 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPELL: Synthesis of Programmatic Edits using LLMs
Feb 01, 2026Library migration is a common but error-prone task in software development. Developers may need to replace one library with another due to reasons like changing requirements or licensing changes. Migration typically entails updating and rewriting source code manually. While automated migration tools exist, most rely on mining examples from real-world projects that have already undergone similar migrations. However, these data are scarce, and collecting them for arbitrary pairs of libraries is difficult. Moreover, these migration tools often miss out on leveraging modern code transformation infrastructure. In this paper, we present a new approach to automated API migration that sidesteps the limitations described above. Instead of relying on existing migration data or using LLMs directly for transformation, we use LLMs to extract migration examples. Next, we use an Agent to generalize those examples to reusable transformation scripts in PolyglotPiranha, a modern code transformation tool. Our method distills latent migration knowledge from LLMs into structured, testable, and repeatable migration logic, without requiring preexisting corpora or manual engineering effort. Experimental results across Python libraries show that our system can generate diverse migration examples and synthesize transformation scripts that generalize to real-world codebases.
Learning to Triage Taint Flows Reported by Dynamic Program Analysis in Node.js Packages
Oct 23, 2025



Program analysis tools often produce large volumes of candidate vulnerability reports that require costly manual review, creating a practical challenge: how can security analysts prioritize the reports most likely to be true vulnerabilities? This paper investigates whether machine learning can be applied to prioritizing vulnerabilities reported by program analysis tools. We focus on Node.js packages and collect a benchmark of 1,883 Node.js packages, each containing one reported ACE or ACI vulnerability. We evaluate a variety of machine learning approaches, including classical models, graph neural networks (GNNs), large language models (LLMs), and hybrid models that combine GNN and LLMs, trained on data based on a dynamic program analysis tool's output. The top LLM achieves $F_{1} {=} 0.915$, while the best GNN and classical ML models reaching $F_{1} {=} 0.904$. At a less than 7% false-negative rate, the leading model eliminates 66.9% of benign packages from manual review, taking around 60 ms per package. If the best model is tuned to operate at a precision level of 0.8 (i.e., allowing 20% false positives amongst all warnings), our approach can detect 99.2% of exploitable taint flows while missing only 0.8%, demonstrating strong potential for real-world vulnerability triage.
Hypergraph-Guided Regex Filter Synthesis for Event-Based Anomaly Detection
Sep 08, 2025We propose HyGLAD, a novel algorithm that automatically builds a set of interpretable patterns that model event data. These patterns can then be used to detect event-based anomalies in a stationary system, where any deviation from past behavior may indicate malicious activity. The algorithm infers equivalence classes of entities with similar behavior observed from the events, and then builds regular expressions that capture the values of those entities. As opposed to deep-learning approaches, the regular expressions are directly interpretable, which also translates to interpretable anomalies. We evaluate HyGLAD against all 7 unsupervised anomaly detection methods from DeepOD on five datasets from real-world systems. The experimental results show that on average HyGLAD outperforms existing deep-learning methods while being an order of magnitude more efficient in training and inference (single CPU vs GPU). Precision improved by 1.2x and recall by 1.3x compared to the second-best baseline.
