 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Trajectory-free Crash Detection Framework with Generative Approach and Segment Map Diffusion
Nov 17, 2025Real-time crash detection is essential for developing proactive safety management strategy and enhancing overall traffic efficiency. To address the limitations associated with trajectory acquisition and vehicle tracking, road segment maps recording the individual-level traffic dynamic data were directly served in crash detection. A novel two-stage trajectory-free crash detection framework, was present to generate the rational future road segment map and identify crashes. The first-stage diffusion-based segment map generation model, Mapfusion, conducts a noisy-to-normal process that progressively adds noise to the road segment map until the map is corrupted to pure Gaussian noise. The denoising process is guided by sequential embedding components capturing the temporal dynamics of segment map sequences. Furthermore, the generation model is designed to incorporate background context through ControlNet to enhance generation control. Crash detection is achieved by comparing the monitored segment map with the generations from diffusion model in second stage. Trained on non-crash vehicle motion data, Mapfusion successfully generates realistic road segment evolution maps based on learned motion patterns and remains robust across different sampling intervals. Experiments on real-world crashes indicate the effectiveness of the proposed two-stage method in accurately detecting crashes.
TemporalFlowViz: Parameter-Aware Visual Analytics for Interpreting Scramjet Combustion Evolution
Sep 05, 2025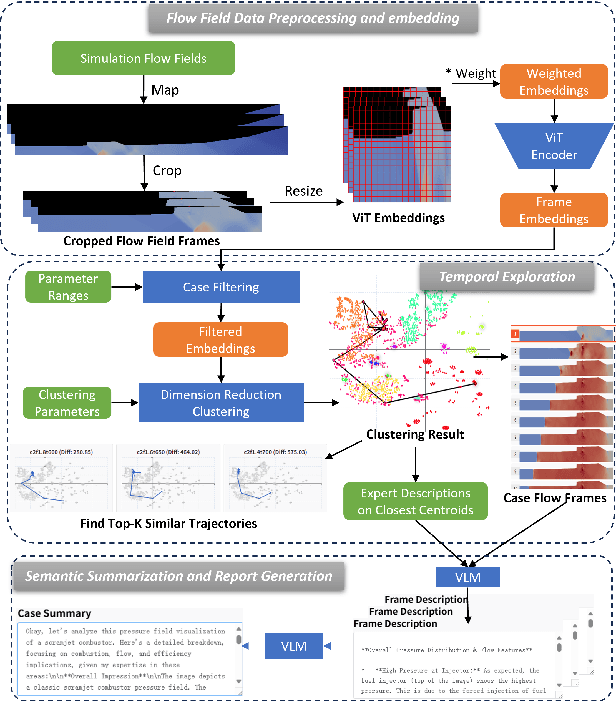
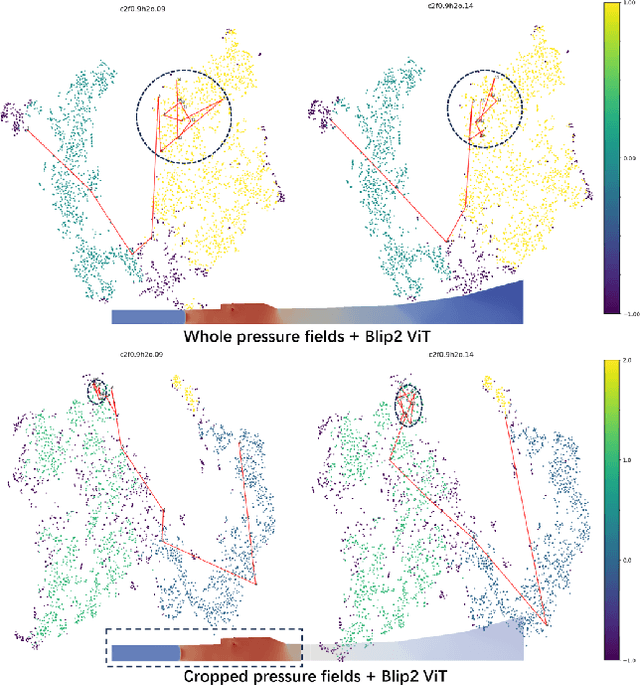
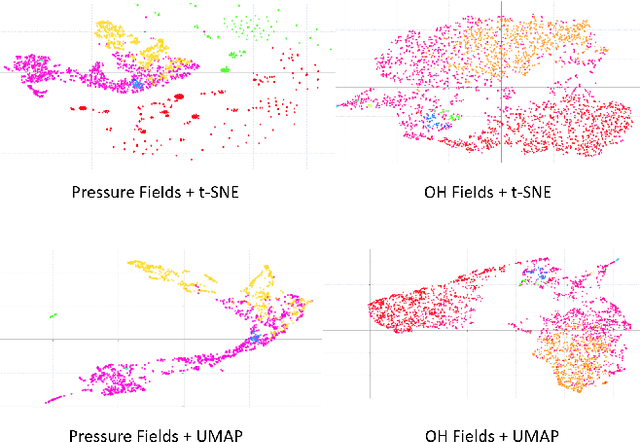
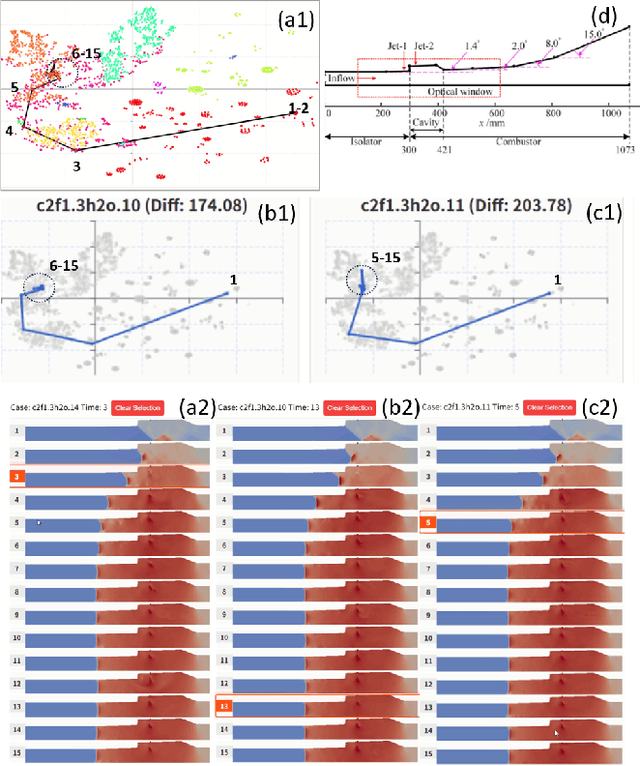
Understanding the complex combustion dynamics within scramjet engines is critical for advancing high-speed propulsion technologies. However, the large scale and high dimensionality of simulation-generated temporal flow field data present significant challenges for visual interpretation, feature differentiation, and cross-case comparison. In this paper, we present TemporalFlowViz, a parameter-aware visual analytics workflow and system designed to support expert-driven clustering, visualization, and interpretation of temporal flow fields from scramjet combustion simulations. Our approach leverages hundreds of simulated combustion cases with varying initial conditions, each producing time-sequenced flow field images. We use pretrained Vision Transformers to extract high-dimensional embeddings from these frames, apply dimensionality reduction and density-based clustering to