 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecureAgentBench: Benchmarking Secure Code Generation under Realistic Vulnerability Scenarios
Sep 26, 2025Large language model (LLM) powered code agents are rapidly transforming software engineering by automating tasks such as testing, debugging, and repairing, yet the security risks of their generated code have become a critical concern. Existing benchmarks have offered valuable insights but remain insufficient: they often overlook the genuine context in which vulnerabilities were introduced or adopt narrow evaluation protocols that fail to capture either functional correctness or newly introduced vulnerabilities. We therefore introduce SecureAgentBench, a benchmark of 105 coding tasks designed to rigorously evaluate code agents' capabilities in secure code generation. Each task includes (i) realistic task settings that require multi-file edits in large repositories, (ii) aligned contexts based on real-world open-source vulnerabilities with precisely identified introduction points, and (iii) comprehensive evaluation that combines functionality testing, vulnerability checking through proof-of-concept exploits, and detection of newly introduced vulnerabilities using static analysis. We evaluate three representative agents (SWE-agent, OpenHands, and Aider) with three state-of-the-art LLMs (Claude 3.7 Sonnet, GPT-4.1, and DeepSeek-V3.1). Results show that (i) current agents struggle to produce secure code, as even the best-performing one, SWE-agent supported by DeepSeek-V3.1, achieves merely 15.2% correct-and-secure solutions, (ii) some agents produce functionally correct code but still introduce vulnerabilities, including new ones not previously recorded, and (iii) adding explicit security instructions for agents does not significantly improve secure coding, underscoring the need for further research. These findings establish SecureAgentBench as a rigorous benchmark for secure code generation and a step toward more reliable software development with LLMs.
A Taxonomy of Prompt Defects in LLM Systems
Sep 17, 2025Large Language Models (LLMs) have become key components of modern software, with prompts acting as their de-facto programming interface. However, prompt design remains largely empirical and small mistakes can cascade into unreliable, insecure, or inefficient behavior. This paper presents the first systematic survey and taxonomy of prompt defects, recurring ways that prompts fail to elicit their intended behavior from LLMs. We organize defects along six dimensions: (1) Specification and Intent, (2) Input and Content, (3) Structure and Formatting, (4) Context and Memory, (5) Performance and Efficiency, and (6) Maintainability and Engineering. Each dimension is refined into fine-grained subtypes, illustrated with concrete examples and root cause analysis. Grounded in software engineering principles, we show how these defects surface in real development workflows and examine their downstream effects. For every subtype, we distill mitigation strategies that span emerging prompt engineering patterns, automated guardrails, testing harnesses, and evaluation frameworks. We then summarize these strategies in a master taxonomy that links defect, impact, and remedy. We conclude with open research challenges and a call for rigorous engineering-oriented methodologies to ensure that LLM-driven systems are dependable by design.