Security Vulnerability Detection with Multitask Self-Instructed Fine-Tuning of Large Language Models
Jun 09, 2024
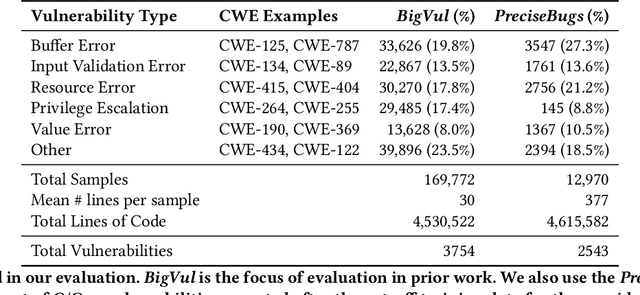
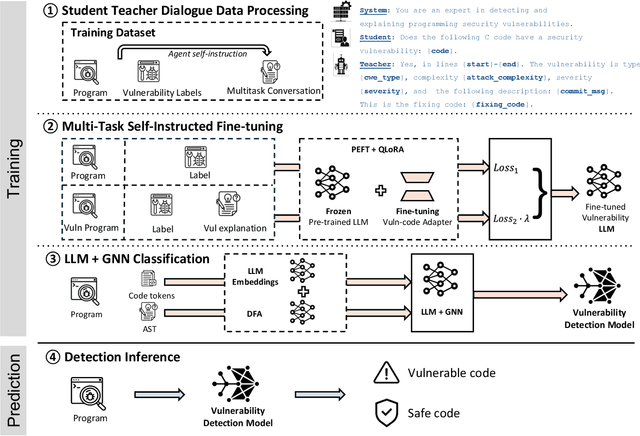
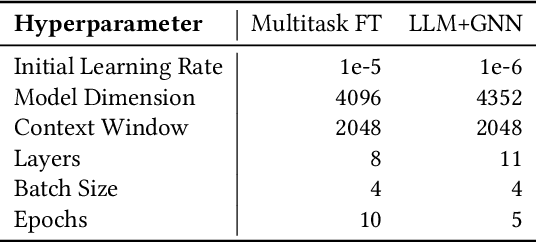
Software security vulnerabilities allow attackers to perform malicious activities to disrupt software operations. Recent Transformer-based language models have significantly advanced vulnerability detection, surpassing the capabilities of static analysis based deep learning models. However, language models trained solely on code tokens do not capture either the explanation of vulnerability type or the data flow structure information of code, both of which are crucial for vulnerability detection. We propose a novel technique that integrates a multitask sequence-to-sequence LLM with pro-gram control flow graphs encoded as a graph neural network to achieve sequence-to-classification vulnerability detection. We introduce MSIVD, multitask self-instructed fine-tuning for vulnerability detection, inspired by chain-of-thought prompting and LLM self-instruction. Our experiments demonstrate that MSIVD achieves superior performance, outperforming the highest LLM-based vulnerability detector baseline (LineVul), with a F1 score of 0.92 on the BigVul dataset, and 0.48 on the PreciseBugs dataset. By training LLMs and GNNs simultaneously using a combination of code and explanatory metrics of a vulnerable program, MSIVD represents a promising direction for advancing LLM-based vulnerability detection that generalizes to unseen data. Based on our findings, we further discuss the necessity for new labelled security vulnerability datasets, as recent LLMs have seen or memorized prior datasets' held-out evaluation data.
Large Language Models for Test-Free Fault Localization
Oct 03, 2023



Fault Localization (FL) aims to automatically localize buggy lines of code, a key first step in many manual and automatic debugging tasks. Previous FL techniques assume the provision of input tests, and often require extensive program analysis, program instrumentation, or data preprocessing. Prior work on deep learning for APR struggles to learn from small datasets and produces limited results on real-world programs. Inspired by the ability of large language models (LLMs) of code to adapt to new tasks based on very few examples, we investigate the applicability of LLMs to line level fault localization. Specifically, we propose to overcome the left-to-right nature of LLMs by fine-tuning a small set of bidirectional adapter layers on top of the representations learned by LLMs to produce LLMAO, the first language model based fault localization approach that locates buggy lines of code without any test coverage information. We fine-tune LLMs with 350 million, 6 billion, and 16 billion parameters on small, manually curated corpora of buggy programs such as the Defects4J corpus. We observe that our technique achieves substantially more confidence in fault localization when built on the larger models, with bug localization performance scaling consistently with the LLM size. Our empirical evaluation shows that LLMAO improves the Top-1 results over the state-of-the-art machine learning fault localization (MLFL) baselines by 2.3%-54.4%, and Top-5 results by 14.4%-35.6%. LLMAO is also the first FL technique trained using a language model architecture that can detect security vulnerabilities down to the code line level.
