 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeTracer: Towards Traceable Agent States
Apr 14, 2026Code agents are advancing rapidly, but debugging them is becoming increasingly difficult. As frameworks orchestrate parallel tool calls and multi-stage workflows over complex tasks, making the agent's state transitions and error propagation hard to observe. In these runs, an early misstep can trap the agent in unproductive loops or even cascade into fundamental errors, forming hidden error chains that make it hard to tell when the agent goes off track and why. Existing agent tracing analyses either focus on simple interaction or rely on small-scale manual inspection, which limits their scalability and usefulness for real coding workflows. We present CodeTracer, a tracing architecture that parses heterogeneous run artifacts through evolving extractors, reconstructs the full state transition history as a hierarchical trace tree with persistent memory, and performs failure onset localization to pinpoint the failure origin and its downstream chain. To enable systematic evaluation, we construct CodeTraceBench from a large collection of executed trajectories generated by four widely used code agent frameworks on diverse code tasks (e.g., bug fixing, refactoring, and terminal interaction), with supervision at both the stage and step levels for failure localization. Experiments show that CodeTracer substantially outperforms direct prompting and lightweight baselines, and that replaying its diagnostic signals consistently recovers originally failed runs under matched budgets. Our code and data are publicly available.
ContextBench: A Benchmark for Context Retrieval in Coding Agents
Feb 05, 2026LLM-based coding agents have shown strong performance on automated issue resolution benchmarks, yet existing evaluations largely focus on final task success, providing limited insight into how agents retrieve and use code context during problem solving. We introduce ContextBench, a process-oriented evaluation of context retrieval in coding agents. ContextBench consists of 1,136 issue-resolution tasks from 66 repositories across eight programming languages, each augmented with human-annotated gold contexts. We further implement an automated evaluation framework that tracks agent trajectories and measures context recall, precision, and efficiency throughout issue resolution. Using ContextBench, we evaluate four frontier LLMs and five coding agents. Our results show that sophisticated agent scaffolding yields only marginal gains in context retrieval ("The Bitter Lesson" of coding agents), LLMs consistently favor recall over precision, and substantial gaps exist between explored and utilized context. ContextBench augments existing end-to-end benchmarks with intermediate gold-context metrics that unbox the issue-resolution process. These contexts offer valuable intermediate signals for guiding LLM reasoning in software tasks. Data and code are available at: https://cioutn.github.io/context-bench/.
Generative AI for Testing of Autonomous Driving Systems: A Survey
Aug 27, 2025Autonomous driving systems (ADS) have been an active area of research, with the potential to deliver significant benefits to society. However, before large-scale deployment on public roads, extensive testing is necessary to validate their functionality and safety under diverse driving conditions. Therefore, different testing approaches are required, and achieving effective and efficient testing of ADS remains an open challenge. Recently, generative AI has emerged as a powerful tool across many domains, and it is increasingly being applied to ADS testing due to its ability to interpret context, reason about complex tasks, and generate diverse outputs. To gain a deeper understanding of its role in ADS testing, we systematically analyzed 91 relevant studies and synthesized their findings into six major application categories, primarily centered on scenario-based testing of ADS. We also reviewed their effectiveness and compiled a wide range of datasets, simulators, ADS, metrics, and benchmarks used for evaluation, while identifying 27 limitations. This survey provides an overview and practical insights into the use of generative AI for testing ADS, highlights existing challenges, and outlines directions for future research in this rapidly evolving field.
What Exactly Does Guidance Do in Masked Discrete Diffusion Models
Jun 12, 2025We study masked discrete diffusion models with classifier-free guidance (CFG). Assuming no score error nor discretization error, we derive an explicit solution to the guided reverse dynamics, so that how guidance influences the sampling behavior can be precisely characterized. When the full data distribution is a mixture over classes and the goal is to sample from a specific class, guidance amplifies class-specific regions while suppresses regions shared with other classes. This effect depends on the guidance strength $w$ and induces distinct covariance structures in the sampled distribution. Notably, we observe quantitatively different behaviors in $1$D and $2$D. We also show that for large $w$, the decay rate of the total variation ($\mathrm{TV}$) along the reverse dynamics is double-exponential in $w$ for both $1$D and $2$D. These findings highlight the role of guidance, not just in shaping the output distribution, but also in controlling the dynamics of the sampling trajectory. Our theoretical analysis is supported by experiments that illustrate the geometric effects of guidance and its impact on convergence.
