 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPELL: Synthesis of Programmatic Edits using LLMs
Feb 01, 2026Library migration is a common but error-prone task in software development. Developers may need to replace one library with another due to reasons like changing requirements or licensing changes. Migration typically entails updating and rewriting source code manually. While automated migration tools exist, most rely on mining examples from real-world projects that have already undergone similar migrations. However, these data are scarce, and collecting them for arbitrary pairs of libraries is difficult. Moreover, these migration tools often miss out on leveraging modern code transformation infrastructure. In this paper, we present a new approach to automated API migration that sidesteps the limitations described above. Instead of relying on existing migration data or using LLMs directly for transformation, we use LLMs to extract migration examples. Next, we use an Agent to generalize those examples to reusable transformation scripts in PolyglotPiranha, a modern code transformation tool. Our method distills latent migration knowledge from LLMs into structured, testable, and repeatable migration logic, without requiring preexisting corpora or manual engineering effort. Experimental results across Python libraries show that our system can generate diverse migration examples and synthesize transformation scripts that generalize to real-world codebases.
CFaults: Model-Based Diagnosis for Fault Localization in C Programs with Multiple Test Cases
Jul 12, 2024



Debugging is one of the most time-consuming and expensive tasks in software development. Several formula-based fault localization (FBFL) methods have been proposed, but they fail to guarantee a set of diagnoses across all failing tests or may produce redundant diagnoses that are not subset-minimal, particularly for programs with multiple faults. This paper introduces a novel fault localization approach for C programs with multiple faults. CFaults leverages Model-Based Diagnosis (MBD) with multiple observations and aggregates all failing test cases into a unified MaxSAT formula. Consequently, our method guarantees consistency across observations and simplifies the fault localization procedure. Experimental results on two benchmark sets of C programs, TCAS and C-Pack-IPAs, show that CFaults is faster than other FBFL approaches like BugAssist and SNIPER. Moreover, CFaults only generates subset-minimal diagnoses of faulty statements, whereas the other approaches tend to enumerate redundant diagnoses.
* Accepted at FM 2024. 15 pages, 2 figures, 3 tables and 5 listings
MELT: Mining Effective Lightweight Transformations from Pull Requests
Aug 28, 2023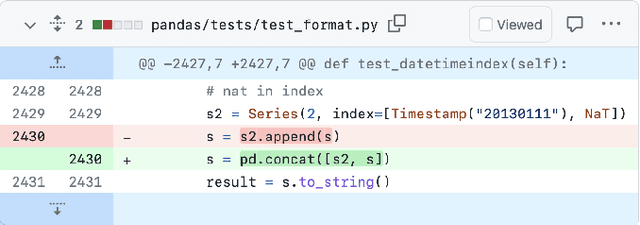
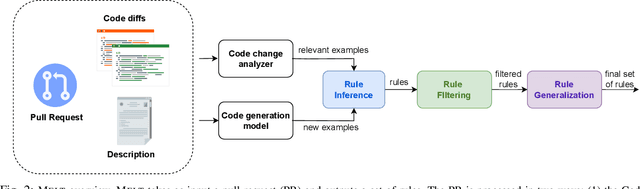
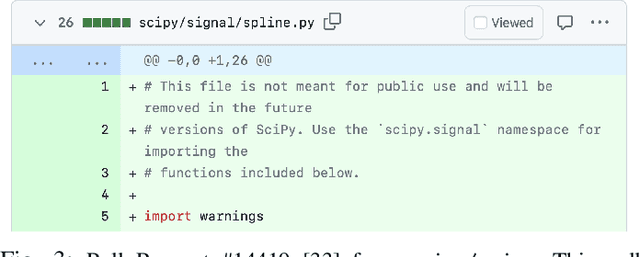

Software developers often struggle to update APIs, leading to manual, time-consuming, and error-prone processes. We introduce MELT, a new approach that generates lightweight API migration rules directly from pull requests in popular library repositories. Our key insight is that pull requests merged into open-source libraries are a rich source of information sufficient to mine API migration rules. By leveraging code examples mined from the library source and automatically generated code examples based on the pull requests, we infer transformation rules in \comby, a language for structural code search and replace. Since inferred rules from single code examples may be too specific, we propose a generalization procedure to make the rules more applicable to client projects. MELT rules are syntax-driven, interpretable, and easily adaptable. Moreover, unlike previous work, our approach enables rule inference to seamlessly integrate into the library workflow, removing the need to wait for client code migrations. We evaluated MELT on pull requests from four popular libraries, successfully mining 461 migration rules from code examples in pull requests and 114 rules from auto-generated code examples. Our generalization procedure increases the number of matches for mined rules by 9x. We applied these rules to client projects and ran their tests, which led to an overall decrease in the number of warnings and fixing some test cases demonstrating MELT's effectiveness in real-world scenarios.