uncover latent combustion modes, and construct temporal trajectories in the embedding space to track the evolution of each simulation over time. To bridge the gap between latent representations and expert reasoning, domain specialists annotate representative cluster centroids with descriptive labels. These annotations are used as contextual prompts for a vision-language model, which generates natural-language summaries for individual frames and full simulation cases. The system also supports parameter-based filtering, similarity-based case retrieval, and coordinated multi-view exploration to facilitate in-depth analysis. We demonstrate the effectiveness of TemporalFlowViz through two expert-informed case studies and expert feedback, showing TemporalFlowViz enhances hypothesis generation, supports interpretable pattern discovery, and enhances knowledge discovery in large-scale scramjet combustion analysis.
SePPO: Semi-Policy Preference Optimization for Diffusion Alignment
Oct 07, 2024



Reinforcement learning from human feedback (RLHF) methods are emerging as a way to fine-tune diffusion models (DMs) for visual generation. However, commonly used on-policy strategies are limited by the generalization capability of the reward model, while off-policy approaches require large amounts of difficult-to-obtain paired human-annotated data, particularly in visual generation tasks. To address the limitations of both on- and off-policy RLHF, we propose a preference optimization method that aligns DMs with preferences without relying on reward models or paired human-annotated data. Specifically, we introduce a Semi-Policy Preference Optimization (SePPO) method. SePPO leverages previous checkpoints as reference models while using them to generate on-policy reference samples, which replace "losing images" in preference pairs. This approach allows us to optimize using only off-policy "winning images." Furthermore, we design a strategy for reference model selection that expands the exploration in the policy space. Notably, we do not simply treat reference samples as negative examples for learning. Instead, we design an anchor-based criterion to assess whether the reference samples are likely to be winning or losing images, allowing the model to selectively learn from the generated reference samples. This approach mitigates performance degradation caused by the uncertainty in reference sample quality. We validate SePPO across both text-to-image and text-to-video benchmarks. SePPO surpasses all previous approaches on the text-to-image benchmarks and also demonstrates outstanding performance on the text-to-video benchmarks. Code will be released in https://github.com/DwanZhang-AI/SePPO.
