 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPELL: Synthesis of Programmatic Edits using LLMs
Feb 01, 2026Library migration is a common but error-prone task in software development. Developers may need to replace one library with another due to reasons like changing requirements or licensing changes. Migration typically entails updating and rewriting source code manually. While automated migration tools exist, most rely on mining examples from real-world projects that have already undergone similar migrations. However, these data are scarce, and collecting them for arbitrary pairs of libraries is difficult. Moreover, these migration tools often miss out on leveraging modern code transformation infrastructure. In this paper, we present a new approach to automated API migration that sidesteps the limitations described above. Instead of relying on existing migration data or using LLMs directly for transformation, we use LLMs to extract migration examples. Next, we use an Agent to generalize those examples to reusable transformation scripts in PolyglotPiranha, a modern code transformation tool. Our method distills latent migration knowledge from LLMs into structured, testable, and repeatable migration logic, without requiring preexisting corpora or manual engineering effort. Experimental results across Python libraries show that our system can generate diverse migration examples and synthesize transformation scripts that generalize to real-world codebases.
Fast, Fine-Grained Equivalence Checking for Neural Decompilers
Jan 08, 2025
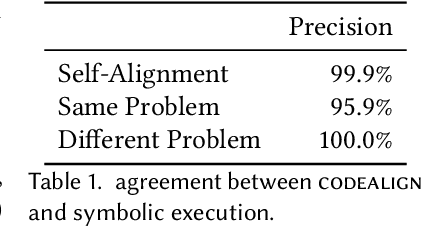
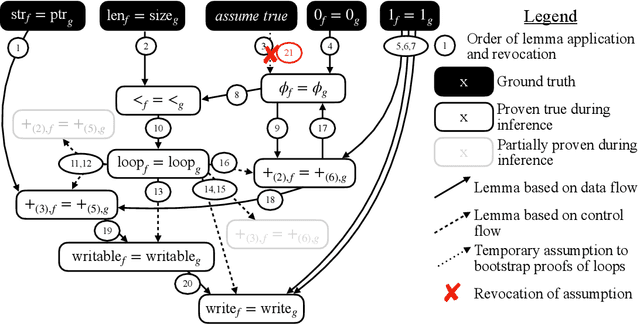
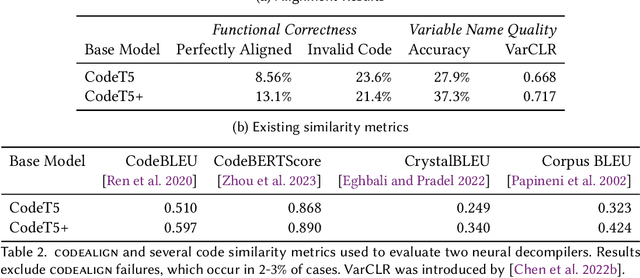
Neural decompilers are machine learning models that reconstruct the source code from an executable program. Critical to the lifecycle of any machine learning model is an evaluation of its effectiveness. However, existing techniques for evaluating neural decompilation models have substantial weaknesses, especially when it comes to showing the correctness of the neural decompiler's predictions. To address this, we introduce codealign, a novel instruction-level code equivalence technique designed for neural decompilers. We provide a formal definition of a relation between equivalent instructions, which we term an equivalence alignment. We show how codealign generates equivalence alignments, then evaluate codealign by comparing it with symbolic execution. Finally, we show how the information codealign provides-which parts of the functions are equivalent and how well the variable names match-is substantially more detailed than existing state-of-the-art evaluation metrics, which report unitless numbers measuring similarity.
Are Large Language Models Memorizing Bug Benchmarks?
