 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Reasoning with Large Language Models via Preference-Based Maximum Satisfiability
May 28, 2026Large Language Models (LLMs) excel at understanding natural language but struggle with optimisation tasks involving multiple constraints and user-defined preferences, which commonly arise in domains such as robotics. We propose a hybrid reasoning approach in which LLMs externalise reasoning through code generation. Given a natural language problem description, an LLM generates Python code that encodes user-defined constraints and preferences as a preference-based Maximum Satisfiability (MaxSAT) problem, which is then solved by an exact MaxSAT solver. To ensure correctness, solutions returned by the model-generated code are independently verified for feasibility and optimality against a canonical MaxSAT encoding, allowing for different encodings and multiple optimal solutions. We evaluate our approach using both open-source and closed-access LLMs on three families of preference-based reasoning tasks, and compare it against direct-answer, chain-of-thought, and program-of-thought baselines using the same models. While these baselines rarely produce feasible solutions, the MaxSAT-based pipeline achieves substantially higher acceptance rates, in some cases exceeding 80%. Our results demonstrate that LLM-driven code generation combined with preference-based MaxSAT enables solver-verifiable optimisation with respect to generated encodings, and substantially improves correctness under independently verified reference semantics.
PyVeritas: On Verifying Python via LLM-Based Transpilation and Bounded Model Checking for C
Aug 11, 2025Python has become the dominant language for general-purpose programming, yet it lacks robust tools for formal verification. In contrast, programmers working in languages such as C benefit from mature model checkers, for example CBMC, which enable exhaustive symbolic reasoning and fault localisation. The inherent complexity of Python, coupled with the verbosity and low-level nature of existing transpilers (e.g., Cython), have historically limited the applicability of formal verification to Python programs. In this paper, we propose PyVeritas, a novel framework that leverages Large Language Models (LLMs) for high-level transpilation from Python to C, followed by bounded model checking and MaxSAT-based fault localisation in the generated C code. PyVeritas enables verification and bug localisation for Python code using existing model checking tools for C. Our empirical evaluation on two Python benchmarks demonstrates that LLM-based transpilation can achieve a high degree of accuracy, up to 80--90% for some LLMs, enabling effective development environment that supports assertion-based verification and interpretable fault diagnosis for small yet non-trivial Python programs.
Are Large Language Models Robust in Understanding Code Against Semantics-Preserving Mutations?
May 15, 2025Understanding the reasoning and robustness of Large Language Models (LLMs) is critical for their reliable use in programming tasks. While recent studies have assessed LLMs' ability to predict program outputs, most focus solely on the accuracy of those predictions, without evaluating the reasoning behind them. Moreover, it has been observed on mathematical reasoning tasks that LLMs can arrive at correct answers through flawed logic, raising concerns about similar issues in code understanding. In this work, we evaluate whether state-of-the-art LLMs with up to 8B parameters can reason about Python programs or are simply guessing. We apply five semantics-preserving code mutations: renaming variables, mirroring comparison expressions, swapping if-else branches, converting for loops to while, and loop unrolling. These mutations maintain program semantics while altering its syntax. We evaluated six LLMs and performed a human expert analysis using LiveCodeBench to assess whether the correct predictions are based on sound reasoning. We also evaluated prediction stability across different code mutations on LiveCodeBench and CruxEval. Our findings show that some LLMs, such as Llama3.2, produce correct predictions based on flawed reasoning in up to 61% of cases. Furthermore, LLMs often change predictions in response to our code mutations, indicating limited robustness in their semantic understanding.
CFaults: Model-Based Diagnosis for Fault Localization in C Programs with Multiple Test Cases
Jul 12, 2024



Debugging is one of the most time-consuming and expensive tasks in software development. Several formula-based fault localization (FBFL) methods have been proposed, but they fail to guarantee a set of diagnoses across all failing tests or may produce redundant diagnoses that are not subset-minimal, particularly for programs with multiple faults. This paper introduces a novel fault localization approach for C programs with multiple faults. CFaults leverages Model-Based Diagnosis (MBD) with multiple observations and aggregates all failing test cases into a unified MaxSAT formula. Consequently, our method guarantees consistency across observations and simplifies the fault localization procedure. Experimental results on two benchmark sets of C programs, TCAS and C-Pack-IPAs, show that CFaults is faster than other FBFL approaches like BugAssist and SNIPER. Moreover, CFaults only generates subset-minimal diagnoses of faulty statements, whereas the other approaches tend to enumerate redundant diagnoses.