WaveDM: Wavelet-Based Diffusion Models for Image Restoration
May 23, 2023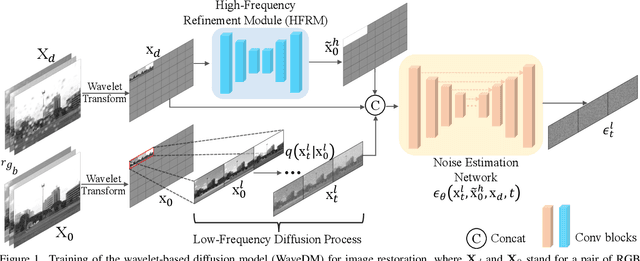
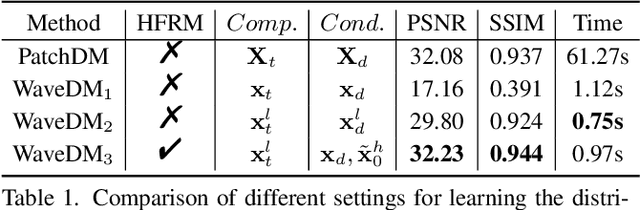
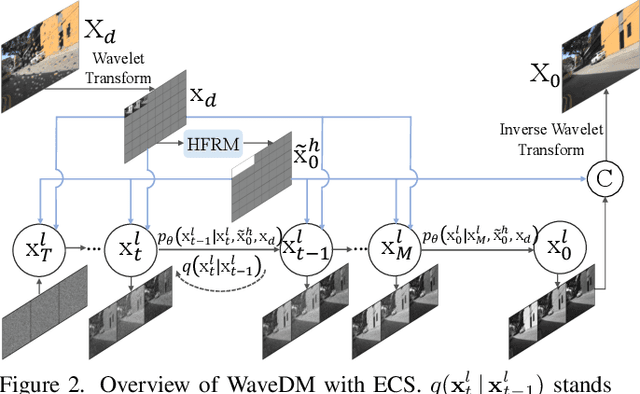
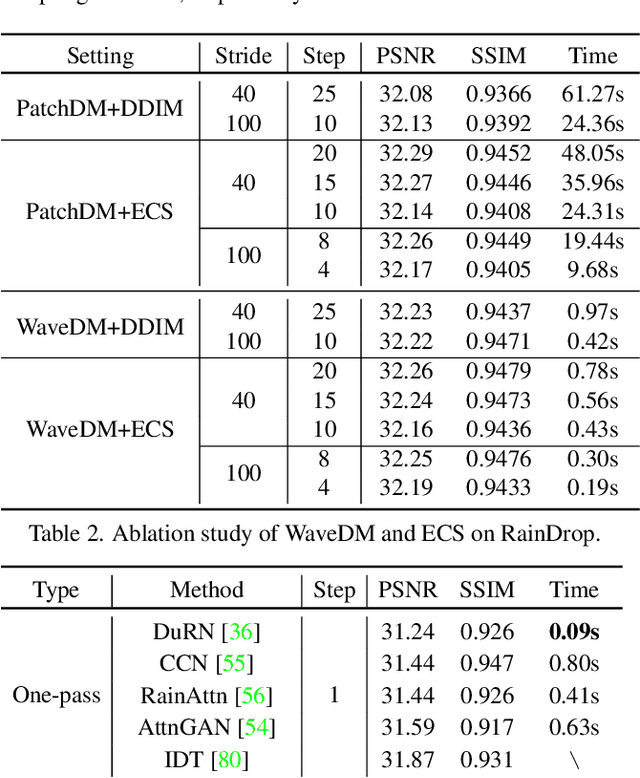
Latest diffusion-based methods for many image restoration tasks outperform traditional models, but they encounter the long-time inference problem. To tackle it, this paper proposes a Wavelet-Based Diffusion Model (WaveDM) with an Efficient Conditional Sampling (ECS) strategy. WaveDM learns the distribution of clean images in the wavelet domain conditioned on the wavelet spectrum of degraded images after wavelet transform, which is more time-saving in each step of sampling than modeling in the spatial domain. In addition, ECS follows the same procedure as the deterministic implicit sampling in the initial sampling period and then stops to predict clean images directly, which reduces the number of total sampling steps to around 5. Evaluations on four benchmark datasets including image raindrop removal, defocus deblurring, demoir\'eing, and denoising demonstrate that WaveDM achieves state-of-the-art performance with the efficiency that is comparable to traditional one-pass methods and over 100 times faster than existing image restoration methods using vanilla diffusion models.
