 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyTime: Time Series Forecasting Made Easy
Dec 23, 2024



Time series forecasting has important applications across diverse domains. EasyTime, the system we demonstrate, facilitates easy use of time-series forecasting methods by researchers and practitioners alike. First, EasyTime enables one-click evaluation, enabling researchers to evaluate new forecasting methods using the suite of diverse time series datasets collected in the preexisting time series forecasting benchmark (TFB). This is achieved by leveraging TFB's flexible and consistent evaluation pipeline. Second, when practitioners must perform forecasting on a new dataset, a nontrivial first step is often to find an appropriate forecasting method. EasyTime provides an Automated Ensemble module that combines the promising forecasting methods to yield superior forecasting accuracy compared to individual methods. Third, EasyTime offers a natural language Q&A module leveraging large language models. Given a question like "Which method is best for long term forecasting on time series with strong seasonality?", EasyTime converts the question into SQL queries on the database of results obtained by TFB and then returns an answer in natural language and charts. By demonstrating EasyTime, we intend to show how it is possible to simplify the use of time series forecasting and to offer better support for the development of new generations of time series forecasting methods.
Survey of Natural Language Processing for Education: Taxonomy, Systematic Review, and Future Trends
Jan 31, 2024



Natural Language Processing (NLP) aims to analyze the text via techniques in the computer science field. It serves the applications in healthcare, commerce, and education domains. Particularly, NLP has been applied to the education domain to help teaching and learning. In this survey, we review recent advances in NLP with a focus on solving problems related to the education domain. In detail, we begin with introducing the relevant background. Then, we present the taxonomy of NLP in the education domain. Next, we illustrate the task definition, challenges, and corresponding techniques based on the above taxonomy. After that, we showcase some off-the-shelf demonstrations in this domain and conclude with future directions.
CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure
Oct 12, 2022


Code pre-trained models (CodePTMs) have recently demonstrated significant success in code intelligence. To interpret these models, some probing methods have been applied. However, these methods fail to consider the inherent characteristics of codes. In this paper, to address the problem, we propose a novel probing method CAT-probing to quantitatively interpret how CodePTMs attend code structure. We first denoise the input code sequences based on the token types pre-defined by the compilers to filter those tokens whose attention scores are too small. After that, we define a new metric CAT-score to measure the commonality between the token-level attention scores generated in CodePTMs and the pair-wise distances between corresponding AST nodes. The higher the CAT-score, the stronger the ability of CodePTMs to capture code structure. We conduct extensive experiments to integrate CAT-probing with representative CodePTMs for different programming languages. Experimental results show the effectiveness of CAT-probing in CodePTM interpretation. Our codes and data are publicly available at https://github.com/nchen909/CodeAttention.
GypSum: Learning Hybrid Representations for Code Summarization
Apr 26, 2022
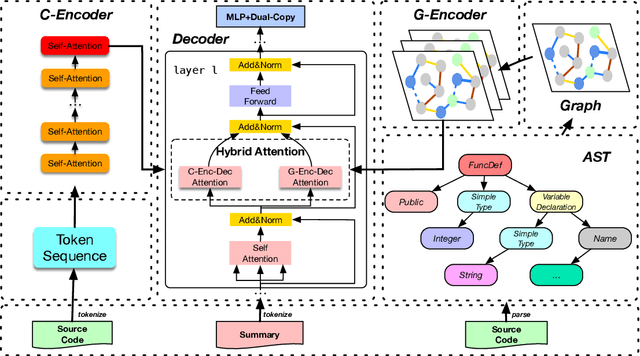
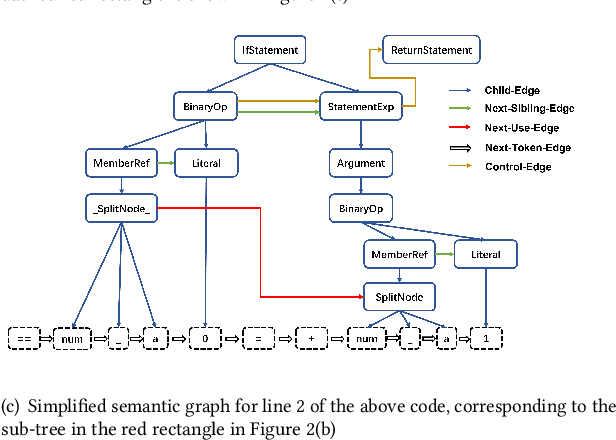
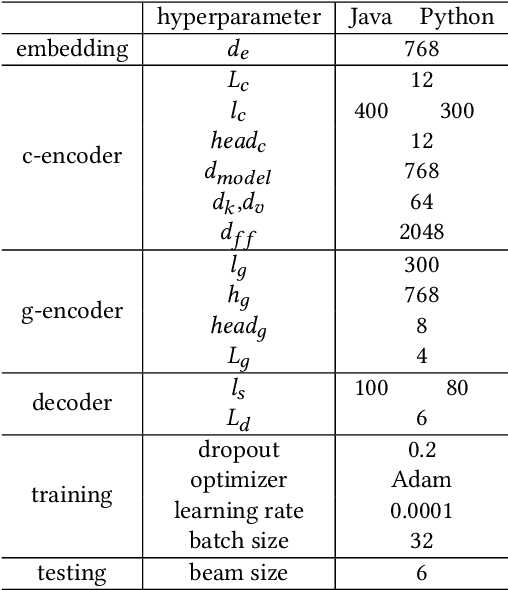
Code summarization with deep learning has been widely studied in recent years. Current deep learning models for code summarization generally follow the principle in neural machine translation and adopt the encoder-decoder framework, where the encoder learns the semantic representations from source code and the decoder transforms the learnt representations into human-readable text that describes the functionality of code snippets. Despite they achieve the new state-of-the-art performance, we notice that current models often either generate less fluent summaries, or fail to capture the core functionality, since they usually focus on a single type of code representations. As such we propose GypSum, a new deep learning model that learns hybrid representations using graph attention neural networks and a pre-trained programming and natural language model. We introduce particular edges related to the control flow of a code snippet into the abstract syntax tree for graph construction, and design two encoders to learn from the graph and the token sequence of source code, respectively. We modify the encoder-decoder sublayer in the Transformer's decoder to fuse the representations and propose a dual-copy mechanism to facilitate summary generation. Experimental results demonstrate the superior performance of GypSum over existing code summarization models.