* Accepted at FM 2024. 15 pages, 2 figures, 3 tables and 5 listings
Graph Neural Networks For Mapping Variables Between Programs -- Extended Version
Jul 29, 2023


Automated program analysis is a pivotal research domain in many areas of Computer Science -- Formal Methods and Artificial Intelligence, in particular. Due to the undecidability of the problem of program equivalence, comparing two programs is highly challenging. Typically, in order to compare two programs, a relation between both programs' sets of variables is required. Thus, mapping variables between two programs is useful for a panoply of tasks such as program equivalence, program analysis, program repair, and clone detection. In this work, we propose using graph neural networks (GNNs) to map the set of variables between two programs based on both programs' abstract syntax trees (ASTs). To demonstrate the strength of variable mappings, we present three use-cases of these mappings on the task of program repair to fix well-studied and recurrent bugs among novice programmers in introductory programming assignments (IPAs). Experimental results on a dataset of 4166 pairs of incorrect/correct programs show that our approach correctly maps 83% of the evaluation dataset. Moreover, our experiments show that the current state-of-the-art on program repair, greatly dependent on the programs' structure, can only repair about 72% of the incorrect programs. In contrast, our approach, which is solely based on variable mappings, can repair around 88.5%.
UpMax: User partitioning for MaxSAT
May 25, 2023It has been shown that Maximum Satisfiability (MaxSAT) problem instances can be effectively solved by partitioning the set of soft clauses into several disjoint sets. The partitioning methods can be based on clause weights (e.g., stratification) or based on graph representations of the formula. Afterwards, a merge procedure is applied to guarantee that an optimal solution is found. This paper proposes a new framework called UpMax that decouples the partitioning procedure from the MaxSAT solving algorithms. As a result, new partitioning procedures can be defined independently of the MaxSAT algorithm to be used. Moreover, this decoupling also allows users that build new MaxSAT formulas to propose partition schemes based on knowledge of the problem to be solved. We illustrate this approach using several problems and show that partitioning has a large impact on the performance of unsatisfiability-based MaxSAT algorithms.
InvAASTCluster: On Applying Invariant-Based Program Clustering to Introductory Programming Assignments
Jun 29, 2022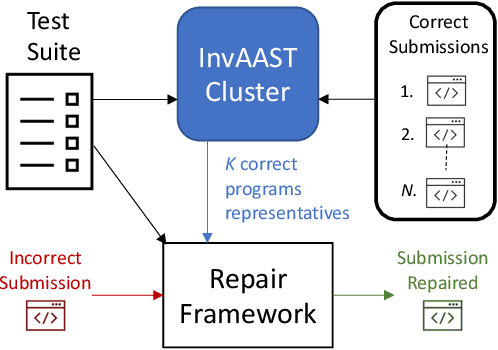

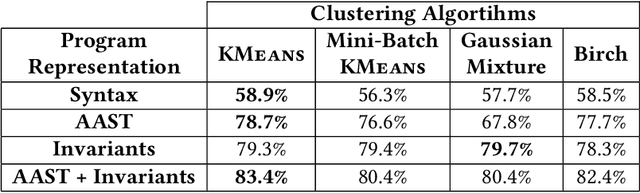
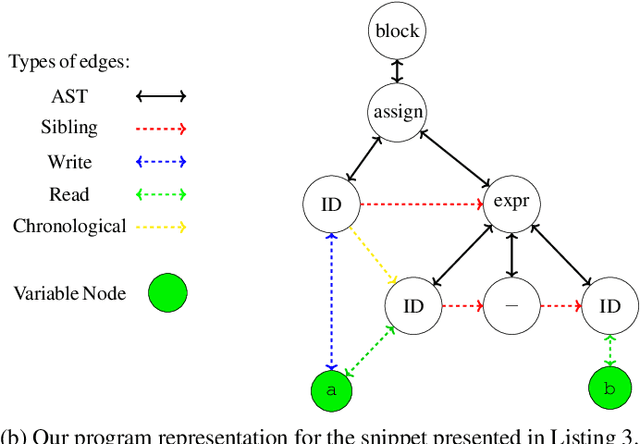