a unified front-end framework for english text-to-speech synthesis
May 18, 2023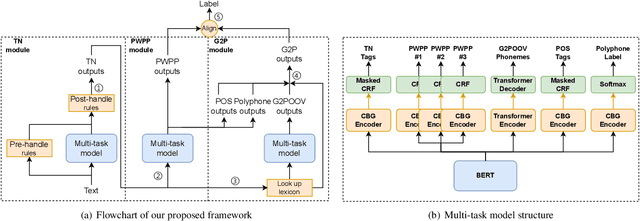

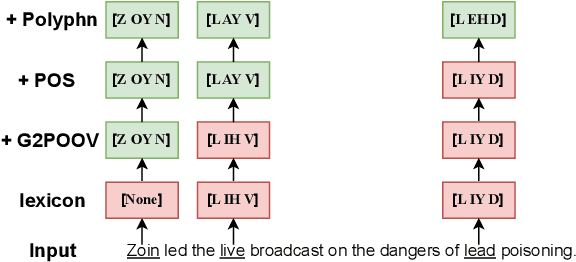
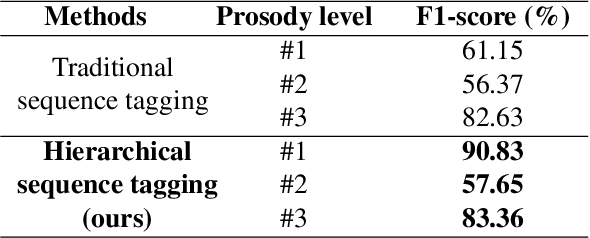
The front-end is a critical component of English text-to-speech (TTS) systems, responsible for extracting linguistic features that are essential for a text-to-speech model to synthesize speech, such as prosodies and phonemes. The English TTS front-end typically consists of a text normalization (TN) module, a prosody word prosody phrase (PWPP) module, and a grapheme-to-phoneme (G2P) module. However, current research on the English TTS front-end focuses solely on individual modules, neglecting the interdependence between them and resulting in sub-optimal performance for each module. Therefore, this paper proposes a unified front-end framework that captures the dependencies among the English TTS front-end modules. Extensive experiments have demonstrated that the proposed method achieves state-of-the-art (SOTA) performance in all modules.
GypSum: Learning Hybrid Representations for Code Summarization
Apr 26, 2022
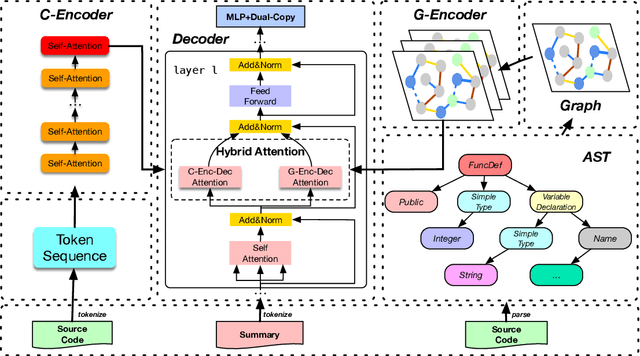
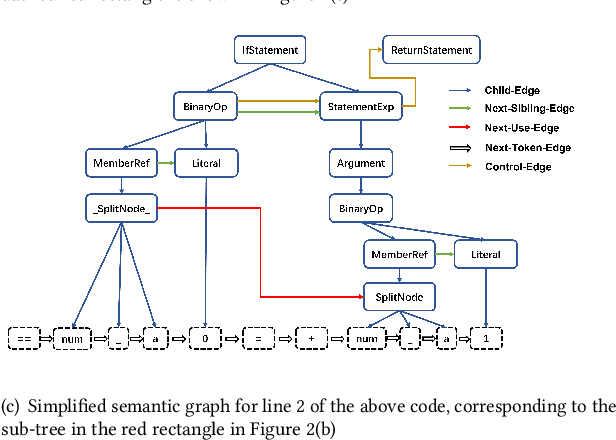
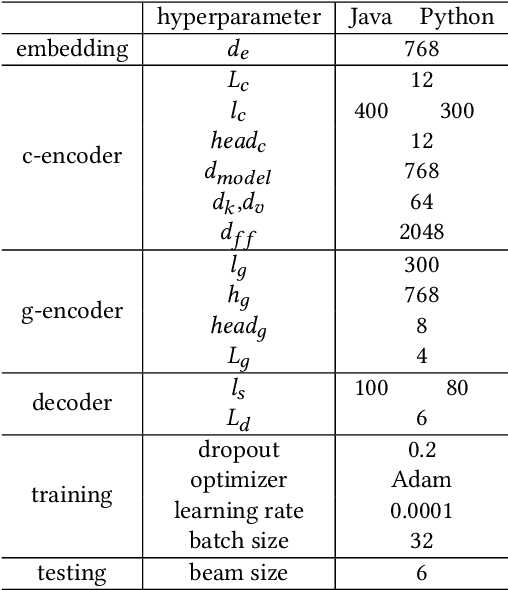
Code summarization with deep learning has been widely studied in recent years. Current deep learning models for code summarization generally follow the principle in neural machine translation and adopt the encoder-decoder framework, where the encoder learns the semantic representations from source code and the decoder transforms the learnt representations into human-readable text that describes the functionality of code snippets. Despite they achieve the new state-of-the-art performance, we notice that current models often either generate less fluent summaries, or fail to capture the core functionality, since they usually focus on a single type of code