 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable AI Needs to Externalize Implicit Knowledge: A Human-AI Collaboration Perspective
May 03, 2026This position paper argues that reliable AI requires infrastructure for human validation of implicit knowledge. AI learns from both explicit knowledge (papers, documentation, structured databases) and implicit knowledge (reasoning patterns, debugging processes, intermediate steps). Implicit knowledge remains unexternalized because documentation cost exceeds perceived value -- yet AI learns from it indiscriminately, acquiring both beneficial patterns and harmful biases. Current reliability methods can only verify explicit knowledge against sources, creating a fundamental gap: the most valuable AI capabilities (reasoning, judgment, intuition) are precisely those we cannot verify. We propose Knowledge Objects (KOs) -- structured artifacts that externalize implicit knowledge into forms humans can inspect, verify, and endorse. KOs transform verification economics: what was previously too costly to verify becomes feasible, enabling accumulated human validation to improve reliability over time.
DiSGMM: A Method for Time-varying Microscopic Weight Completion on Road Networks
Mar 31, 2026Microscopic road-network weights represent fine-grained, time-varying traffic conditions obtained from individual vehicles. An example is travel speeds associated with road segments as vehicles traverse them. These weights support tasks including traffic microsimulation and vehicle routing with reliability guarantees. We study the problem of time-varying microscopic weight completion. During a time slot, the available weights typically cover only some road segments. Weight completion recovers distributions for the weights of every road segment at the current time slot. This problem involves two challenges: (i) contending with two layers of sparsity, where weights are missing at both the network layer (many road segments lack weights) and the segment layer (a segment may have insufficient weights to enable accurate distribution estimation); and (ii) achieving a weight distribution representation that is closed-form and can capture complex conditions flexibly, including heavy tails and multiple clusters. To address these challenges, we propose DiSGMM that combines sparsity-aware embeddings with spatiotemporal modeling to leverage sparse known weights alongside learned segment properties and long-range correlations for distribution estimation. DiSGMM represents distributions of microscopic weights as learnable Gaussian mixture models, providing closed-form distributions capable of capturing complex conditions flexibly. Experiments on two real-world datasets show that DiSGMM can outperform state-of-the-art methods.
PATRA: Pattern-Aware Alignment and Balanced Reasoning for Time Series Question Answering
Feb 26, 2026Time series reasoning demands both the perception of complex dynamics and logical depth. However, existing LLM-based approaches exhibit two limitations: they often treat time series merely as text or images, failing to capture the patterns like trends and seasonalities needed to answer specific questions; and when trained on a mix of simple and complex tasks, simpler objectives often dominate the learning process, hindering the development of deep reasoning capabilities. To address these limitations, we propose the Pattern-Aware Alignment and Balanced Reasoning model (PATRA), introducing a pattern-aware mechanism that extracts trend and seasonality patterns from time series to achieve deep alignment. Furthermore, we design a task-aware balanced reward to harmonize learning across tasks of varying difficulty, incentivizing the generation of coherent Chains of Thought. Extensive experiments show that PATRA outperforms strong baselines across diverse Time Series Question Answering (TSQA) tasks, demonstrating superior cross-modal understanding and reasoning capability.
Replacing Multi-Step Assembly of Data Preparation Pipelines with One-Step LLM Pipeline Generation for Table QA
Feb 26, 2026Table Question Answering (TQA) aims to answer natural language questions over structured tables. Large Language Models (LLMs) enable promising solutions to this problem, with operator-centric solutions that generate table manipulation pipelines in a multi-step manner offering state-of-the-art performance. However, these solutions rely on multiple LLM calls, resulting in prohibitive latencies and computational costs. We propose Operation-R1, the first framework that trains lightweight LLMs (e.g., Qwen-4B/1.7B) via a novel variant of reinforcement learning with verifiable rewards to produce high-quality data-preparation pipelines for TQA in a single inference step. To train such an LLM, we first introduce a self-supervised rewarding mechanism to automatically obtain fine-grained pipeline-wise supervision signals for LLM training. We also propose variance-aware group resampling to mitigate training instability. To further enhance robustness of pipeline generation, we develop two complementary mechanisms: operation merge, which filters spurious operations through multi-candidate consensus, and adaptive rollback, which offers runtime protection against information loss in data transformation. Experiments on two benchmark datasets show that, with the same LLM backbone, Operation-R1 achieves average absolute accuracy gains of 9.55 and 6.08 percentage points over multi-step preparation baselines, with 79\% table compression and a 2.2$\times$ reduction in monetary cost.
