 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Algorithms for Generalized Mean Densest Subgraph Problem
Oct 17, 2023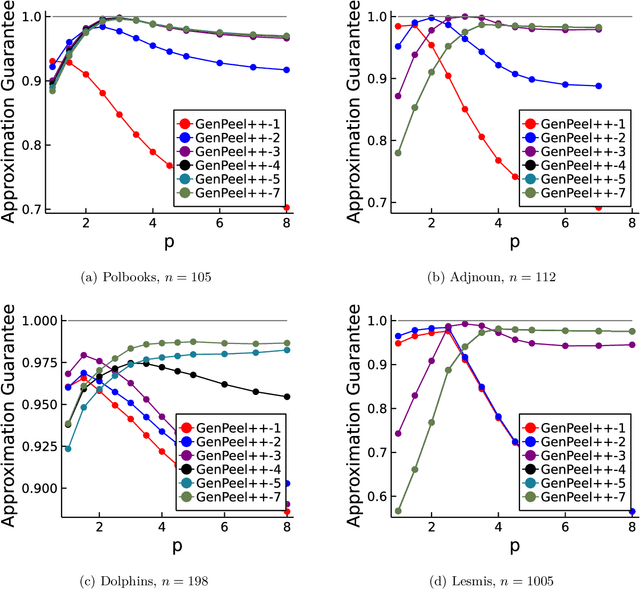
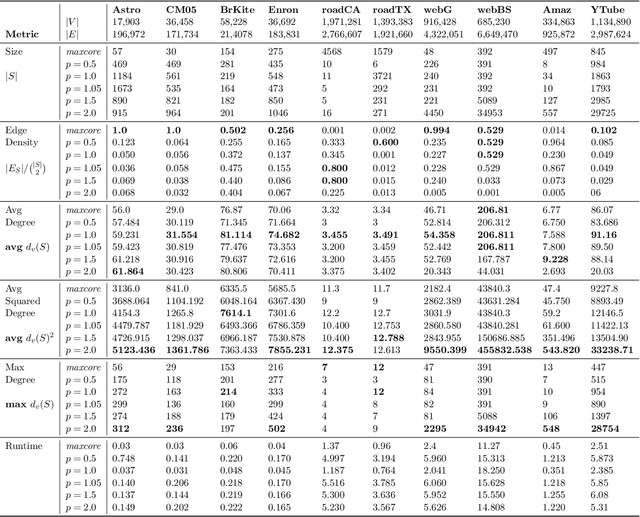
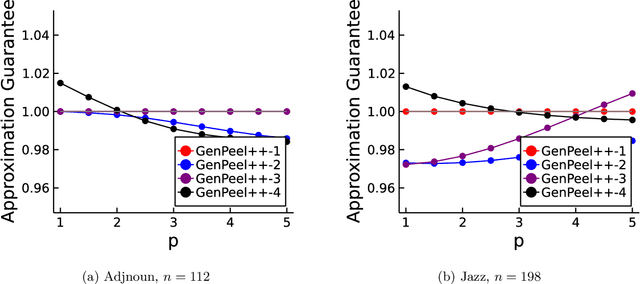
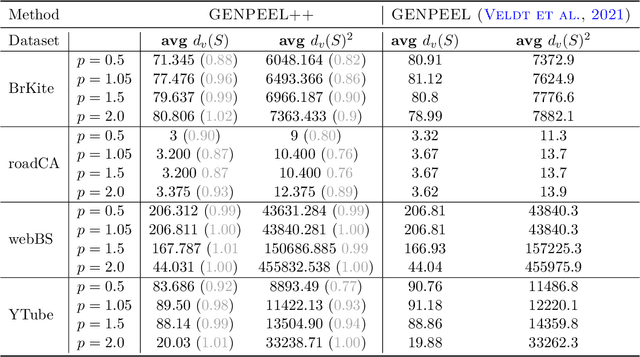
The densest subgraph of a large graph usually refers to some subgraph with the highest average degree, which has been extended to the family of $p$-means dense subgraph objectives by~\citet{veldt2021generalized}. The $p$-mean densest subgraph problem seeks a subgraph with the highest average $p$-th-power degree, whereas the standard densest subgraph problem seeks a subgraph with a simple highest average degree. It was shown that the standard peeling algorithm can perform arbitrarily poorly on generalized objective when $p>1$ but uncertain when $0<p<1$. In this paper, we are the first to show that a standard peeling algorithm can still yield $2^{1/p}$-approximation for the case $0<p < 1$. (Veldt 2021) proposed a new generalized peeling algorithm (GENPEEL), which for $p \geq 1$ has an approximation guarantee ratio $(p+1)^{1/p}$, and time complexity $O(mn)$, where $m$ and $n$ denote the number of edges and nodes in graph respectively. In terms of algorithmic contributions, we propose a new and faster generalized peeling algorithm (called GENPEEL++ in this paper), which for $p \in [1, +\infty)$ has an approximation guarantee ratio $(2(p+1))^{1/p}$, and time complexity $O(m(\log n))$, where $m$ and $n$ denote the number of edges and nodes in graph, respectively. This approximation ratio converges to 1 as $p \rightarrow \infty$.