Nov 20, 2024
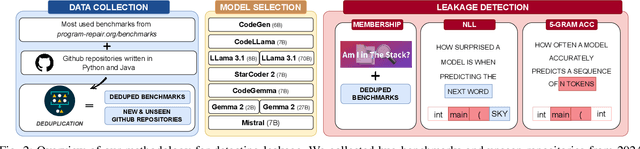
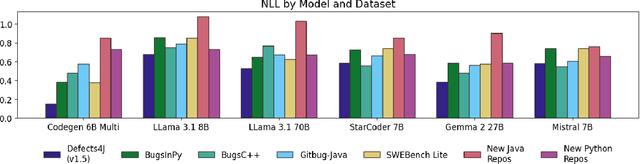
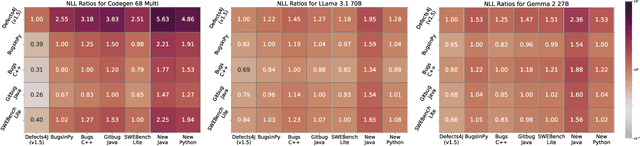
Large Language Models (LLMs) have become integral to various software engineering tasks, including code generation, bug detection, and repair. To evaluate model performance in these domains, numerous bug benchmarks containing real-world bugs from software projects have been developed. However, a growing concern within the software engineering community is that these benchmarks may not reliably reflect true LLM performance due to the risk of data leakage. Despite this concern, limited research has been conducted to quantify the impact of potential leakage. In this paper, we systematically evaluate popular LLMs to assess their susceptibility to data leakage from widely used bug benchmarks. To identify potential leakage, we use multiple metrics, including a study of benchmark membership within commonly used training datasets, as well as analyses of negative log-likelihood and n-gram accuracy. Our findings show that certain models, in particular codegen-multi, exhibit significant evidence of memorization in widely used benchmarks like Defects4J, while newer models trained on larger datasets like LLaMa 3.1 exhibit limited signs of leakage. These results highlight the need for careful benchmark selection and the adoption of robust metrics to adequately assess models capabilities.
Security Vulnerability Detection with Multitask Self-Instructed Fine-Tuning of Large Language Models
Jun 09, 2024
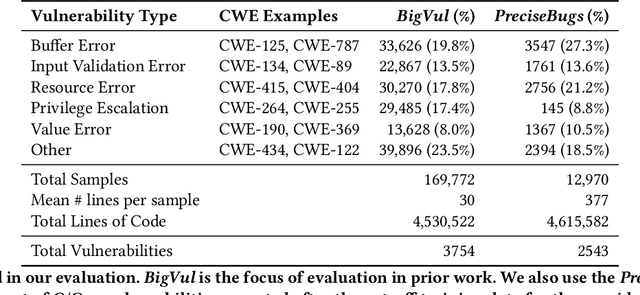
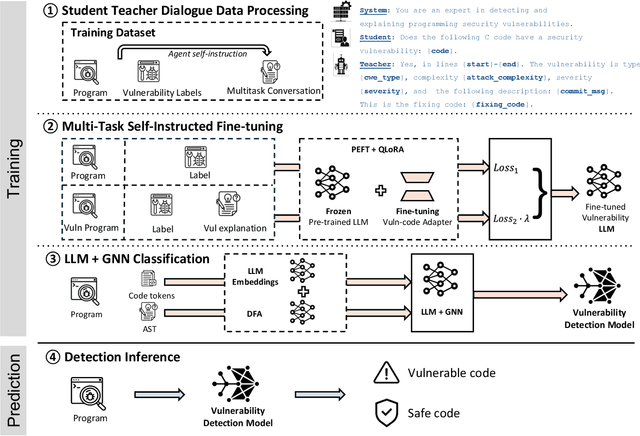
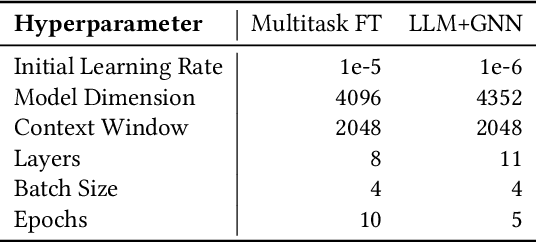
Software security vulnerabilities allow attackers to perform malicious activities to disrupt software operations. Recent Transformer-based language models have significantly advanced vulnerability detection, surpassing the capabilities of static analysis based deep learning models. However, language models trained solely on code tokens do not capture either the explanation of vulnerability type or the data flow structure information of code, both of which are crucial for vulnerability detection. We propose a novel technique that integrates a multitask sequence-to-sequence LLM with pro-gram control flow graphs encoded as a graph neural network to achieve sequence-to-classification vulnerability detection. We introduce MSIVD, multitask self-instructed fine-tuning for vulnerability detection, inspired by chain-of-thought prompting and LLM self-instruction. Our experiments demonstrate that MSIVD achieves superior performance, outperforming the highest LLM-based vulnerability detector baseline (LineVul), with a F1 score of 0.92 on the BigVul dataset, and 0.48 on the PreciseBugs dataset. By training LLMs and GNNs simultaneously using a combination of code and explanatory metrics of a vulnerable program, MSIVD represents a promising direction for advancing LLM-based vulnerability detection that generalizes to unseen data. Based on our findings, we further discuss the necessity for new labelled security vulnerability datasets, as recent LLMs have seen or memorized prior datasets' held-out evaluation data.