CLEAR: A Knowledge-Centric Vessel Trajectory Analysis Platform
Feb 09, 2026Vessel trajectory data from the Automatic Identification System (AIS) is used widely in maritime analytics. Yet, analysis is difficult for non-expert users due to the incompleteness and complexity of AIS data. We present CLEAR, a knowledge-centric vessel trajectory analysis platform that aims to overcome these barriers. By leveraging the reasoning and generative capabilities of Large Language Models (LLMs), CLEAR transforms raw AIS data into complete, interpretable, and easily explorable vessel trajectories through a Structured Data-derived Knowledge Graph (SD-KG). As part of the demo, participants can configure parameters to automatically download and process AIS data, observe how trajectories are completed and annotated, inspect both raw and imputed segments together with their SD-KG evidence, and interactively explore the SD-KG through a dedicated graph viewer, gaining an intuitive and transparent understanding of vessel movements.
TimeART: Towards Agentic Time Series Reasoning via Tool-Augmentation
Jan 20, 2026Time series data widely exist in real-world cyber-physical systems. Though analyzing and interpreting them contributes to significant values, e.g, disaster prediction and financial risk control, current workflows mainly rely on human data scientists, which requires significant labor costs and lacks automation. To tackle this, we introduce TimeART, a framework fusing the analytical capability of strong out-of-the-box tools and the reasoning capability of Large Language Models (LLMs), which serves as a fully agentic data scientist for Time Series Question Answering (TSQA). To teach the LLM-based Time Series Reasoning Models (TSRMs) strategic tool-use, we also collect a 100k expert trajectory corpus called TimeToolBench. To enhance TSRMs' generalization capability, we then devise a four-stage training strategy, which boosts TSRMs through learning from their own early experiences and self-reflections. Experimentally, we train an 8B TSRM on TimeToolBench and equip it with the TimeART framework, and it achieves consistent state-of-the-art performance on multiple TSQA tasks, which pioneers a novel approach towards agentic time series reasoning.
VISTA: Knowledge-Driven Interpretable Vessel Trajectory Imputation via Large Language Models
Jan 11, 2026The Automatic Identification System provides critical information for maritime navigation and safety, yet its trajectories are often incomplete due to signal loss or deliberate tampering. Existing imputation methods emphasize trajectory recovery, paying limited attention to interpretability and failing to provide underlying knowledge that benefits downstream tasks such as anomaly detection and route planning. We propose knowledge-driven interpretable vessel trajectory imputation (VISTA), the first trajectory imputation framework that offers interpretability while simultaneously providing underlying knowledge to support downstream analysis. Specifically, we first define underlying knowledge as a combination of Structured Data-derived Knowledge (SDK) distilled from AIS data and Implicit LLM Knowledge acquired from large-scale Internet corpora. Second, to manage and leverage the SDK effectively at scale, we develop a data-knowledge-data loop that employs a Structured Data-derived Knowledge Graph for SDK extraction and knowledge-driven trajectory imputation. Third, to efficiently process large-scale AIS data, we introduce a workflow management layer that coordinates the end-to-end pipeline, enabling parallel knowledge extraction and trajectory imputation with anomaly handling and redundancy elimination. Experiments on two large AIS datasets show that VISTA is capable of state-of-the-art imputation accuracy and computational efficiency, improving over state-of-the-art baselines by 5%-94% and reducing time cost by 51%-93%, while producing interpretable knowledge cues that benefit downstream tasks. The source code and implementation details of VISTA are publicly available.
MovSemCL: Movement-Semantics Contrastive Learning for Trajectory Similarity
Nov 15, 2025Trajectory similarity computation is fundamental functionality that is used for, e.g., clustering, prediction, and anomaly detection. However, existing learning-based methods exhibit three key limitations: (1) insufficient modeling of trajectory semantics and hierarchy, lacking both movement dynamics extraction and multi-scale structural representation; (2) high computational costs due to point-wise encoding; and (3) use of physically implausible augmentations that distort trajectory semantics. To address these issues, we propose MovSemCL, a movement-semantics contrastive learning framework for trajectory similarity computation. MovSemCL first transforms raw GPS trajectories into movement-semantics features and then segments them into patches. Next, MovSemCL employs intra- and inter-patch attentions to encode local as well as global trajectory patterns, enabling efficient hierarchical representation and reducing computational costs. Moreover, MovSemCL includes a curvature-guided augmentation strategy that preserves informative segments (e.g., turns and intersections) and masks redundant ones, generating physically plausible augmented views. Experiments on real-world datasets show that MovSemCL is capable of outperforming state-of-the-art methods, achieving mean ranks close to the ideal value of 1 at similarity search tasks and improvements by up to 20.3% at heuristic approximation, while reducing inference latency by up to 43.4%.