representations. As such we propose GypSum, a new deep learning model that learns hybrid representations using graph attention neural networks and a pre-trained programming and natural language model. We introduce particular edges related to the control flow of a code snippet into the abstract syntax tree for graph construction, and design two encoders to learn from the graph and the token sequence of source code, respectively. We modify the encoder-decoder sublayer in the Transformer's decoder to fuse the representations and propose a dual-copy mechanism to facilitate summary generation. Experimental results demonstrate the superior performance of GypSum over existing code summarization models.
A Multi-user Oriented Live Free-viewpoint Video Streaming System Based On View Interpolation
Dec 22, 2021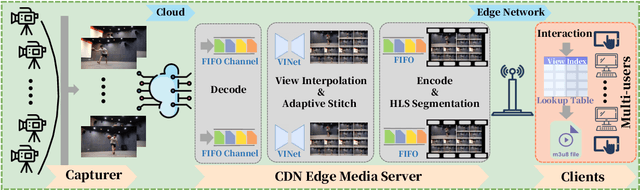

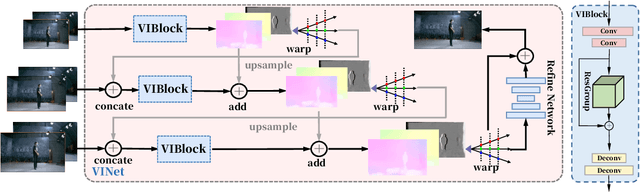

As an important application form of immersive multimedia services, free-viewpoint video(FVV) enables users with great immersive experience by strong interaction. However, the computational complexity of virtual view synthesis algorithms poses a significant challenge to the real-time performance of an FVV system. Furthermore, the individuality of user interaction makes it difficult to serve multiple users simultaneously for a system with conventional architecture. In this paper, we novelly introduce a CNN-based view interpolation algorithm to synthesis dense virtual views in real time. Based on this, we also build an end-to-end live free-viewpoint system with a multi-user oriented streaming strategy. Our system can utilize a single edge server to serve multiple users at the same time without having to bring a large view synthesis load on the client side. We analyze the whole system and show that our approaches give the user a pleasant immersive experience, in terms of both visual quality and latency.