Security Vulnerability Detection with Multitask Self-Instructed Fine-Tuning of Large Language Models
Jun 09, 2024
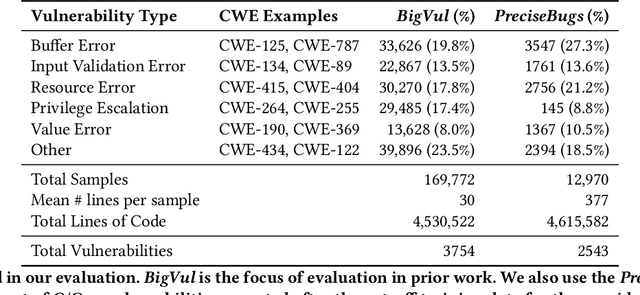
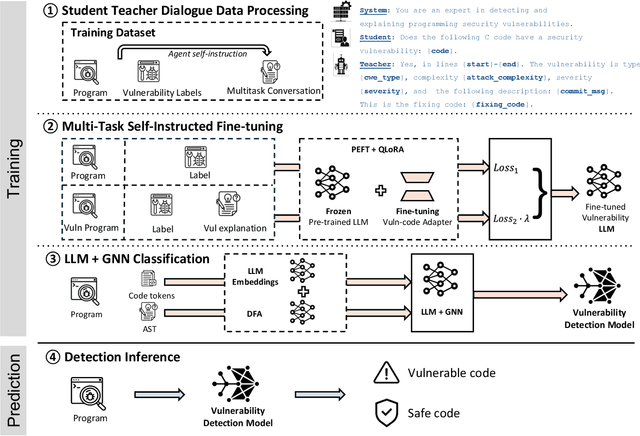
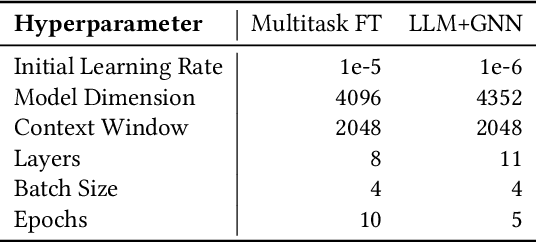
Software security vulnerabilities allow attackers to perform malicious activities to disrupt software operations. Recent Transformer-based language models have significantly advanced vulnerability detection, surpassing the capabilities of static analysis based deep learning models. However, language models trained solely on code tokens do not capture either the explanation of vulnerability type or the data flow structure information of code, both of which are crucial for vulnerability detection. We propose a novel technique that integrates a multitask sequence-to-sequence LLM with pro-gram control flow graphs encoded as a graph neural network to achieve sequence-to-classification vulnerability detection. We introduce MSIVD, multitask self-instructed fine-tuning for vulnerability detection, inspired by chain-of-thought prompting and LLM self-instruction. Our experiments demonstrate that MSIVD achieves superior performance, outperforming the highest LLM-based vulnerability detector baseline (LineVul), with a F1 score of 0.92 on the BigVul dataset, and 0.48 on the PreciseBugs dataset. By training LLMs and GNNs simultaneously using a combination of code and explanatory metrics of a vulnerable program, MSIVD represents a promising direction for advancing LLM-based vulnerability detection that generalizes to unseen data. Based on our findings, we further discuss the necessity for new labelled security vulnerability datasets, as recent LLMs have seen or memorized prior datasets' held-out evaluation data.
Just-in-Time Security Patch Detection -- LLM At the Rescue for Data Augmentation
Dec 02, 2023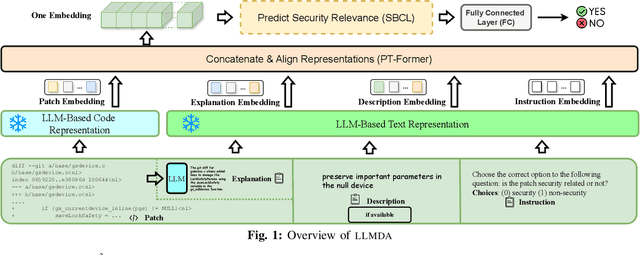
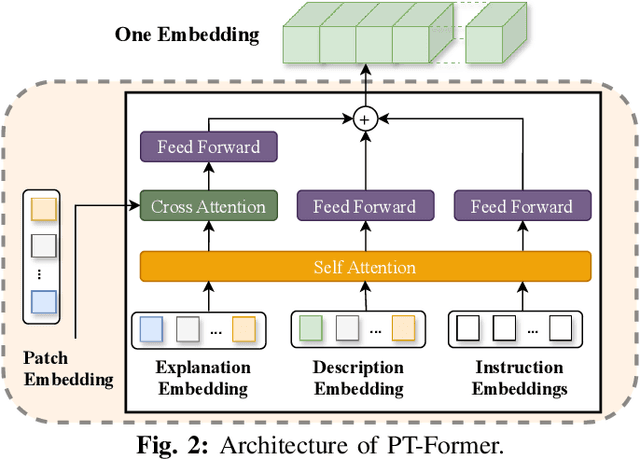
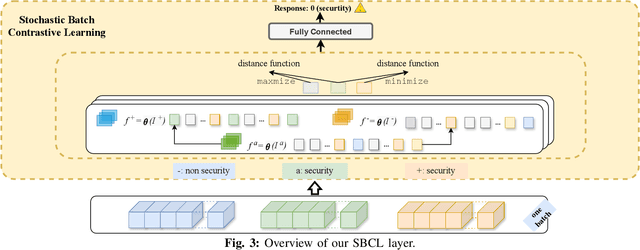
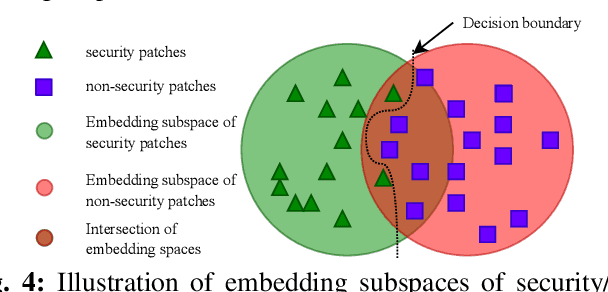
In the face of growing vulnerabilities found in open-source software, the need to identify {discreet} security patches has become paramount. The lack of consistency in how software providers handle maintenance often leads to the release of security patches without comprehensive advisories, leaving users vulnerable to unaddressed security risks. To address this pressing issue, we introduce a novel security patch detection system, LLMDA, which capitalizes on Large Language Models (LLMs) and code-text alignment methodologies for patch review, data enhancement, and feature combination. Within LLMDA, we initially utilize LLMs for examining patches and expanding data of PatchDB and SPI-DB, two security patch