Software Engineering for Robotics: Future Research Directions; Report from the 2023 Workshop on Software Engineering for Robotics
Jan 22, 2024Robots are experiencing a revolution as they permeate many aspects of our daily lives, from performing house maintenance to infrastructure inspection, from efficiently warehousing goods to autonomous vehicles, and more. This technical progress and its impact are astounding. This revolution, however, is outstripping the capabilities of existing software development processes, techniques, and tools, which largely have remained unchanged for decades. These capabilities are ill-suited to handling the challenges unique to robotics software such as dealing with a wide diversity of domains, heterogeneous hardware, programmed and learned components, complex physical environments captured and modeled with uncertainty, emergent behaviors that include human interactions, and scalability demands that span across multiple dimensions. Looking ahead to the need to develop software for robots that are ever more ubiquitous, autonomous, and reliant on complex adaptive components, hardware, and data, motivated an NSF-sponsored community workshop on the subject of Software Engineering for Robotics, held in Detroit, Michigan in October 2023. The goal of the workshop was to bring together thought leaders across robotics and software engineering to coalesce a community, and identify key problems in the area of SE for robotics that that community should aim to solve over the next 5 years. This report serves to summarize the motivation, activities, and findings of that workshop, in particular by articulating the challenges unique to robot software, and identifying a vision for fruitful near-term research directions to tackle them.
Large Language Models for Test-Free Fault Localization
Oct 03, 2023



Fault Localization (FL) aims to automatically localize buggy lines of code, a key first step in many manual and automatic debugging tasks. Previous FL techniques assume the provision of input tests, and often require extensive program analysis, program instrumentation, or data preprocessing. Prior work on deep learning for APR struggles to learn from small datasets and produces limited results on real-world programs. Inspired by the ability of large language models (LLMs) of code to adapt to new tasks based on very few examples, we investigate the applicability of LLMs to line level fault localization. Specifically, we propose to overcome the left-to-right nature of LLMs by fine-tuning a small set of bidirectional adapter layers on top of the representations learned by LLMs to produce LLMAO, the first language model based fault localization approach that locates buggy lines of code without any test coverage information. We fine-tune LLMs with 350 million, 6 billion, and 16 billion parameters on small, manually curated corpora of buggy programs such as the Defects4J corpus. We observe that our technique achieves substantially more confidence in fault localization when built on the larger models, with bug localization performance scaling consistently with the LLM size. Our empirical evaluation shows that LLMAO improves the Top-1 results over the state-of-the-art machine learning fault localization (MLFL) baselines by 2.3%-54.4%, and Top-5 results by 14.4%-35.6%. LLMAO is also the first FL technique trained using a language model architecture that can detect security vulnerabilities down to the code line level.
CAT-LM: Training Language Models on Aligned Code And Tests
Oct 02, 2023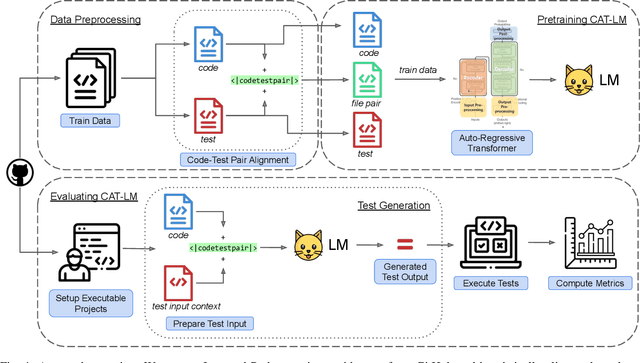

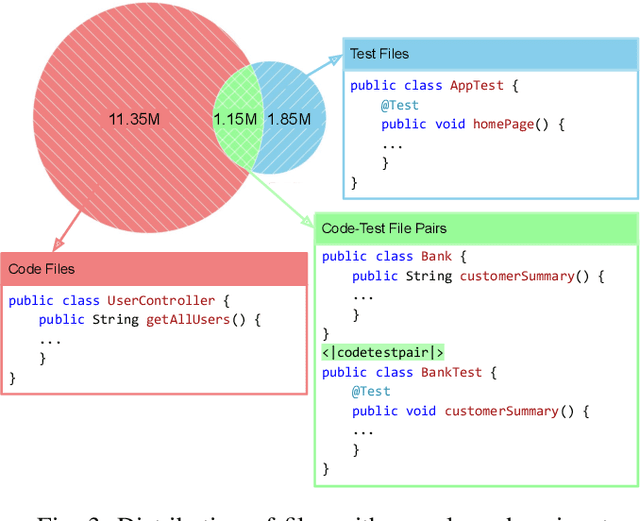
Testing is an integral part of the software development process. Yet, writing tests is time-consuming and therefore often neglected. Classical test generation tools such as EvoSuite generate behavioral test suites by optimizing for coverage, but tend to produce tests that are hard to understand. Language models trained on code can generate code that is highly similar to that written by humans, but current models are trained to generate each file separately, as is standard practice in natural language processing, and thus fail to consider the code-under-test context when producing a test file. In this work, we propose the Aligned Code And Tests Language Model (CAT-LM), a GPT-style language model with 2.7 Billion parameters, trained on a corpus of Python and Java projects. We utilize a novel pretraining signal that explicitly considers the mapping between code and test files when available. We also drastically increase the maximum sequence length of inputs to 8,192 tokens, 4x more than typical code generation models, to ensure that the code context is available to the model when generating test code. We analyze its usefulness for realistic applications, showing that sampling with filtering (e.g., by compilability, coverage) allows it to efficiently produce tests that achieve coverage similar to ones written by developers while resembling their writing style. By utilizing the code context, CAT-LM generates more valid tests than even much larger language models trained with more data (CodeGen 16B and StarCoder) and substantially outperforms a recent test-specific model (TeCo) at test completion. Overall, our work highlights the importance of incorporating software-specific insights when training language models for code and paves the way to more powerful automated test generation.