New Perspective on Progressive GANs Distillation for One-class Novelty Detection
Sep 18, 2021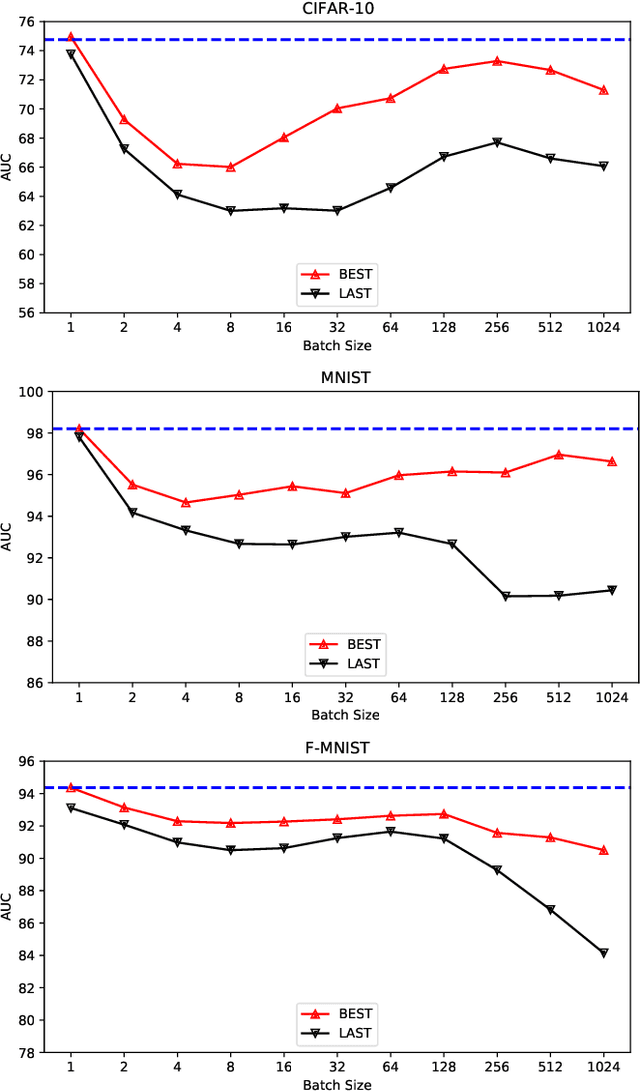

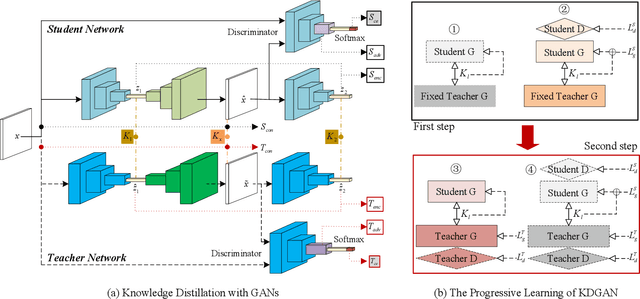
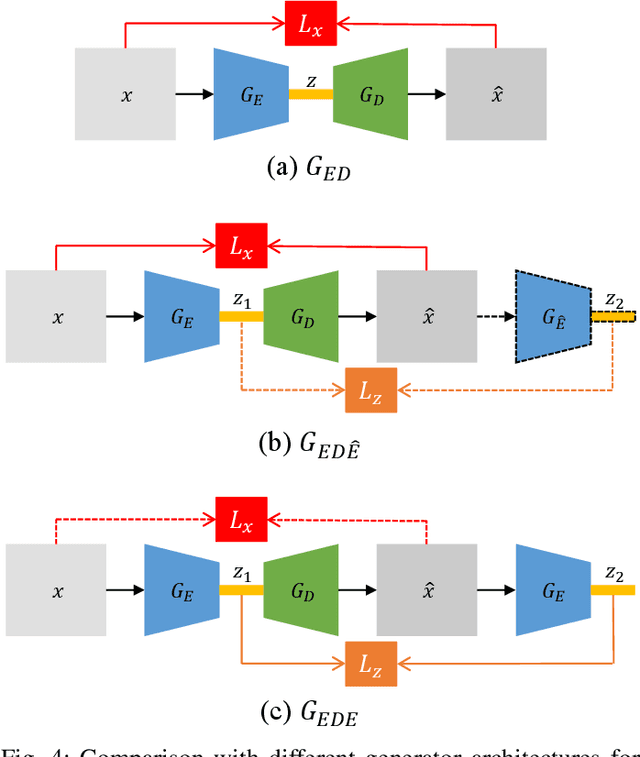
One-class novelty detection is conducted to identify anomalous instances, with different distributions from the expected normal instances. In this paper, the Generative Adversarial Network based on the Encoder-Decoder-Encoder scheme (EDE-GAN) achieves state-of-the-art performance. The two factors bellow serve the above purpose: 1) The EDE-GAN calculates the distance between two latent vectors as the anomaly score, which is unlike the previous methods by utilizing the reconstruction error between images. 2) The model obtains best results when the batch size is set to 1. To illustrate their superiority, we design a new GAN architecture, and compare performances according to different batch sizes. Moreover, with experimentation leads to discovery, our result implies there is also evidence of just how beneficial constraint on the latent space are when engaging in model training. In an attempt to learn compact and fast models, we present a new technology, Progressive Knowledge Distillation with GANs (P-KDGAN), which connects two standard GANs through the designed distillation loss. Two-step progressive learning continuously augments the performance of student GANs with improved results over single-step approach. Our experimental results on CIFAR-10, MNIST, and FMNIST datasets illustrate that P-KDGAN improves the performance of the student GAN by 2.44%, 1.77%, and 1.73% when compressing the computationat ratios of 24.45:1, 311.11:1, and 700:1, respectively.