Due to the vast number of students enrolled in Massive Open Online Courses (MOOCs), there has been an increasing number of automated program repair techniques focused on introductory programming assignments (IPAs). Such state-of-the-art techniques use program clustering to take advantage of previous correct student implementations to repair a given new incorrect submission. Usually, these repair techniques use clustering methods since analyzing all available correct student submissions to repair a program is not feasible. The clustering methods use program representations based on several features such as abstract syntax tree (AST), syntax, control flow, and data flow. However, these features are sometimes brittle when representing semantically similar programs. This paper proposes InvAASTCluster, a novel approach for program clustering that takes advantage of dynamically generated program invariants observed over several program executions to cluster semantically equivalent IPAs. Our main objective is to find a more suitable representation of programs using a combination of the program's semantics, through its invariants, and its structure, through its anonymized abstract syntax tree. The evaluation of InvAASTCluster shows that the proposed program representation outperforms syntax-based representations when clustering a set of different correct IPAs. Furthermore, we integrate InvAASTCluster into a state-of-the-art clustering-based program repair tool and evaluate it on a set of IPAs. Our results show that InvAASTCluster advances the current state-of-the-art when used by clustering-based program repair tools by repairing a larger number of students' programs in a shorter amount of time.
C-Pack of IPAs: A C90 Program Benchmark of Introductory Programming Assignments
Jun 17, 2022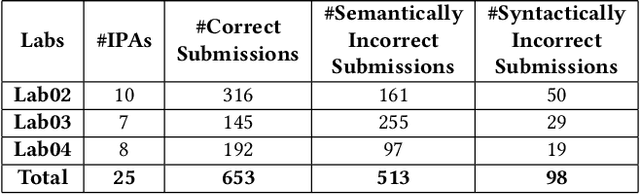
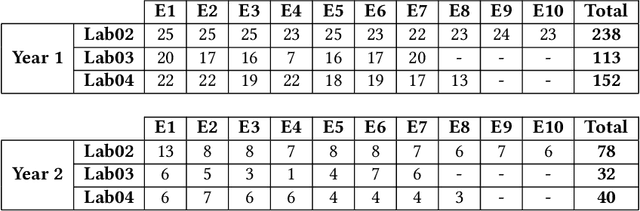
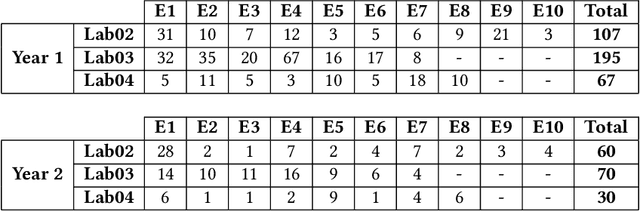
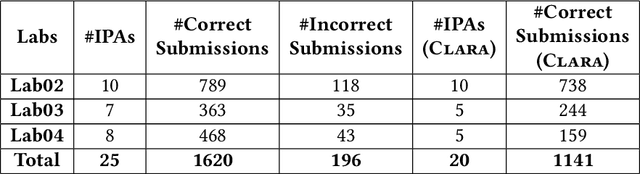
Due to the vast number of students enrolled in Massive Open Online Courses (MOOCs), there has been an increasing number of automated program repair techniques focused on introductory programming assignments (IPAs). Such techniques take advantage of previous correct student implementations in order to provide automated, comprehensive, and personalized feedback to students. This paper presents C-Pack-IPAs, a publicly available benchmark of students' programs submitted for 25 different IPAs. C-Pack-IPAs contains semantically correct, semantically incorrect, and syntactically incorrect programs plus a test suite for each IPA. Hence, C-Pack-IPAs can be used to help evaluate the development of novel semantic, as well as syntactic, automated program repair frameworks, focused on providing feedback to novice programmers.