Copula for Instance-wise Feature Selection and Ranking
Aug 01, 2023



Instance-wise feature selection and ranking methods can achieve a good selection of task-friendly features for each sample in the context of neural networks. However, existing approaches that assume feature subsets to be independent are imperfect when considering the dependency between features. To address this limitation, we propose to incorporate the Gaussian copula, a powerful mathematical technique for capturing correlations between variables, into the current feature selection framework with no additional changes needed. Experimental results on both synthetic and real datasets, in terms of performance comparison and interpretability, demonstrate that our method is capable of capturing meaningful correlations.
MetaTPTrans: A Meta Learning Approach for Multilingual Code Representation Learning
Jun 13, 2022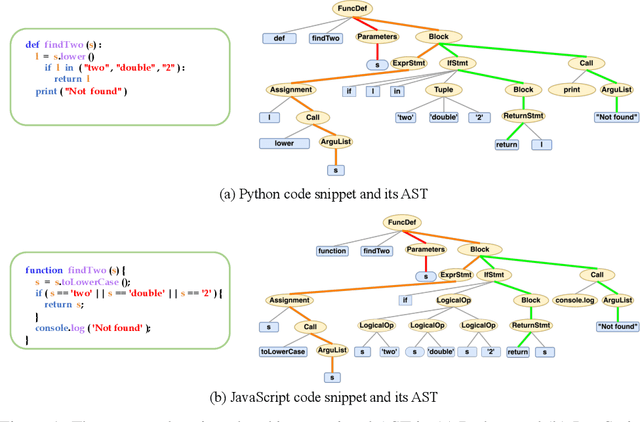
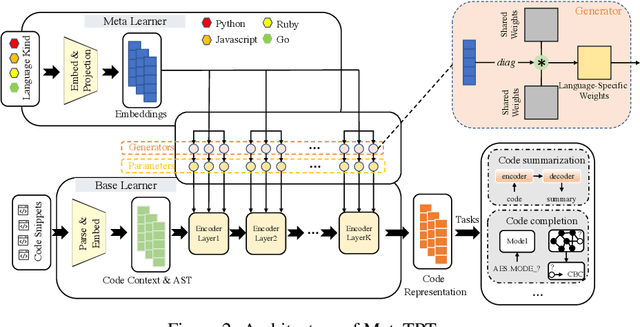
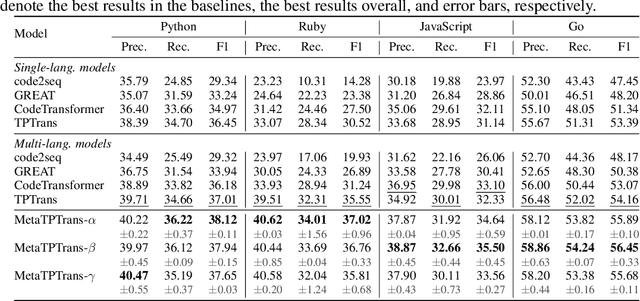
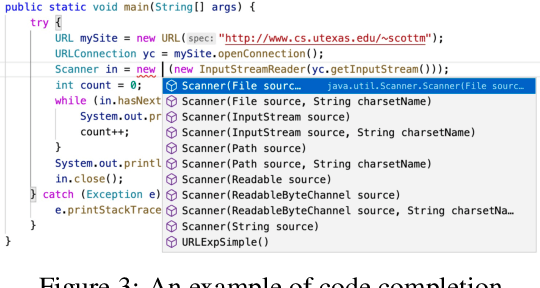
Representation learning of source code is essential for applying machine learning to software engineering tasks. Learning code representation across different programming languages has been shown to be more effective than learning from single-language datasets, since more training data from multi-language datasets improves the model's ability to extract language-agnostic information from source code. However, existing multi-language models overlook the language-specific information which is crucial for downstream tasks that is training on multi-language datasets, while only focusing on learning shared parameters among the different languages. To address this problem, we propose MetaTPTrans, a meta learning approach for multilingual code representation learning. MetaTPTrans generates different parameters for the feature extractor according to the specific programming language of the input source code snippet, enabling the model to learn both language-agnostics and language-specific information. Experimental results show that MetaTPTrans improves the F1 score of state-of-the-art approaches significantly by up to 2.40 percentage points for code summarization, a language-agnostic task; and the prediction accuracy of Top-1 (Top-5) by up to 7.32 (13.15) percentage points for code completion, a language-specific task.