Graph Neural Networks For Mapping Variables Between Programs -- Extended Version
Jul 29, 2023

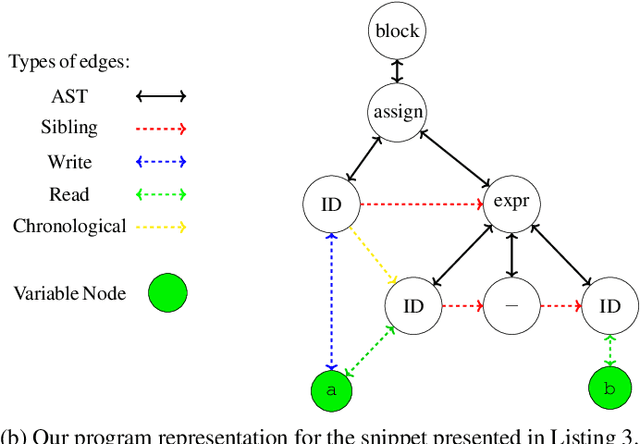

Automated program analysis is a pivotal research domain in many areas of Computer Science -- Formal Methods and Artificial Intelligence, in particular. Due to the undecidability of the problem of program equivalence, comparing two programs is highly challenging. Typically, in order to compare two programs, a relation between both programs' sets of variables is required. Thus, mapping variables between two programs is useful for a panoply of tasks such as program equivalence, program analysis, program repair, and clone detection. In this work, we propose using graph neural networks (GNNs) to map the set of variables between two programs based on both programs' abstract syntax trees (ASTs). To demonstrate the strength of variable mappings, we present three use-cases of these mappings on the task of program repair to fix well-studied and recurrent bugs among novice programmers in introductory programming assignments (IPAs). Experimental results on a dataset of 4166 pairs of incorrect/correct programs show that our approach correctly maps 83% of the evaluation dataset. Moreover, our experiments show that the current state-of-the-art on program repair, greatly dependent on the programs' structure, can only repair about 72% of the incorrect programs. In contrast, our approach, which is solely based on variable mappings, can repair around 88.5%.
UpMax: User partitioning for MaxSAT
May 25, 2023It has been shown that Maximum Satisfiability (MaxSAT) problem instances can be effectively solved by partitioning the set of soft clauses into several disjoint sets. The partitioning methods can be based on clause weights (e.g., stratification) or based on graph representations of the formula. Afterwards, a merge procedure is applied to guarantee that an optimal solution is found. This paper proposes a new framework called UpMax that decouples the partitioning procedure from the MaxSAT solving algorithms. As a result, new partitioning procedures can be defined independently of the MaxSAT algorithm to be used. Moreover, this decoupling also allows users that build new MaxSAT formulas to propose partition schemes based on knowledge of the problem to be solved. We illustrate this approach using several problems and show that partitioning has a large impact on the performance of unsatisfiability-based MaxSAT algorithms.
