 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-Point Joint Representation for Effective Trajectory Similarity Learning
Nov 17, 2025Recent learning-based methods have reduced the computational complexity of traditional trajectory similarity computation, but state-of-the-art (SOTA) methods still fail to leverage the comprehensive spectrum of trajectory information for similarity modeling. To tackle this problem, we propose \textbf{RePo}, a novel method that jointly encodes \textbf{Re}gion-wise and \textbf{Po}int-wise features to capture both spatial context and fine-grained moving patterns. For region-wise representation, the GPS trajectories are first mapped to grid sequences, and spatial context are captured by structural features and semantic context enriched by visual features. For point-wise representation, three lightweight expert networks extract local, correlation, and continuous movement patterns from dense GPS sequences. Then, a router network adaptively fuses the learned point-wise features, which are subsequently combined with region-wise features using cross-attention to produce the final trajectory embedding. To train RePo, we adopt a contrastive loss with hard negative samples to provide similarity ranking supervision. Experiment results show that RePo achieves an average accuracy improvement of 22.2\% over SOTA baselines across all evaluation metrics.
Efficient Model-Agnostic Continual Learning for Next POI Recommendation
Nov 12, 2025Next point-of-interest (POI) recommendation improves personalized location-based services by predicting users' next destinations based on their historical check-ins. However, most existing methods rely on static datasets and fixed models, limiting their ability to adapt to changes in user behavior over time. To address this limitation, we explore a novel task termed continual next POI recommendation, where models dynamically adapt to evolving user interests through continual updates. This task is particularly challenging, as it requires capturing shifting user behaviors while retaining previously learned knowledge. Moreover, it is essential to ensure efficiency in update time and memory usage for real-world deployment. To this end, we propose GIRAM (Generative Key-based Interest Retrieval and Adaptive Modeling), an efficient, model-agnostic framework that integrates context-aware sustained interests with recent interests. GIRAM comprises four components: (1) an interest memory to preserve historical preferences; (2) a context-aware key encoding module for unified interest key representation; (3) a generative key-based retrieval module to identify diverse and relevant sustained interests; and (4) an adaptive interest update and fusion module to update the interest memory and balance sustained and recent interests. In particular, GIRAM can be seamlessly integrated with existing next POI recommendation models. Experiments on three real-world datasets demonstrate that GIRAM consistently outperforms state-of-the-art methods while maintaining high efficiency in both update time and memory consumption.
Blurred Encoding for Trajectory Representation Learning
Nov 12, 2025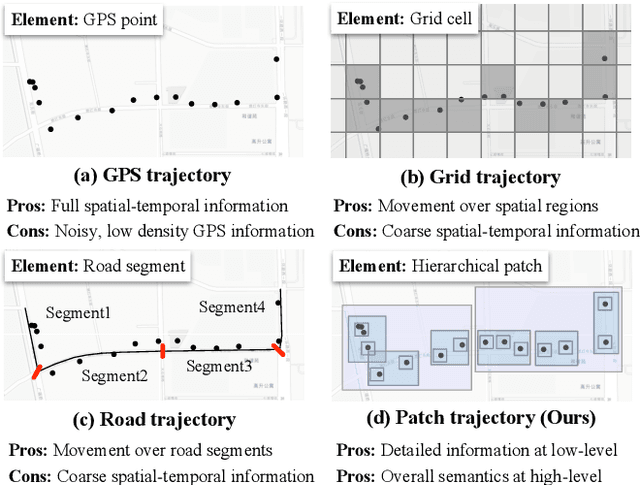