Dataset Pruning: Reducing Training Data by Examining Generalization Influence
May 19, 2022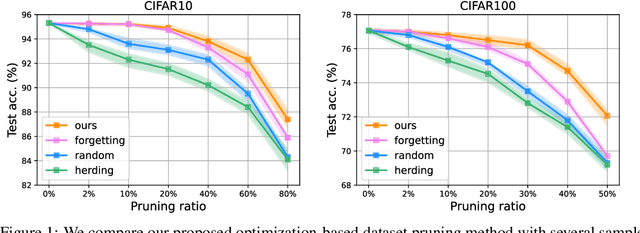

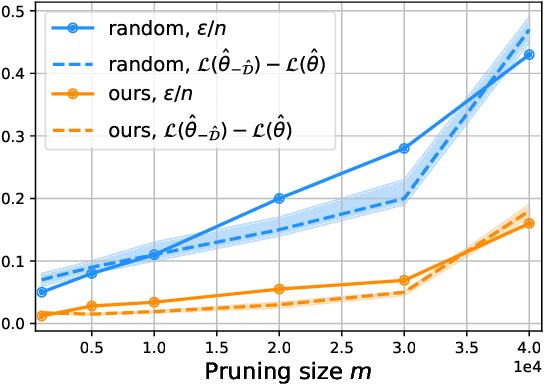
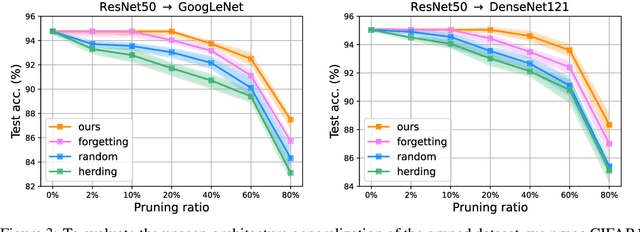
The great success of deep learning heavily relies on increasingly larger training data, which comes at a price of huge computational and infrastructural costs. This poses crucial questions that, do all training data contribute to model's performance? How much does each individual training sample or a sub-training-set affect the model's generalization, and how to construct a smallest subset from the entire training data as a proxy training set without significantly sacrificing the model's performance? To answer these, we propose dataset pruning, an optimization-based sample selection method that can (1) examine the influence of removing a particular set of training samples on model's generalization ability with theoretical guarantee, and (2) construct a smallest subset of training data that yields strictly constrained generalization gap. The empirically observed generalization gap of dataset pruning is substantially consistent with our theoretical expectations. Furthermore, the proposed method prunes 40% training examples on the CIFAR-10 dataset, halves the convergence time with only 1.3% test accuracy decrease, which is superior to previous score-based sample selection methods.