InvAASTCluster: On Applying Invariant-Based Program Clustering to Introductory Programming Assignments
Jun 29, 2022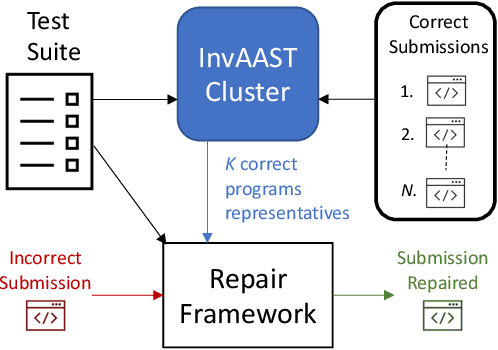

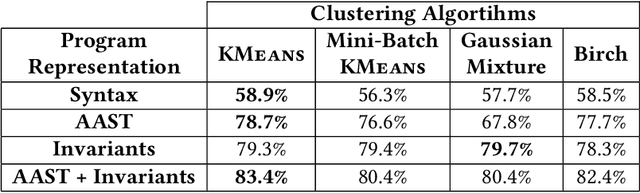
Due to the vast number of students enrolled in Massive Open Online Courses (MOOCs), there has been an increasing number of automated program repair techniques focused on introductory programming assignments (IPAs). Such state-of-the-art techniques use program clustering to take advantage of previous correct student implementations to repair a given new incorrect submission. Usually, these repair techniques use clustering methods since analyzing all available correct student submissions to repair a program is not feasible. The clustering methods use program representations based on several features such as abstract syntax tree (AST), syntax, control flow, and data flow. However, these features are sometimes brittle when representing semantically similar programs. This paper proposes InvAASTCluster, a novel approach for program clustering that takes advantage of dynamically generated program invariants observed over several program executions to cluster semantically equivalent IPAs. Our main objective is to find a more suitable representation of programs using a combination of the program's semantics, through its invariants, and its structure, through its anonymized abstract syntax tree. The evaluation of InvAASTCluster shows that the proposed program representation outperforms syntax-based representations when clustering a set of different correct IPAs. Furthermore, we integrate InvAASTCluster into a state-of-the-art clustering-based program repair tool and evaluate it on a set of IPAs. Our results show that InvAASTCluster advances the current state-of-the-art when used by clustering-based program repair tools by repairing a larger number of students' programs in a shorter amount of time.
C-Pack of IPAs: A C90 Program Benchmark of Introductory Programming Assignments
Jun 17, 2022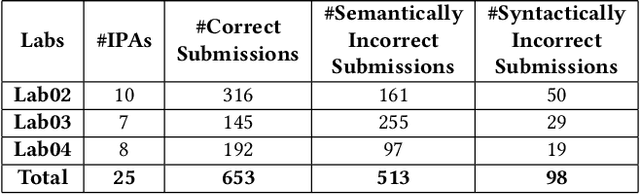
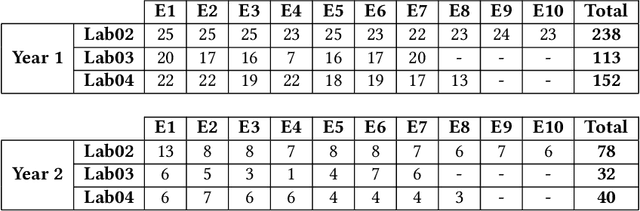
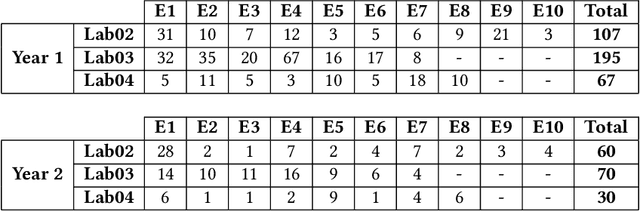
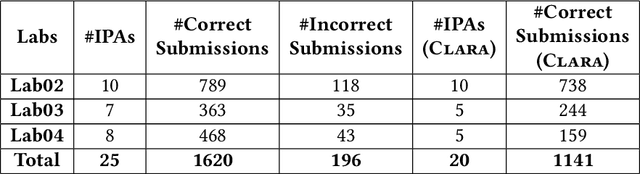
Due to the vast number of students enrolled in Massive Open Online Courses (MOOCs), there has been an increasing number of automated program repair techniques focused on introductory programming assignments (IPAs). Such techniques take advantage of previous correct student implementations in order to provide automated, comprehensive, and personalized feedback to students. This paper presents C-Pack-IPAs, a publicly available benchmark of students' programs submitted for 25 different IPAs. C-Pack-IPAs contains semantically correct, semantically incorrect, and syntactically incorrect programs plus a test suite for each IPA. Hence, C-Pack-IPAs can be used to help evaluate the development of novel semantic, as well as syntactic, automated program repair frameworks, focused on providing feedback to novice programmers.