An Encode-then-Decompose Approach to Unsupervised Time Series Anomaly Detection on Contaminated Training Data--Extended Version
Oct 21, 2025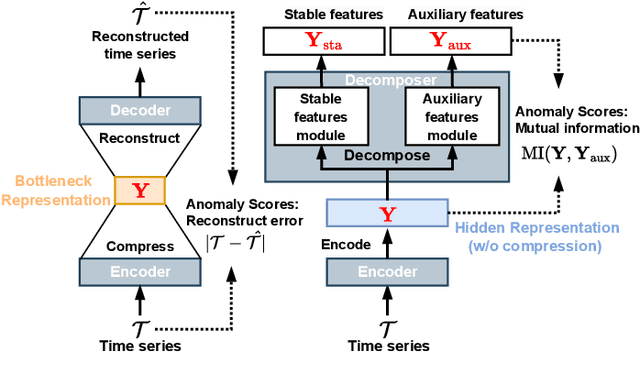
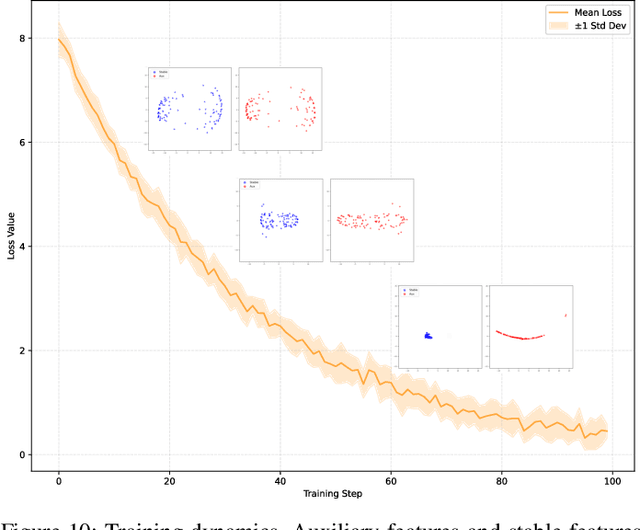
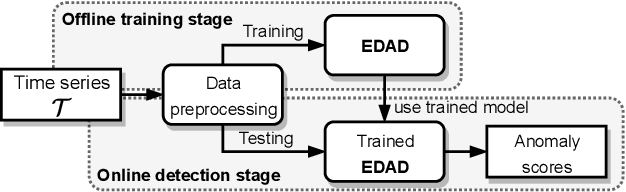
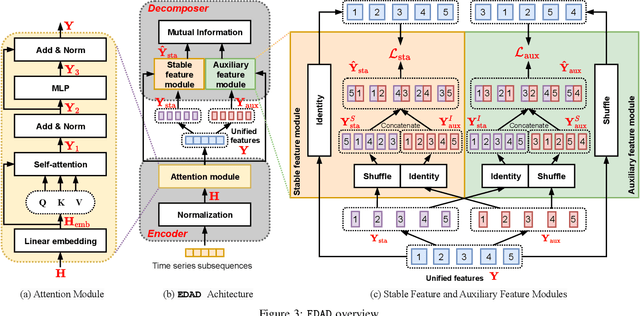
Time series anomaly detection is important in modern large-scale systems and is applied in a variety of domains to analyze and monitor the operation of diverse systems. Unsupervised approaches have received widespread interest, as they do not require anomaly labels during training, thus avoiding potentially high costs and having wider applications. Among these, autoencoders have received extensive attention. They use reconstruction errors from compressed representations to define anomaly scores. However, representations learned by autoencoders are sensitive to anomalies in training time series, causing reduced accuracy. We propose a novel encode-then-decompose paradigm, where we decompose the encoded representation into stable and auxiliary representations, thereby enhancing the robustness when training with contaminated time series. In addition, we propose a novel mutual information based metric to replace the reconstruction errors for identifying anomalies. Our proposal demonstrates competitive or state-of-the-art performance on eight commonly used multi- and univariate time series benchmarks and exhibits robustness to time series with different contamination ratios.
Advancing Knowledge Tracing by Exploring Follow-up Performance Trends
Aug 11, 2025


Intelligent Tutoring Systems (ITS), such as Massive Open Online Courses, offer new opportunities for human learning. At the core of such systems, knowledge tracing (KT) predicts students' future performance by analyzing their historical learning activities, enabling an accurate evaluation of students' knowledge states over time. We show that existing KT methods often encounter correlation conflicts when analyzing the relationships between historical learning sequences and future performance. To address such conflicts, we propose to extract so-called Follow-up Performance Trends (FPTs) from historical ITS data and to incorporate them into KT. We propose a method called Forward-Looking Knowledge Tracing (FINER) that combines historical learning sequences with FPTs to enhance student performance prediction accuracy. FINER constructs learning patterns that facilitate the retrieval of FPTs from historical ITS data in linear time; FINER includes a novel similarity-aware attention mechanism that aggregates FPTs based on both frequency and contextual similarity; and FINER offers means of combining FPTs and historical learning sequences to enable more accurate prediction of student future performance. Experiments on six real-world datasets show that FINER can outperform ten state-of-the-art KT methods, increasing accuracy by 8.74% to 84.85%.