MELT: Mining Effective Lightweight Transformations from Pull Requests
Aug 28, 2023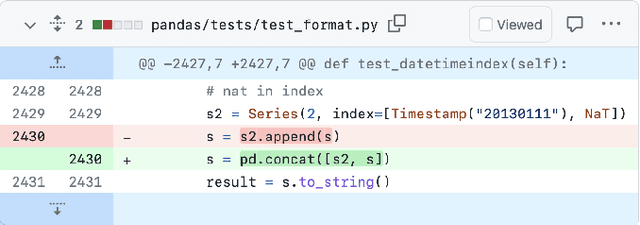
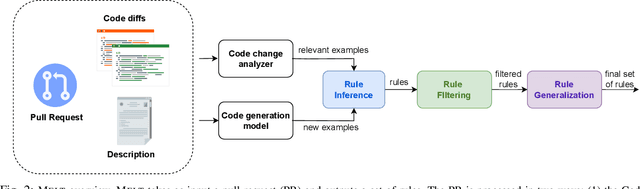

Software developers often struggle to update APIs, leading to manual, time-consuming, and error-prone processes. We introduce MELT, a new approach that generates lightweight API migration rules directly from pull requests in popular library repositories. Our key insight is that pull requests merged into open-source libraries are a rich source of information sufficient to mine API migration rules. By leveraging code examples mined from the library source and automatically generated code examples based on the pull requests, we infer transformation rules in \comby, a language for structural code search and replace. Since inferred rules from single code examples may be too specific, we propose a generalization procedure to make the rules more applicable to client projects. MELT rules are syntax-driven, interpretable, and easily adaptable. Moreover, unlike previous work, our approach enables rule inference to seamlessly integrate into the library workflow, removing the need to wait for client code migrations. We evaluated MELT on pull requests from four popular libraries, successfully mining 461 migration rules from code examples in pull requests and 114 rules from auto-generated code examples. Our generalization procedure increases the number of matches for mined rules by 9x. We applied these rules to client projects and ran their tests, which led to an overall decrease in the number of warnings and fixing some test cases demonstrating MELT's effectiveness in real-world scenarios.
VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
Dec 05, 2021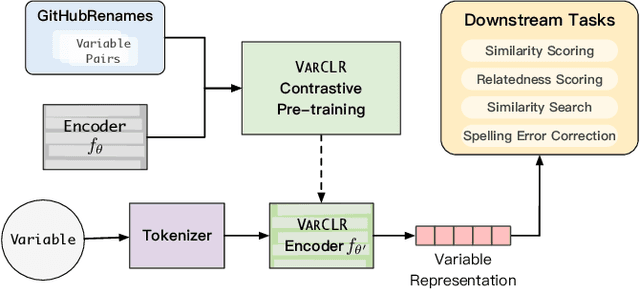
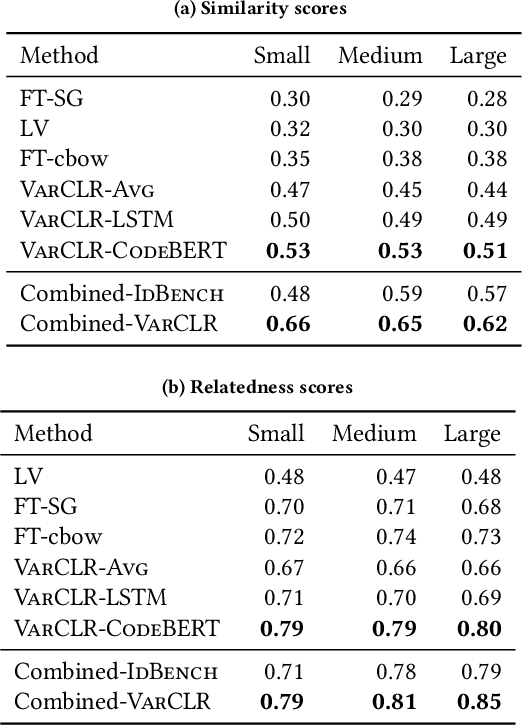
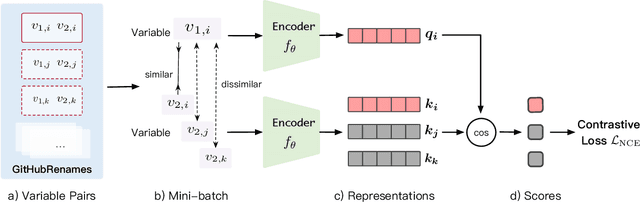
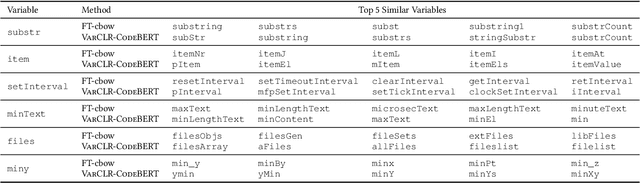
Variable names are critical for conveying intended program behavior. Machine learning-based program analysis methods use variable name representations for a wide range of tasks, such as suggesting new variable names and bug detection. Ideally, such methods could capture semantic relationships between names beyond syntactic similarity, e.g., the fact that the names average and mean are similar. Unfortunately, previous work has found that even the best of previous representation approaches primarily capture relatedness (whether two variables are linked at all), rather than similarity (whether they actually have the same meaning). We propose VarCLR, a new approach for learning semantic representations of variable names that effectively captures variable similarity in this stricter sense. We observe that this problem is an excellent fit for contrastive learning, which aims to minimize the distance between explicitly similar inputs, while maximizing the distance between dissimilar inputs. This requires labeled training data, and thus we construct a novel, weakly-supervised variable renaming dataset mined from GitHub edits. We show that VarCLR enables the effective application of sophisticated, general-purpose language models like BERT, to variable name representation and thus also to related downstream tasks like variable name similarity search or spelling correction. VarCLR produces models that significantly outperform the state-of-the-art on IdBench, an existing benchmark that explicitly captures variable similarity (as distinct from relatedness). Finally, we contribute a release of all data, code, and pre-trained models, aiming to provide a drop-in replacement for variable representations used in either existing or future program analyses that rely on variable names.
Learning to Superoptimize Real-world Programs
Sep 28, 2021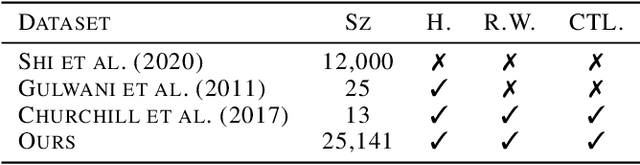


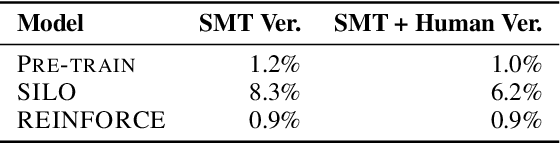
Program optimization is the process of modifying software to execute more efficiently. Because finding the optimal program is generally undecidable, modern compilers usually resort to expert-written heuristic optimizations. In contrast, superoptimizers attempt to find the optimal program by employing significantly more expensive search and constraint solving techniques. Generally, these methods do not scale well to programs in real development scenarios, and as a result superoptimization has largely been confined to small-scale, domain-specific, and/or synthetic program benchmarks. In this paper, we propose a framework to learn to superoptimize real-world programs by using neural sequence-to-sequence models. We introduce the Big Assembly benchmark, a dataset consisting of over 25K real-world functions mined from open-source projects in x86-64 assembly, which enables experimentation on large-scale optimization of real-world programs. We propose an approach, Self Imitation Learning for Optimization (SILO) that is easy to implement and outperforms a standard policy gradient learning approach on our Big Assembly benchmark. Our method, SILO, superoptimizes programs an expected 6.2% of our test set when compared with the gcc version 10.3 compiler's aggressive optimization level -O3. We also report that SILO's rate of superoptimization on our test set is over five times that of a standard policy gradient approach and a model pre-trained on compiler optimization demonstration.