New Core-Guided and Hitting Set Algorithms for Multi-Objective Combinatorial Optimization
Apr 22, 2022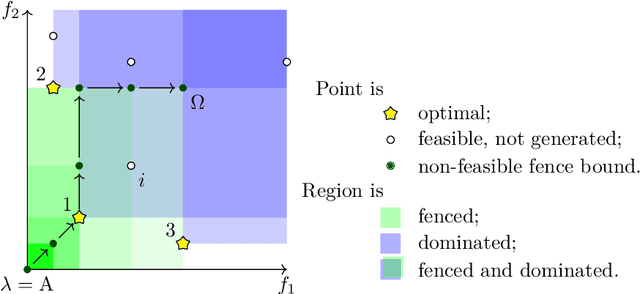
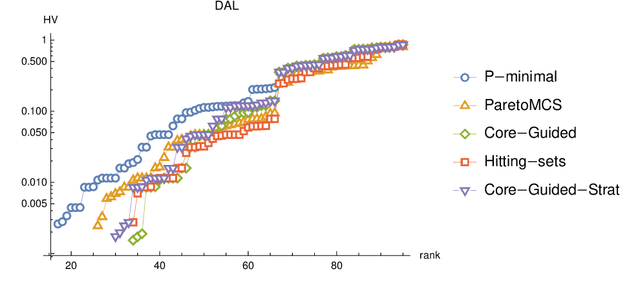
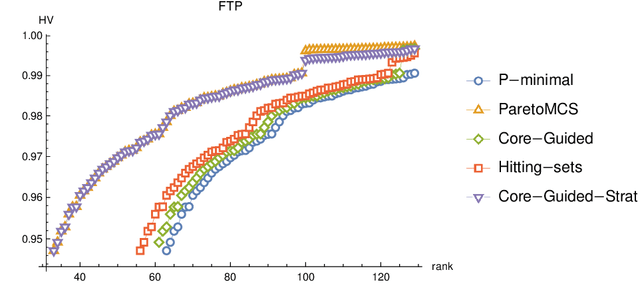
In the last decade, a plethora of algorithms for single-objective Boolean optimization has been proposed that rely on the iterative usage of a highly effective Propositional Satisfiability (SAT) solver. But the use of SAT solvers in Multi-Objective Combinatorial Optimization (MOCO) algorithms is still scarce. Due to this shortage of efficient tools for MOCO, many real-world applications formulated as multi-objective are simplified to single-objective, using either a linear combination or a lexicographic ordering of the objective functions to optimize. In this paper, we extend the state of the art of MOCO solvers with two novel unsatisfiability-based algorithms. The first is a core-guided MOCO solver. The second is a hitting set-based MOCO solver. Experimental results obtained in a wide range of benchmark instances show that our new unsatisfiability-based algorithms can outperform state-of-the-art SAT-based algorithms for MOCO.