New Perspective on Progressive GANs Distillation for One-class Novelty Detection
Sep 18, 2021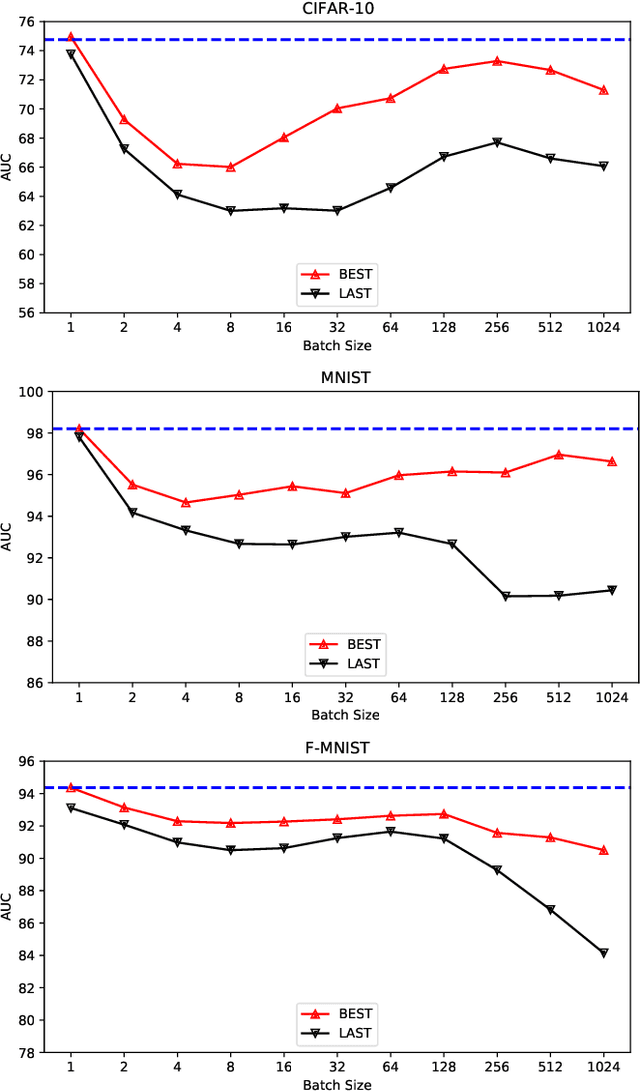

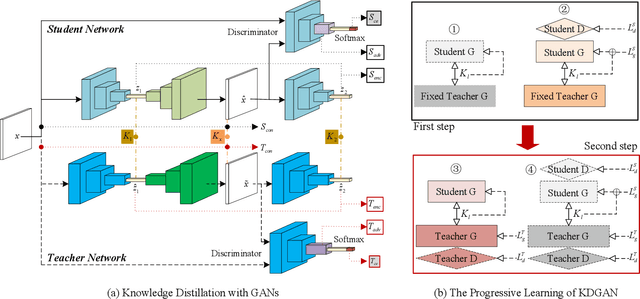
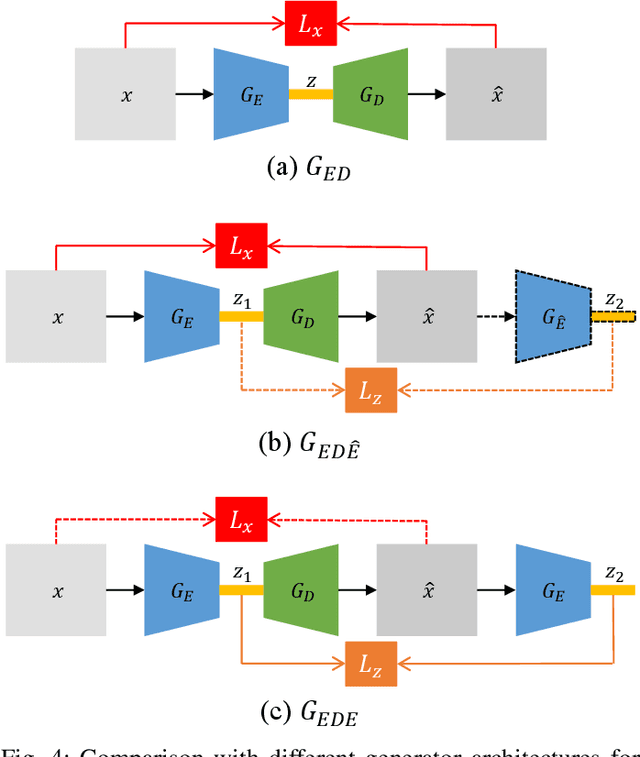
One-class novelty detection is conducted to identify anomalous instances, with different distributions from the expected normal instances. In this paper, the Generative Adversarial Network based on the Encoder-Decoder-Encoder scheme (EDE-GAN) achieves state-of-the-art performance. The two factors bellow serve the above purpose: 1) The EDE-GAN calculates the distance between two latent vectors as the anomaly score, which is unlike the previous methods by utilizing the reconstruction error between images. 2) The model obtains best results when the batch size is set to 1. To illustrate their superiority, we design a new GAN architecture, and compare performances according to different batch sizes. Moreover, with experimentation leads to discovery, our result implies there is also evidence of just how beneficial constraint on the latent space are when engaging in model training. In an attempt to learn compact and fast models, we present a new technology, Progressive Knowledge Distillation with GANs (P-KDGAN), which connects two standard GANs through the designed distillation loss. Two-step progressive learning continuously augments the performance of student GANs with improved results over single-step approach. Our experimental results on CIFAR-10, MNIST, and FMNIST datasets illustrate that P-KDGAN improves the performance of the student GAN by 2.44%, 1.77%, and 1.73% when compressing the computationat ratios of 24.45:1, 311.11:1, and 700:1, respectively.