MELT: Mining Effective Lightweight Transformations from Pull Requests
Aug 28, 2023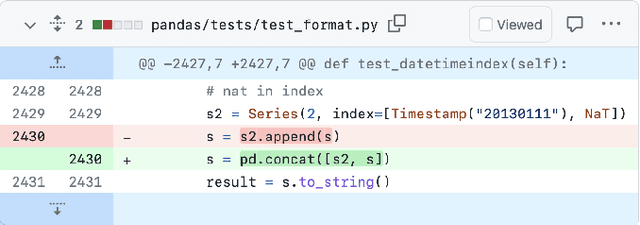
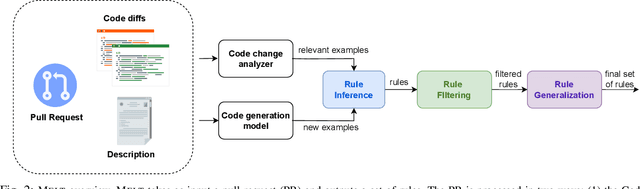
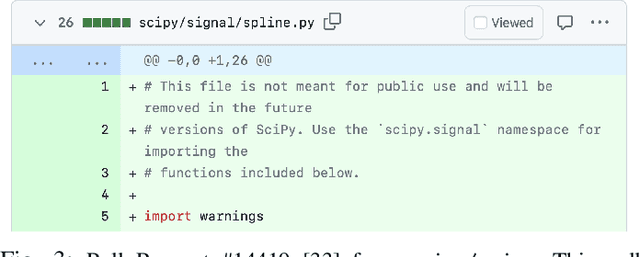

Software developers often struggle to update APIs, leading to manual, time-consuming, and error-prone processes. We introduce MELT, a new approach that generates lightweight API migration rules directly from pull requests in popular library repositories. Our key insight is that pull requests merged into open-source libraries are a rich source of information sufficient to mine API migration rules. By leveraging code examples mined from the library source and automatically generated code examples based on the pull requests, we infer transformation rules in \comby, a language for structural code search and replace. Since inferred rules from single code examples may be too specific, we propose a generalization procedure to make the rules more applicable to client projects. MELT rules are syntax-driven, interpretable, and easily adaptable. Moreover, unlike previous work, our approach enables rule inference to seamlessly integrate into the library workflow, removing the need to wait for client code migrations. We evaluated MELT on pull requests from four popular libraries, successfully mining 461 migration rules from code examples in pull requests and 114 rules from auto-generated code examples. Our generalization procedure increases the number of matches for mined rules by 9x. We applied these rules to client projects and ran their tests, which led to an overall decrease in the number of warnings and fixing some test cases demonstrating MELT's effectiveness in real-world scenarios.
UpMax: User partitioning for MaxSAT
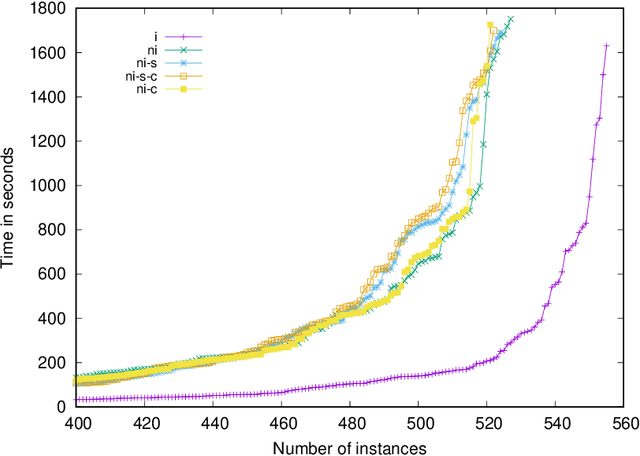
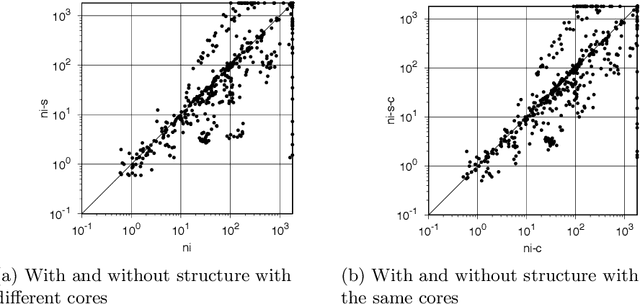
May 25, 2023It has been shown that Maximum Satisfiability (MaxSAT) problem instances can be effectively solved by partitioning the set of soft clauses into several disjoint sets. The partitioning methods can be based on clause weights (e.g., stratification) or based on graph representations of the formula. Afterwards, a merge procedure is applied to guarantee that an optimal solution is found. This paper proposes a new framework called UpMax that decouples the partitioning procedure from the MaxSAT solving algorithms. As a result, new partitioning procedures can be defined independently of the MaxSAT algorithm to be used. Moreover, this decoupling also allows users that build new MaxSAT formulas to propose partition schemes based on knowledge of the problem to be solved. We illustrate this approach using several problems and show that partitioning has a large impact on the performance of unsatisfiability-based MaxSAT algorithms.