Security Vulnerability Detection with Multitask Self-Instructed Fine-Tuning of Large Language Models
Jun 09, 2024
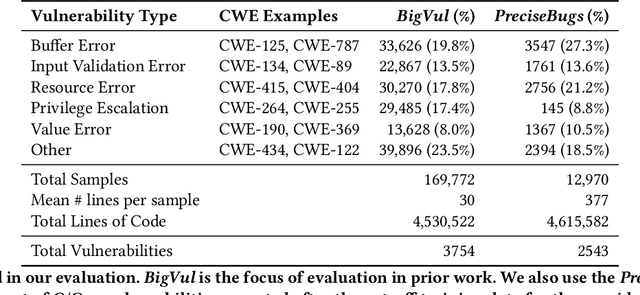
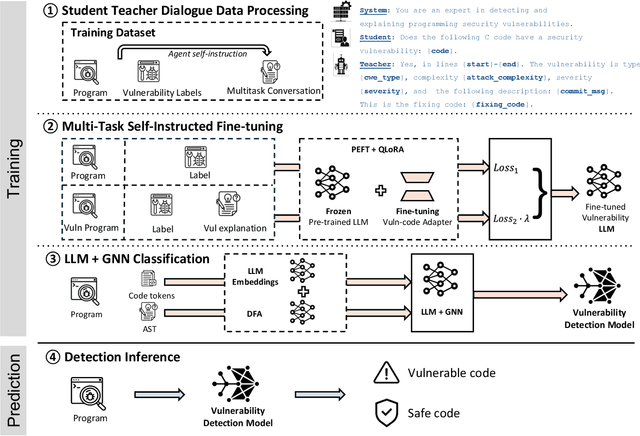
Software security vulnerabilities allow attackers to perform malicious activities to disrupt software operations. Recent Transformer-based language models have significantly advanced vulnerability detection, surpassing the capabilities of static analysis based deep learning models. However, language models trained solely on code tokens do not capture either the explanation of vulnerability type or the data flow structure information of code, both of which are crucial for vulnerability detection. We propose a novel technique that integrates a multitask sequence-to-sequence LLM with pro-gram control flow graphs encoded as a graph neural network to achieve sequence-to-classification vulnerability detection. We introduce MSIVD, multitask self-instructed fine-tuning for vulnerability detection, inspired by chain-of-thought prompting and LLM self-instruction. Our experiments demonstrate that MSIVD achieves superior performance, outperforming the highest LLM-based vulnerability detector baseline (LineVul), with a F1 score of 0.92 on the BigVul dataset, and 0.48 on the PreciseBugs dataset. By training LLMs and GNNs simultaneously using a combination of code and explanatory metrics of a vulnerable program, MSIVD represents a promising direction for advancing LLM-based vulnerability detection that generalizes to unseen data. Based on our findings, we further discuss the necessity for new labelled security vulnerability datasets, as recent LLMs have seen or memorized prior datasets' held-out evaluation data.
MemoryBank: Enhancing Large Language Models with Long-Term Memory
May 21, 2023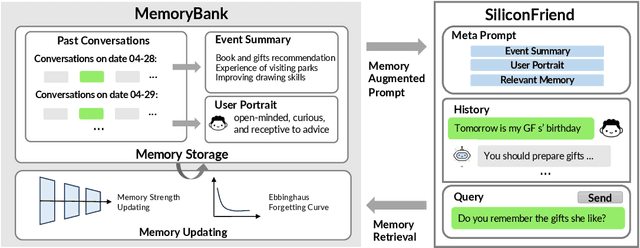


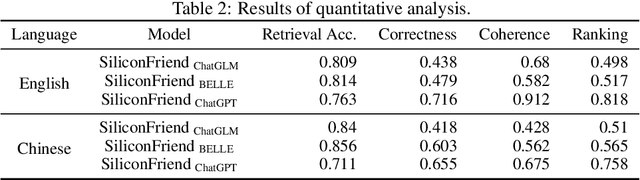
Revolutionary advancements in Large Language Models have drastically reshaped our interactions with artificial intelligence systems. Despite this, a notable hindrance remains-the deficiency of a long-term memory mechanism within these models. This shortfall becomes increasingly evident in situations demanding sustained interaction, such as personal companion systems and psychological counseling. Therefore, we propose MemoryBank, a novel memory mechanism tailored for LLMs. MemoryBank enables the models to summon relevant memories, continually evolve through continuous memory updates, comprehend, and adapt to a user personality by synthesizing information from past interactions. To mimic anthropomorphic behaviors and selectively preserve memory, MemoryBank incorporates a memory updating mechanism, inspired by the Ebbinghaus Forgetting Curve theory, which permits the AI to forget and reinforce memory based on time elapsed and the relative significance of the memory, thereby offering a human-like memory mechanism. MemoryBank is versatile in accommodating both closed-source models like ChatGPT and open-source models like ChatGLM. We exemplify application of MemoryBank through the creation of an LLM-based chatbot named SiliconFriend in a long-term AI Companion scenario. Further tuned with psychological dialogs, SiliconFriend displays heightened empathy in its interactions. Experiment involves both qualitative analysis with real-world user dialogs and quantitative analysis with simulated dialogs. In the latter, ChatGPT acts as users with diverse characteristics and generates long-term dialog contexts covering a wide array of topics. The results of our analysis reveal that SiliconFriend, equipped with MemoryBank, exhibits a strong capability for long-term companionship as it can provide emphatic response, recall relevant memories and understand user personality.