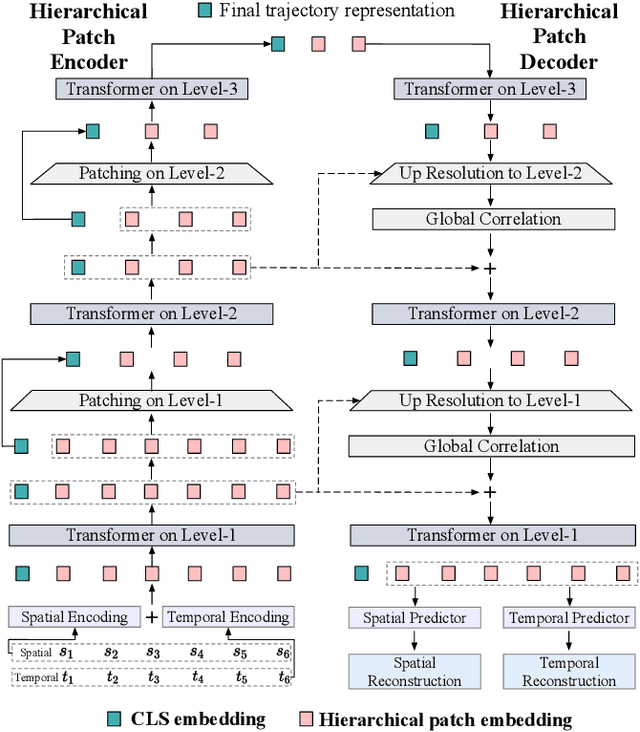
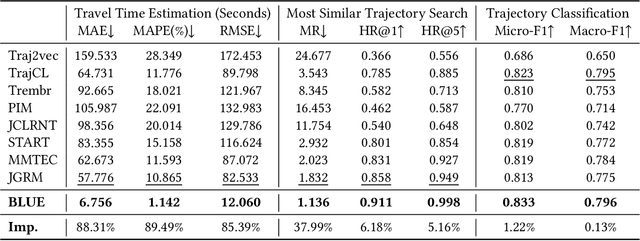
Trajectory representation learning (TRL) maps trajectories to vector embeddings and facilitates tasks such as trajectory classification and similarity search. State-of-the-art (SOTA) TRL methods transform raw GPS trajectories to grid or road trajectories to capture high-level travel semantics, i.e., regions and roads. However, they lose fine-grained spatial-temporal details as multiple GPS points are grouped into a single grid cell or road segment. To tackle this problem, we propose the BLUrred Encoding method, dubbed BLUE, which gradually reduces the precision of GPS coordinates to create hierarchical patches with multiple levels. The low-level patches are small and preserve fine-grained spatial-temporal details, while the high-level patches are large and capture overall travel patterns. To complement different patch levels with each other, our BLUE is an encoder-decoder model with a pyramid structure. At each patch level, a Transformer is used to learn the trajectory embedding at the current level, while pooling prepares inputs for the higher level in the encoder, and up-resolution provides guidance for the lower level in the decoder. BLUE is trained using the trajectory reconstruction task with the MSE loss. We compare BLUE with 8 SOTA TRL methods for 3 downstream tasks, the results show that BLUE consistently achieves higher accuracy than all baselines, outperforming the best-performing baselines by an average of 30.90%. Our code is available at https://github.com/slzhou-xy/BLUE.
CulFiT: A Fine-grained Cultural-aware LLM Training Paradigm via Multilingual Critique Data Synthesis
May 26, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, yet they often exhibit a specific cultural biases, neglecting the values and linguistic diversity of low-resource regions. This cultural bias not only undermines universal equality, but also risks reinforcing stereotypes and perpetuating discrimination. To address this, we propose CulFiT, a novel culturally-aware training paradigm that leverages multilingual data and fine-grained reward modeling to enhance cultural sensitivity and inclusivity. Our approach synthesizes diverse cultural-related questions, constructs critique data in culturally relevant languages, and employs fine-grained rewards to decompose cultural texts into verifiable knowledge units for interpretable evaluation. We also introduce GlobalCultureQA, a multilingual open-ended question-answering dataset designed to evaluate culturally-aware responses in a global context. Extensive experiments on three existing benchmarks and our GlobalCultureQA demonstrate that CulFiT achieves state-of-the-art open-source model performance in cultural alignment and general reasoning.
RED: Effective Trajectory Representation Learning with Comprehensive Information
Nov 22, 2024



Trajectory representation learning (TRL) maps trajectories to vectors that can then be used for various downstream tasks, including trajectory similarity computation, trajectory classification, and travel-time estimation. However, existing TRL methods often produce vectors that, when used in downstream tasks, yield insufficiently accurate results. A key reason is that they fail to utilize the comprehensive information encompassed by trajectories. We propose a self-supervised TRL framework, called RED, which effectively exploits multiple types of trajectory information. Overall, RED adopts the Transformer as the backbone model and masks the constituting paths in trajectories to train a masked autoencoder (MAE). In particular, RED considers the moving patterns of trajectories by employing a Road-aware masking strategy} that retains key paths of trajectories during masking, thereby preserving crucial information of the trajectories. RED also adopts a spatial-temporal-user joint Embedding scheme to encode comprehensive information when preparing the trajectories as model inputs. To conduct training, RED adopts Dual-objective task learning}: the Transformer encoder predicts the next segment in a trajectory, and the Transformer decoder reconstructs the entire trajectory. RED also considers the spatial-temporal correlations of trajectories by modifying the attention mechanism of the Transformer. We compare RED with 9 state-of-the-art TRL methods for 4 downstream tasks on 3 real-world datasets, finding that RED can usually improve the accuracy of the best-performing baseline by over 5%.
Grid and Road Expressions Are Complementary for Trajectory Representation Learning
Nov 22, 2024



Trajectory representation learning (TRL) maps trajectories to vectors that can be used for many downstream tasks. Existing TRL methods use either grid trajectories, capturing movement in free space, or road trajectories, capturing movement in a road network, as input. We observe that the two types of trajectories are complementary, providing either region and location information or providing road structure and movement regularity. Therefore, we propose a novel multimodal TRL method, dubbed GREEN, to jointly utilize Grid and Road trajectory Expressions for Effective representatioN learning. In particular, we transform raw GPS trajectories into both grid and road trajectories and tailor two encoders to capture their respective information. To align the two encoders such that they complement each other, we adopt a contrastive loss to encourage them to produce similar embeddings for the same raw trajectory and design a mask language model (MLM) loss to use grid trajectories to help reconstruct masked road trajectories. To learn the final trajectory representation, a dual-modal interactor is used to fuse the outputs of the two encoders via cross-attention. We compare GREEN with 7 state-of-the-art TRL methods for 3 downstream tasks, finding that GREEN consistently outperforms all baselines and improves the accuracy of the best-performing baseline by an average of 15.99\%.
DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level
Apr 09, 2024



Recommendation systems play a crucial role in various domains, suggesting items based on user behavior.However, the lack of transparency in presenting recommendations can lead to user confusion. In this paper, we introduce Data-level Recommendation Explanation (DRE), a non-intrusive explanation framework for black-box recommendation models.Different from existing methods, DRE does not require any intermediary representations of the recommendation model or latent alignment training, mitigating potential performance issues.We propose a data-level alignment method, leveraging large language models to reason relationships between user data and recommended items.Additionally, we address the challenge of enriching the details of the explanation by introducing target-aware user preference distillation, utilizing item reviews. Experimental results on benchmark datasets demonstrate the effectiveness of the DRE in providing accurate and user-centric explanations, enhancing user engagement with recommended item.