Exact and approximate determination of the Pareto set using minimal correction subsets
Apr 14, 2022



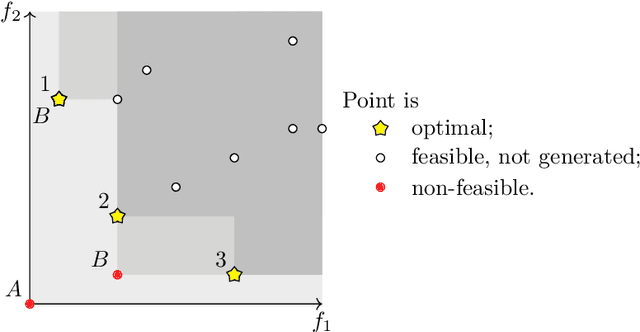
Recently, it has been shown that the enumeration of Minimal Correction Subsets (MCS) of Boolean formulas allows solving Multi-Objective Boolean Optimization (MOBO) formulations. However, a major drawback of this approach is that most MCSs do not correspond to Pareto-optimal solutions. In fact, one can only know that a given MCS corresponds to a Pareto-optimal solution when all MCSs are enumerated. Moreover, if it is not possible to enumerate all MCSs, then there is no guarantee of the quality of the approximation of the Pareto frontier. This paper extends the state of the art for solving MOBO using MCSs. First, we show that it is possible to use MCS enumeration to solve MOBO problems such that each MCS necessarily corresponds to a Pareto-optimal solution. Additionally, we also propose two new algorithms that can find a (1 + {\varepsilon})-approximation of the Pareto frontier using MCS enumeration. Experimental results in several benchmark sets show that the newly proposed algorithms allow finding better approximations of the Pareto frontier than state-of-the-art algorithms, and with guaranteed approximation ratios.
Reflections on "Incremental Cardinality Constraints for MaxSAT"
Oct 10, 2019

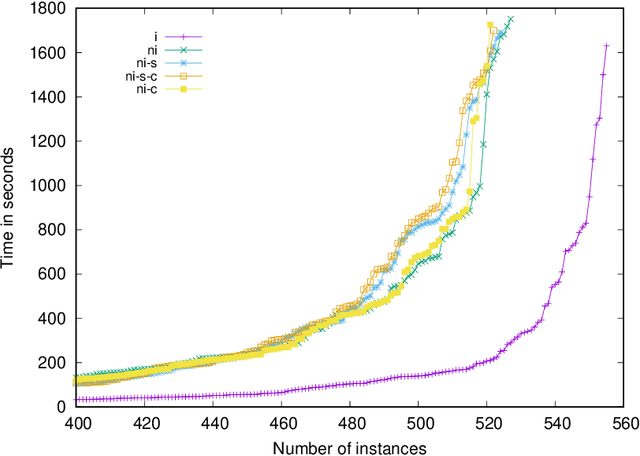
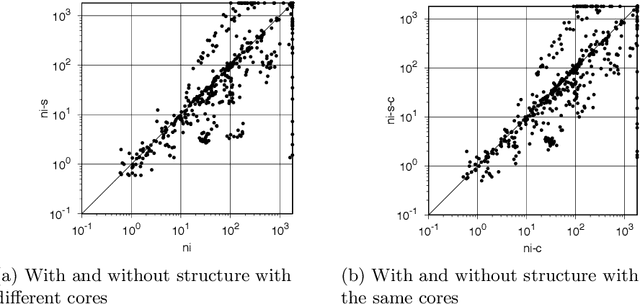
To celebrate the first 25 years of the International Conference on Principles and Practice of Constraint Programming (CP) the editors invited the authors of the most cited paper of each year to write a commentary on their paper. This report describes our reflections on the CP 2014 paper "Incremental Cardinality Constraints for MaxSAT" and its impact on the Maximum Satisfiability community and beyond.