Instance-weighted Central Similarity for Multi-label Image Retrieval
Aug 28, 2021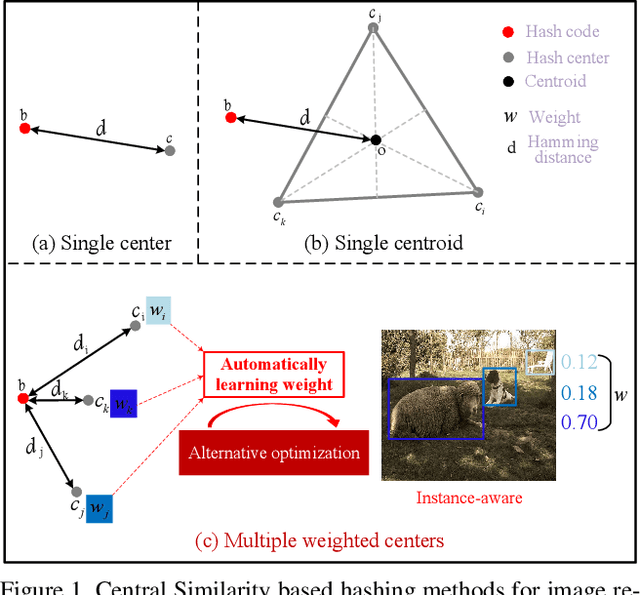

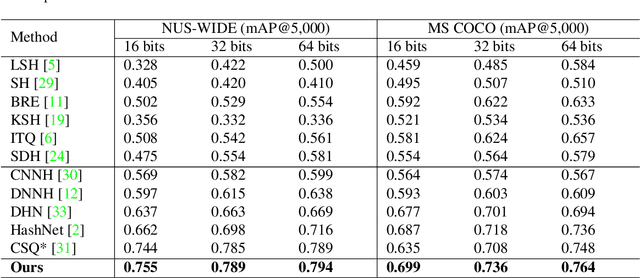
Deep hashing has been widely applied to large-scale image retrieval by encoding high-dimensional data points into binary codes for efficient retrieval. Compared with pairwise/triplet similarity based hash learning, central similarity based hashing can more efficiently capture the global data distribution. For multi-label image retrieval, however, previous methods only use multiple hash centers with equal weights to generate one centroid as the learning target, which ignores the relationship between the weights of hash centers and the proportion of instance regions in the image. To address the above issue, we propose a two-step alternative optimization approach, Instance-weighted Central Similarity (ICS), to automatically learn the center weight corresponding to a hash code. Firstly, we apply the maximum entropy regularizer to prevent one hash center from dominating the loss function, and compute the center weights via projection gradient descent. Secondly, we update neural network parameters by standard back-propagation with fixed center weights. More importantly, the learned center weights can well reflect the proportion of foreground instances in the image. Our method achieves the state-of-the-art performance on the image retrieval benchmarks, and especially improves the mAP by 1.6%-6.4% on the MS COCO dataset.