Programming Knowledge Tracing: A Comprehensive Dataset and A New Model
Dec 11, 2021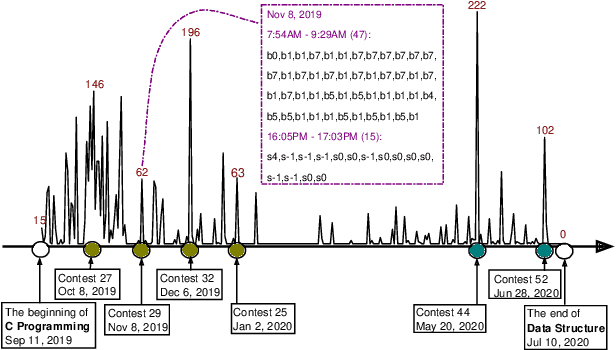
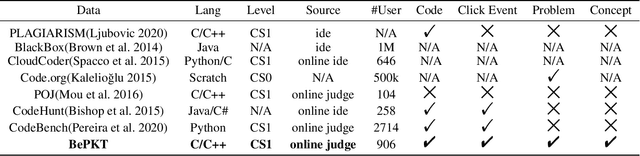
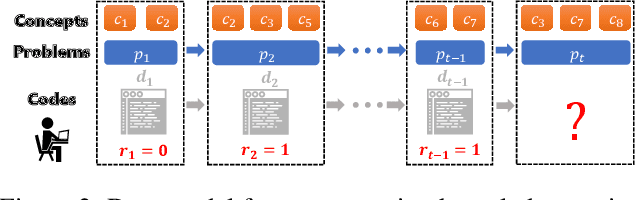
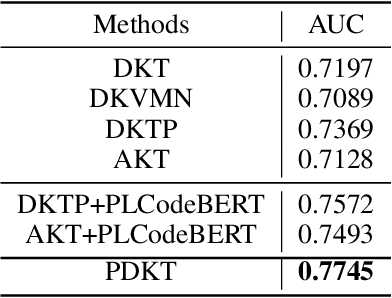
In this paper, we study knowledge tracing in the domain of programming education and make two important contributions. First, we harvest and publish so far the most comprehensive dataset, namely BePKT, which covers various online behaviors in an OJ system, including programming text problems, knowledge annotations, user-submitted code and system-logged events. Second, we propose a new model PDKT to exploit the enriched context for accurate student behavior prediction. More specifically, we construct a bipartite graph for programming problem embedding, and design an improved pre-training model PLCodeBERT for code embedding, as well as a double-sequence RNN model with exponential decay attention for effective feature fusion. Experimental results on the new dataset BePKT show that our proposed model establishes state-of-the-art performance in programming knowledge tracing. In addition, we verify that our code embedding strategy based on PLCodeBERT is complementary to existing knowledge tracing models to further enhance their accuracy. As a side product, PLCodeBERT also results in better performance in other programming-related tasks such as code clone detection.