datasets from recent literature. We then use labeled instructions to direct our LLMDA, differentiating patches based on security relevance. Following this, we apply a PTFormer to merge patches with code, formulating hybrid attributes that encompass both the innate details and the interconnections between the patches and the code. This distinctive combination method allows our system to capture more insights from the combined context of patches and code, hence improving detection precision. Finally, we devise a probabilistic batch contrastive learning mechanism within batches to augment the capability of the our LLMDA in discerning security patches. The results reveal that LLMDA significantly surpasses the start of the art techniques in detecting security patches, underscoring its promise in fortifying software maintenance.
Is ChatGPT the Ultimate Programming Assistant -- How far is it?
Apr 24, 2023



The recent progress in generative AI techniques has significantly influenced software engineering, as AI-driven methods tackle common developer challenges such as code synthesis from descriptions, program repair, and natural language summaries for existing programs. Large-scale language models (LLMs), like OpenAI's Codex, are increasingly adopted in AI-driven software engineering. ChatGPT, another LLM, has gained considerable attention for its potential as a bot for discussing source code, suggesting changes, providing descriptions, and generating code. To evaluate the practicality of LLMs as programming assistant bots, it is essential to examine their performance on unseen problems and various tasks. In our paper, we conduct an empirical analysis of ChatGPT's potential as a fully automated programming assistant, emphasizing code generation, program repair, and code summarization. Our study assesses ChatGPT's performance on common programming problems and compares it to state-of-the-art approaches using two benchmarks. Our research indicates that ChatGPT effectively handles typical programming challenges. However, we also discover the limitations in its attention span: comprehensive descriptions can restrict ChatGPT's focus and impede its ability to utilize its extensive knowledge for problem-solving. Surprisingly, we find that ChatGPT's summary explanations of incorrect code provide valuable insights into the developer's original intentions. This insight can be served as a foundation for future work addressing the oracle problem. Our study offers valuable perspectives on the development of LLMs for programming assistance, specifically by highlighting the significance of prompt engineering and enhancing our comprehension of ChatGPT's practical applications in software engineering.
