-used performance evaluation metrics to typical methods under a fair implementation standard. Based on the structuring offered by the taxonomies, we report on empirical studies and provide guidelines, in the form of comparative tables, for choosing the methods most suitable for particular application settings. Finally, we propose research directions for this dynamic field.
Triformer: Triangular, Variable-Specific Attentions for Long Sequence Multivariate Time Series Forecasting--Full Version
Apr 28, 2022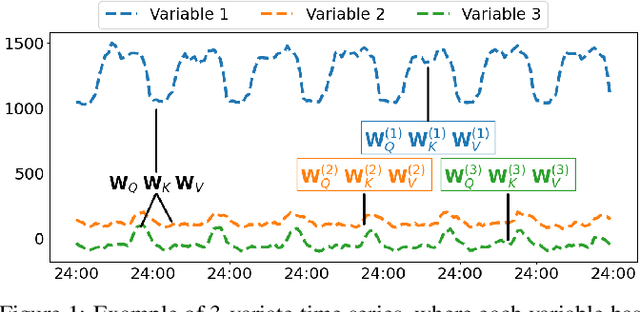
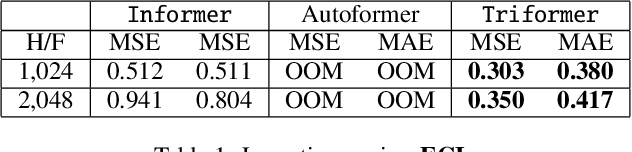
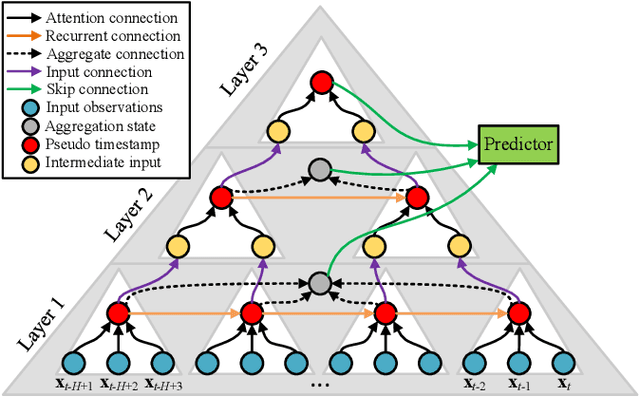
A variety of real-world applications rely on far future information to make decisions, thus calling for efficient and accurate long sequence multivariate time series forecasting. While recent attention-based forecasting models show strong abilities in capturing long-term dependencies, they still suffer from two key limitations. First, canonical self attention has a quadratic complexity w.r.t. the input time series length, thus falling short in efficiency. Second, different variables' time series often have distinct temporal dynamics, which existing studies fail to capture, as they use the same model parameter space, e.g., projection matrices, for all variables' time series, thus falling short in accuracy. To ensure high efficiency and accuracy, we propose Triformer, a triangular, variable-specific attention. (i) Linear complexity: we introduce a novel patch attention with linear complexity. When stacking multiple layers of the patch attentions, a triangular structure is proposed such that the layer sizes shrink exponentially, thus maintaining linear complexity. (ii) Variable-specific parameters: we propose a light-weight method to enable distinct sets of model parameters for different variables' time series to enhance accuracy without compromising efficiency and memory usage. Strong empirical evidence on four datasets from multiple domains justifies our design choices, and it demonstrates that Triformer outperforms state-of-the-art methods w.r.t. both accuracy and efficiency. This is an extended version of "Triformer: Triangular, Variable-Specific Attentions for Long Sequence Multivariate Time Series Forecasting", to appear in IJCAI 2022 [Cirstea et al., 2022a], including additional experimental results.
Robust and Explainable Autoencoders for Unsupervised Time Series Outlier Detection---Extended Version
Apr 07, 2022



Time series data occurs widely, and outlier detection is a fundamental problem in data mining, which has numerous applications. Existing autoencoder-based approaches deliver state-of-the-art performance on challenging real-world data but are vulnerable to outliers and exhibit low explainability. To address these two limitations, we propose robust and explainable unsupervised autoencoder frameworks that decompose an input time series into a clean time series and an outlier time series using autoencoders. Improved explainability is achieved because clean time series are better explained with easy-to-understand patterns such as trends and periodicities. We provide insight into this by means of a post-hoc explainability analysis and empirical studies. In addition, since outliers are separated from clean time series iteratively, our approach offers improved robustness to outliers, which in turn improves accuracy. We evaluate our approach on five real-world datasets and report improvements over the state-of-the-art approaches in terms of robustness and explainability. This is an extended version of "Robust and Explainable Autoencoders for Unsupervised Time Series Outlier Detection", to appear in IEEE ICDE 2022.