 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent-aligned Formal Specification Synthesis via Traceable Refinement
Apr 12, 2026Large language models are increasingly used to generate code from natural language, but ensuring correctness remains challenging. Formal verification offers a principled way to obtain such guarantees by proving that a program satisfies a formal specification. However, specifications are frequently missing in real-world codebases, and writing high-quality specifications remains expensive and expertise-intensive. We present VeriSpecGen, a traceable refinement framework that synthesizes intent-aligned specifications in Lean through requirement-level attribution and localized repair. VeriSpecGen decomposes natural language into atomic requirements and generates requirement-targeted tests with explicit traceability maps to validate generated specifications. When validation fails, traceability maps attribute failures to specific requirements, enabling targeted clause-level repairs. VeriSpecGen achieve 86.6% on VERINA SpecGen task using Claude Opus 4.5, improving over baselines by up to 31.8 points across different model families and scales. Beyond inference-time gains, we generate 343K training examples from VeriSpecGen refinement trajectories and demonstrate that training on these trajectories substantially improves specification synthesis by 62-106% relative and transfers gains to general reasoning abilities.
Learning to Triage Taint Flows Reported by Dynamic Program Analysis in Node.js Packages
Oct 23, 2025



Program analysis tools often produce large volumes of candidate vulnerability reports that require costly manual review, creating a practical challenge: how can security analysts prioritize the reports most likely to be true vulnerabilities? This paper investigates whether machine learning can be applied to prioritizing vulnerabilities reported by program analysis tools. We focus on Node.js packages and collect a benchmark of 1,883 Node.js packages, each containing one reported ACE or ACI vulnerability. We evaluate a variety of machine learning approaches, including classical models, graph neural networks (GNNs), large language models (LLMs), and hybrid models that combine GNN and LLMs, trained on data based on a dynamic program analysis tool's output. The top LLM achieves $F_{1} {=} 0.915$, while the best GNN and classical ML models reaching $F_{1} {=} 0.904$. At a less than 7% false-negative rate, the leading model eliminates 66.9% of benign packages from manual review, taking around 60 ms per package. If the best model is tuned to operate at a precision level of 0.8 (i.e., allowing 20% false positives amongst all warnings), our approach can detect 99.2% of exploitable taint flows while missing only 0.8%, demonstrating strong potential for real-world vulnerability triage.
Security Vulnerability Detection with Multitask Self-Instructed Fine-Tuning of Large Language Models
Jun 09, 2024
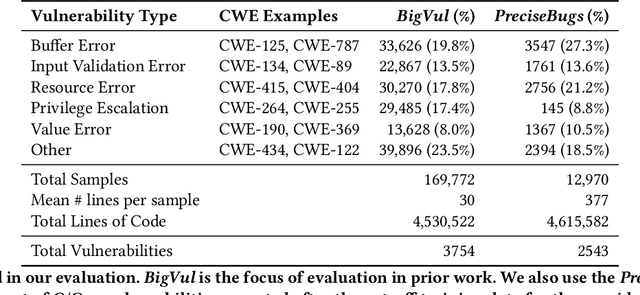
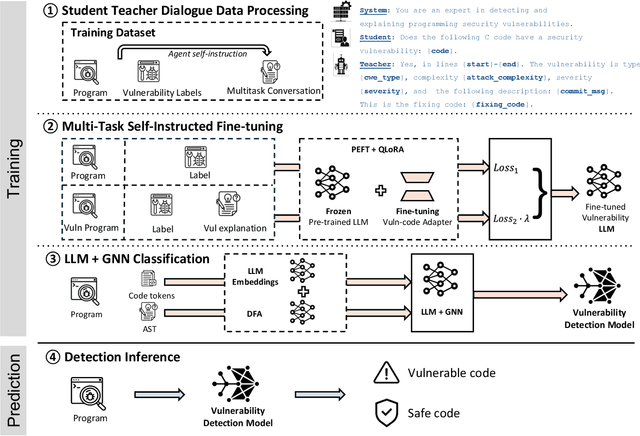
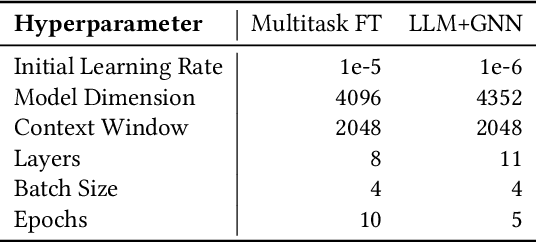
Software security vulnerabilities allow attackers to perform malicious activities to disrupt software operations. Recent Transformer-based language models have significantly advanced vulnerability detection, surpassing the capabilities of static analysis based deep learning models. However, language models trained solely on code tokens do not capture either the explanation of vulnerability type or the data flow structure information of code, both of which are crucial for vulnerability detection. We propose a novel technique that integrates a multitask sequence-to-sequence LLM with pro-gram control flow graphs encoded as a graph neural network to achieve sequence-to-classification vulnerability detection. We introduce MSIVD, multitask self-instructed fine-tuning for vulnerability detection, inspired by chain-of-thought prompting and LLM self-instruction. Our experiments demonstrate that MSIVD achieves superior performance, outperforming the highest LLM-based vulnerability detector baseline (LineVul), with a F1 score of 0.92 on the BigVul dataset, and 0.48 on the PreciseBugs dataset. By training LLMs and GNNs simultaneously using a combination of code and explanatory metrics of a vulnerable program, MSIVD represents a promising direction for advancing LLM-based vulnerability detection that generalizes to unseen data. Based on our findings, we further discuss the necessity for new labelled security vulnerability datasets, as recent LLMs have seen or memorized prior datasets' held-out evaluation data.
Large Language Models for Test-Free Fault Localization
Oct 03, 2023



Fault Localization (FL) aims to automatically localize buggy lines of code, a key first step in many manual and automatic debugging tasks. Previous FL techniques assume the provision of input tests, and often require extensive program analysis, program instrumentation, or data preprocessing. Prior work on deep learning for APR struggles to learn from small datasets and produces limited results on real-world programs. Inspired by the ability of large language models (LLMs) of code to adapt to new tasks based on very few examples, we investigate the applicability of LLMs to line level fault localization. Specifically, we propose to overcome the left-to-right nature of LLMs by fine-tuning a small set of bidirectional adapter layers on top of the representations learned by LLMs to produce LLMAO, the first language model based fault localization approach that locates buggy lines of code without any test coverage information. We fine-tune LLMs with 350 million, 6 billion, and 16 billion parameters on small, manually curated corpora of buggy programs such as the Defects4J corpus. We observe that our technique achieves substantially more confidence in fault localization when built on the larger models, with bug localization performance scaling consistently with the LLM size. Our empirical evaluation shows that LLMAO improves the Top-1 results over the state-of-the-art machine learning fault localization (MLFL) baselines by 2.3%-54.4%, and Top-5 results by 14.4%-35.6%. LLMAO is also the first FL technique trained using a language model architecture that can detect security vulnerabilities down to the code line level.