App Review Driven Collaborative Bug Finding
Jan 23, 2023
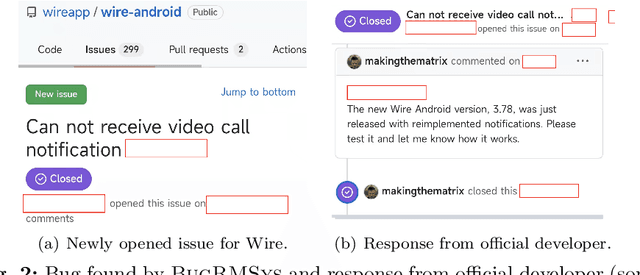


Software development teams generally welcome any effort to expose bugs in their code base. In this work, we build on the hypothesis that mobile apps from the same category (e.g., two web browser apps) may be affected by similar bugs in their evolution process. It is therefore possible to transfer the experience of one historical app to quickly find bugs in its new counterparts. This has been referred to as collaborative bug finding in the literature. Our novelty is that we guide the bug finding process by considering that existing bugs have been hinted within app reviews. Concretely, we design the BugRMSys approach to recommend bug reports for a target app by matching historical bug reports from apps in the same category with user app reviews of the target app. We experimentally show that this approach enables us to quickly expose and report dozens of bugs for targeted apps such as Brave (web browser app). BugRMSys's implementation relies on DistilBERT to produce natural language text embeddings. Our pipeline considers similarities between bug reports and app reviews to identify relevant bugs. We then focus on the app review as well as potential reproduction steps in the historical bug report (from a same-category app) to reproduce the bugs. Overall, after applying BugRMSys to six popular apps, we were able to identify, reproduce and report 20 new bugs: among these, 9 reports have been already triaged, 6 were confirmed, and 4 have been fixed by official development teams, respectively.
AI-driven Mobile Apps: an Explorative Study
Dec 03, 2022Recent years have witnessed an astonishing explosion in the evolution of mobile applications powered by AI technologies. The rapid growth of AI frameworks enables the transition of AI technologies to mobile devices, significantly prompting the adoption of AI apps (i.e., apps that integrate AI into their functions) among smartphone devices. In this paper, we conduct the most extensive empirical study on 56,682 published AI apps from three perspectives: dataset characteristics, development issues, and user feedback and privacy. To this end, we build an automated AI app identification tool, AI Discriminator, that detects eligible AI apps from 7,259,232 mobile apps. First, we carry out a dataset analysis, where we explore the AndroZoo large repository to identify AI apps and their core characteristics. Subsequently, we pinpoint key issues in AI app development (e.g., model protection). Finally, we focus on user reviews and user privacy protection. Our paper provides several notable findings. Some essential ones involve revealing the issue of insufficient model protection by presenting the lack of model encryption, and demonstrating the risk of user privacy data being leaked. We published our large-scale AI app datasets to inspire more future research.
Is this Change the Answer to that Problem? Correlating Descriptions of Bug and Code Changes for Evaluating Patch Correctness
Aug 08, 2022
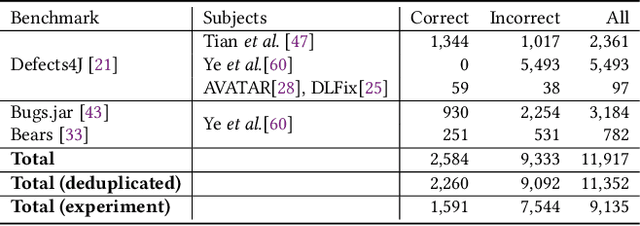