A LiDAR Assisted Control Module with High Precision in Parking Scenarios for Autonomous Driving Vehicle
May 02, 2021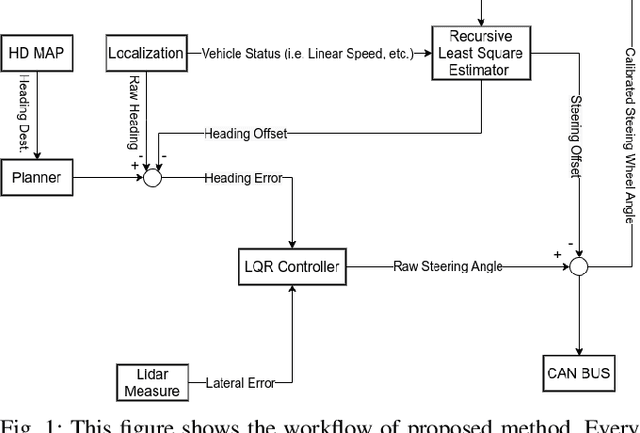
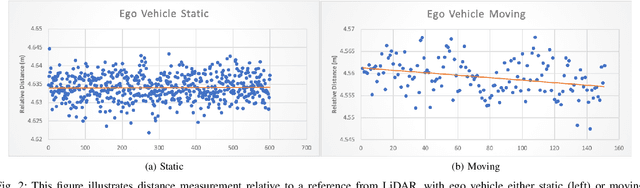
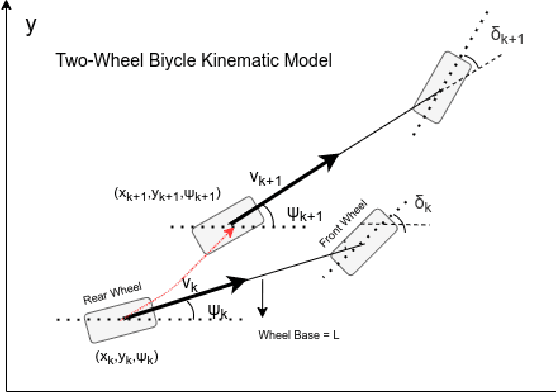
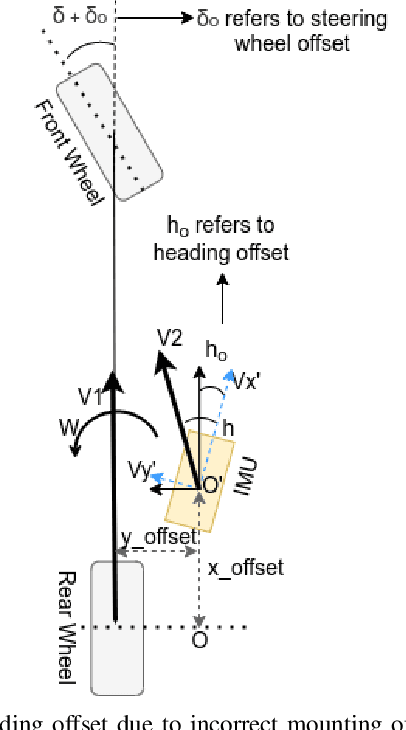
Autonomous driving has been quite promising in recent years. The public has seen Robotaxi delivered by Waymo, Baidu, Cruise, and so on. While autonomous driving vehicles certainly have a bright future, we have to admit that it is still a long way to go for products such as Robotaxi. On the other hand, in less complex scenarios autonomous driving may have the potentiality to reliably outperform humans. For example, humans are good at interactive tasks (while autonomous driving systems usually do not), but we are often incompetent for tasks with strict precision demands. In this paper, we introduce a real-world, industrial scenario of which human drivers are not capable. The task required the ego vehicle to keep a stationary lateral distance (i.e. 3? <= 5 centimeters) with respect to a reference. To address this challenge, we redesigned the control module from Baidu Apollo open-source autonomous driving system. A precise (3? <= 2 centimeters) Error Feedback System was first built to partly replace the localization module. Then we investigated the control module thoroughly and added a real-time calibration algorithm to gain extra precision. We also built a simulation to fine-tune the control parameters. After all those works, the results are encouraging, showing that an end-to-end lateral precision with 3? <= 5 centimeters has been achieved. Further, we show that the results not only outperformed original Apollo modules but also beat specially trained and highly experienced human test drivers.