FOREST: An Interactive Multi-tree Synthesizer for Regular Expressions
Dec 28, 2020



Form validators based on regular expressions are often used on digital forms to prevent users from inserting data in the wrong format. However, writing these validators can pose a challenge to some users. We present FOREST, a regular expression synthesizer for digital form validations. FOREST produces a regular expression that matches the desired pattern for the input values and a set of conditions over capturing groups that ensure the validity of integer values in the input. Our synthesis procedure is based on enumerative search and uses a Satisfiability Modulo Theories (SMT) solver to explore and prune the search space. We propose a novel representation for regular expressions synthesis, multi-tree, which induces patterns in the examples and uses them to split the problem through a divide-and-conquer approach. We also present a new SMT encoding to synthesize capture conditions for a given regular expression. To increase confidence in the synthesized regular expression, we implement user interaction based on distinguishing inputs. We evaluated FOREST on real-world form-validation instances using regular expressions. Experimental results show that FOREST successfully returns the desired regular expression in 72% of the instances and outperforms REGEL, a state-of-the-art regular expression synthesizer.
Reflections on "Incremental Cardinality Constraints for MaxSAT"
Oct 10, 2019

To celebrate the first 25 years of the International Conference on Principles and Practice of Constraint Programming (CP) the editors invited the authors of the most cited paper of each year to write a commentary on their paper. This report describes our reflections on the CP 2014 paper "Incremental Cardinality Constraints for MaxSAT" and its impact on the Maximum Satisfiability community and beyond.
Approximation Strategies for Incomplete MaxSAT
Jun 19, 2018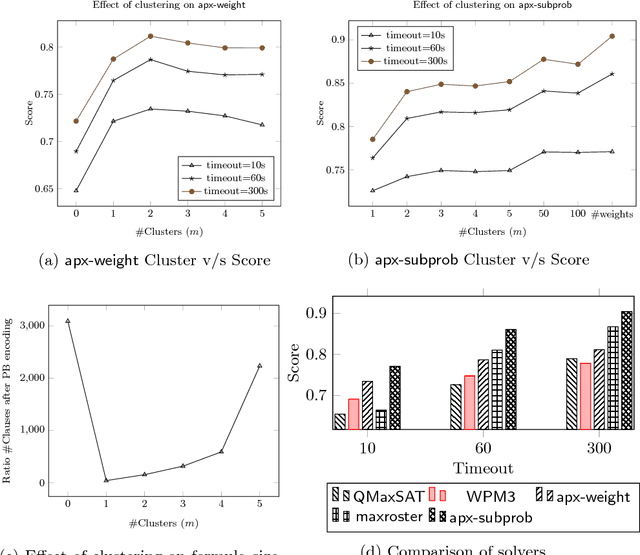
Incomplete MaxSAT solving aims to quickly find a solution that attempts to minimize the sum of the weights of the unsatisfied soft clauses without providing any optimality guarantees. In this paper, we propose two approximation strategies for improving incomplete MaxSAT solving. In one of the strategies, we cluster the weights and approximate them with a representative weight. In another strategy, we break up the problem of minimizing the sum of weights of unsatisfiable clauses into multiple minimization subproblems. Experimental results show that approximation strategies can be used to find better solutions than the best incomplete solvers in the MaxSAT Evaluation 2017.