Deep Knowledge Tracing with Convolutions
Jul 26, 2020

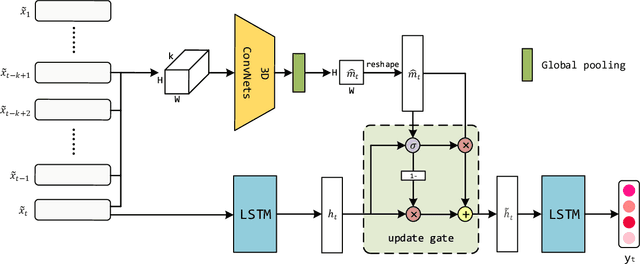
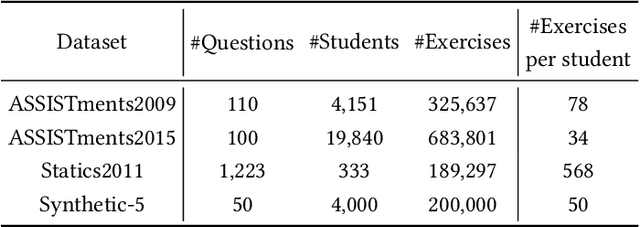
Knowledge tracing (KT) has recently been an active research area of computational pedagogy. The task is to model students mastery level of knowledge based on their responses to the questions in the past, as well as predict the probabilities that they correctly answer subsequent questions in the future. A good KT model can not only make students timely aware of their knowledge states, but also help teachers develop better personalized teaching plans for students. KT tasks were historically solved using statistical modeling methods such as Bayesian inference and factor analysis, but recent advances in deep learning have led to the successive proposals that leverage deep neural networks, including long short-term memory networks, memory-augmented networks and self-attention networks. While those deep models demonstrate superior performance over the traditional approaches, they all neglect more or less the impact on knowledge states of the most recent questions answered by students. The forgetting curve theory states that human memory retention declines over time, therefore knowledge states should be mostly affected by the recent questions. Based on this observation, we propose a Convolutional Knowledge Tracing (CKT) model in this paper. In addition to modeling the long-term effect of the entire question-answer sequence, CKT also strengthens the short-term effect of recent questions using 3D convolutions, thereby effectively modeling the forgetting curve in the learning process. Extensive experiments show that CKT achieves the new state-of-the-art in predicting students performance compared with existing models. Using CKT, we gain 1.55 and 2.03 improvements in terms of AUC over DKT and DKVMN respectively, on the ASSISTments2009 dataset. And on the ASSISTments2015 dataset, the corresponding improvements are 1.01 and 1.96 respectively.
Discovering Traveling Companions using Autoencoders
Jul 23, 2020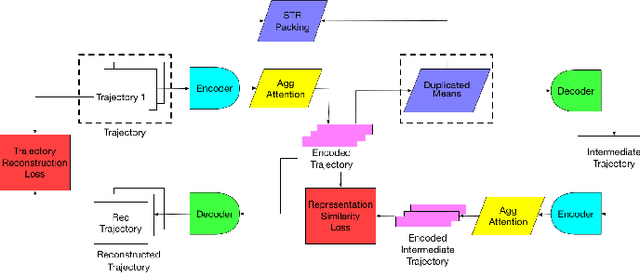
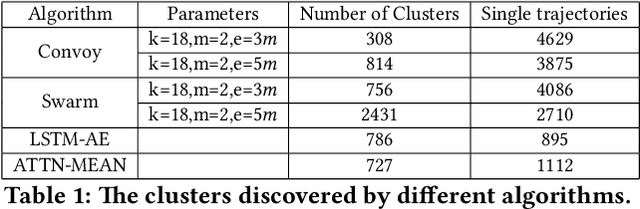
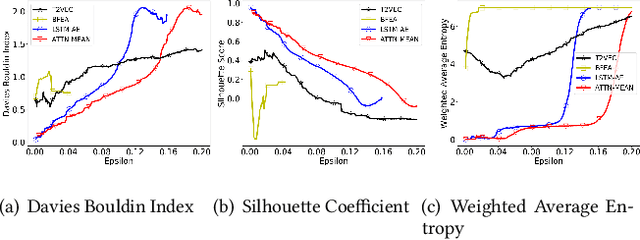
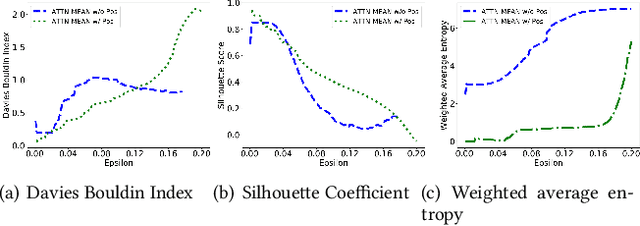
With the wide adoption of mobile devices, today's location tracking systems such as satellites, cellular base stations and wireless access points are continuously producing tremendous amounts of location data of moving objects. The ability to discover moving objects that travel together, i.e., traveling companions, from their trajectories is desired by many applications such as intelligent transportation systems and location-based services. Existing algorithms are either based on pattern mining methods that define a particular pattern of traveling companions or based on representation learning methods that learn similar representations for similar trajectories. The former methods suffer from the pairwise point-matching problem and the latter often ignore the temporal proximity between trajectories. In this work, we propose a generic deep representation learning model using autoencoders, namely, ATTN-MEAN, for the discovery of traveling companions. ATTN-MEAN collectively injects spatial and temporal information into its input embeddings using skip-gram, positional encoding techniques, respectively. Besides, our model further encourages trajectories to learn from their neighbours by leveraging the Sort-Tile-Recursive algorithm, mean operation and global attention mechanism. After obtaining the representations from the encoders, we run DBSCAN to cluster the representations to find travelling companion. The corresponding trajectories in the same cluster are considered as traveling companions. Experimental results suggest that ATTN-MEAN performs better than the state-of-the-art algorithms on finding traveling companions.