Metapaths guided Neighbors aggregated Network for?Heterogeneous Graph Reasoning
Mar 11, 2021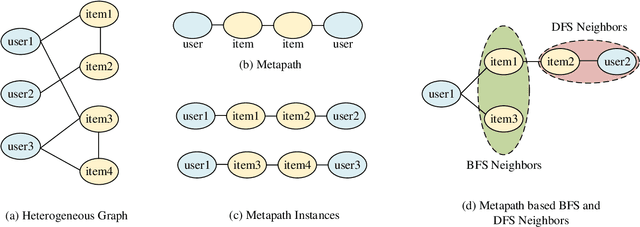
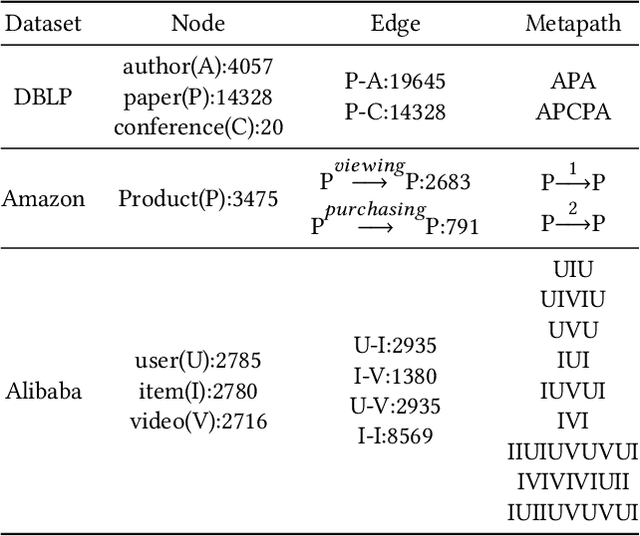
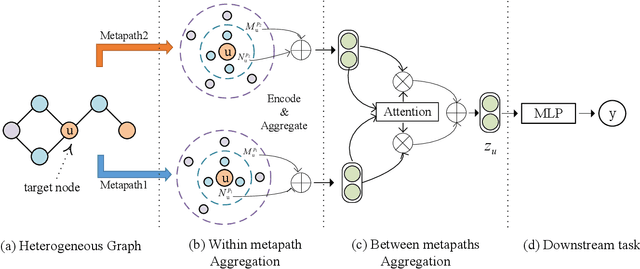
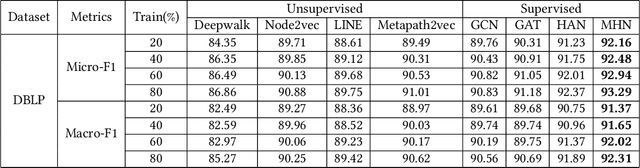
Most real-world datasets are inherently heterogeneous graphs, which involve a diversity of node and relation types. Heterogeneous graph embedding is to learn the structure and semantic information from the graph, and then embed it into the low-dimensional node representation. Existing methods usually capture the composite relation of a heterogeneous graph by defining metapath, which represent a semantic of the graph. However, these methods either ignore node attributes, or discard the local and global information of the graph, or only consider one metapath. To address these limitations, we propose a Metapaths-guided Neighbors-aggregated Heterogeneous Graph Neural Network(MHN) to improve performance. Specially, MHN employs node base embedding to encapsulate node attributes, BFS and DFS neighbors aggregation within a metapath to capture local and global information, and metapaths aggregation to combine different semantics of the heterogeneous graph. We conduct extensive experiments for the proposed MHN on three real-world heterogeneous graph datasets, including node classification, link prediction and online A/B test on Alibaba mobile application. Results demonstrate that MHN performs better than other state-of-the-art baselines.