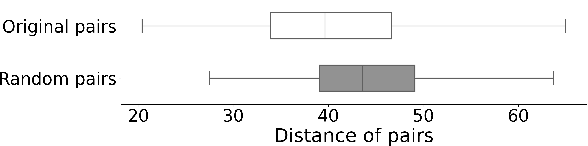
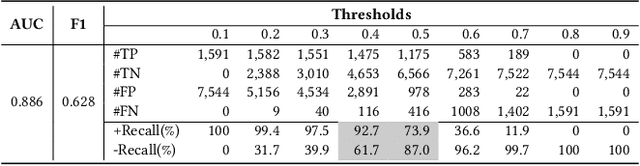
In this work, we propose a novel perspective to the problem of patch correctness assessment: a correct patch implements changes that "answer" to a problem posed by buggy behaviour. Concretely, we turn the patch correctness assessment into a Question Answering problem. To tackle this problem, our intuition is that natural language processing can provide the necessary representations and models for assessing the semantic correlation between a bug (question) and a patch (answer). Specifically, we consider as inputs the bug reports as well as the natural language description of the generated patches. Our approach, Quatrain, first considers state of the art commit message generation models to produce the relevant inputs associated to each generated patch. Then we leverage a neural network architecture to learn the semantic correlation between bug reports and commit messages. Experiments on a large dataset of 9135 patches generated for three bug datasets (Defects4j, Bugs.jar and Bears) show that Quatrain can achieve an AUC of 0.886 on predicting patch correctness, and recalling 93% correct patches while filtering out 62% incorrect patches. Our experimental results further demonstrate the influence of inputs quality on prediction performance. We further perform experiments to highlight that the model indeed learns the relationship between bug reports and code change descriptions for the prediction. Finally, we compare against prior work and discuss the benefits of our approach.
MetaTPTrans: A Meta Learning Approach for Multilingual Code Representation Learning
Jun 13, 2022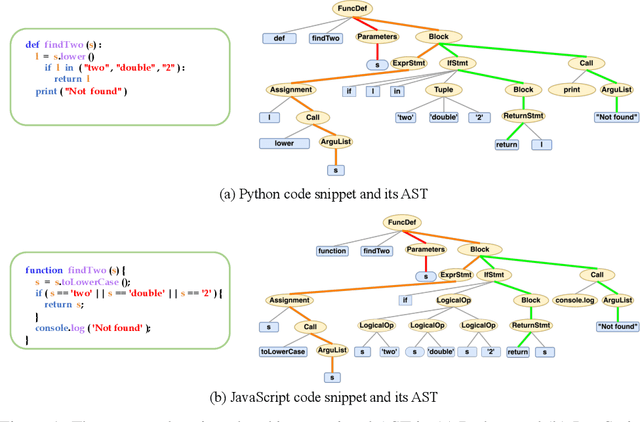
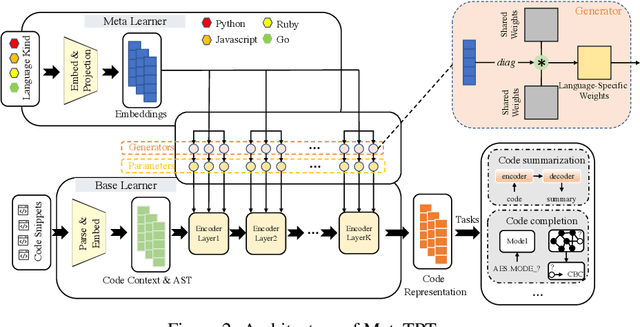
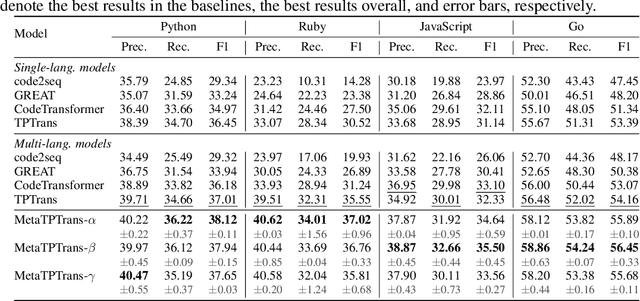
Representation learning of source code is essential for applying machine learning to software engineering tasks. Learning code representation across different programming languages has been shown to be more effective than learning from single-language datasets, since more training data from multi-language datasets improves the model's ability to extract language-agnostic information from source code. However, existing multi-language models overlook the language-specific information which is crucial for downstream tasks that is training on multi-language datasets, while only focusing on learning shared parameters among the different languages. To address this problem, we propose MetaTPTrans, a meta learning approach for multilingual code representation learning. MetaTPTrans generates different parameters for the feature extractor according to the specific programming language of the input source code snippet, enabling the model to learn both language-agnostics and language-specific information. Experimental results show that MetaTPTrans improves the F1 score of state-of-the-art approaches significantly by up to 2.40 percentage points for code summarization, a language-agnostic task; and the prediction accuracy of Top-1 (Top-5) by up to 7.32 (13.15) percentage points for code completion, a language-specific task.
Checking Patch Behaviour against Test Specification
Jul 28, 2021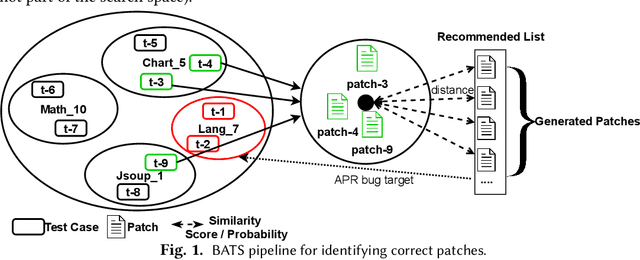
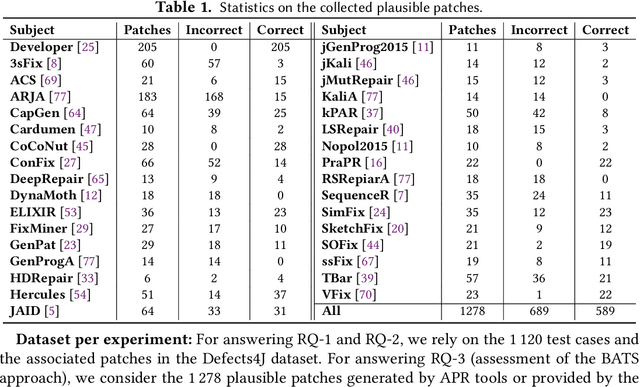
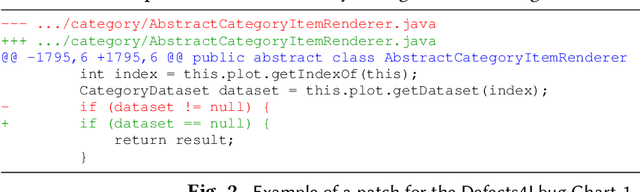

Towards predicting patch correctness in APR, we propose a simple, but novel hypothesis on how the link between the patch behaviour and failing test specifications can be drawn: similar failing test cases should require similar patches. We then propose BATS, an unsupervised learning-based system to predict patch correctness by checking patch Behaviour Against failing Test Specification. BATS exploits deep representation learning models for code and patches: for a given failing test case, the yielded embedding is used to compute similarity metrics in the search for historical similar test cases in order to identify the associated applied patches, which are then used as a proxy for assessing generated patch correctness. Experimentally, we first validate our hypothesis by assessing whether ground-truth developer patches cluster together in the same way that their associated failing test cases are clustered. Then, after collecting a large dataset of 1278 plausible patches (written by developers or generated by some 32 APR tools), we use BATS to predict correctness: BATS achieves an AUC between 0.557 to 0.718 and a recall between 0.562 and 0.854 in identifying correct patches. Compared against previous work, we demonstrate that our approach outperforms state-of-the-art performance in patch correctness prediction, without the need for large labeled patch datasets in contrast with prior machine learning-based approaches. While BATS is constrained by the availability of similar test cases, we show that it can still be complementary to existing approaches: used in conjunction with a recent approach implementing supervised learning, BATS improves the overall recall in detecting correct patches. We finally show that BATS can be complementary to the state-of-the-art PATCH-SIM dynamic approach of identifying the correct patches for APR tools.