 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Safety For Code LLMs Via Retrieval-Augmented Revision
Mar 02, 2026Large Language Models (LLMs) are increasingly deployed for code generation in high-stakes software development, yet their limited transparency in security reasoning and brittleness to evolving vulnerability patterns raise critical trustworthiness concerns. Models trained on static datasets cannot readily adapt to newly discovered vulnerabilities or changing security standards without retraining, leading to the repeated generation of unsafe code. We present a principled approach to trustworthy code generation by design that operates as an inference-time safety mechanism. Our approach employs retrieval-augmented generation to surface relevant security risks in generated code and retrieve related security discussions from a curated Stack Overflow knowledge base, which are then used to guide an LLM during code revision. This design emphasizes three aspects relevant to trustworthiness: (1) interpretability, through transparent safety interventions grounded in expert community explanations; (2) robustness, by allowing adaptation to evolving security practices without model retraining; and (3) safety alignment, through real-time intervention before unsafe code reaches deployment. Across real-world and benchmark datasets, our approach improves the security of LLM-generated code compared to prompting alone, while introducing no new vulnerabilities as measured by static analysis. These results suggest that principled, retrieval-augmented inference-time interventions can serve as a complementary mechanism for improving the safety of LLM-based code generation, and highlight the ongoing value of community knowledge in supporting trustworthy AI deployment.
An Exploratory Study of ML Sketches and Visual Code Assistants
Dec 17, 2024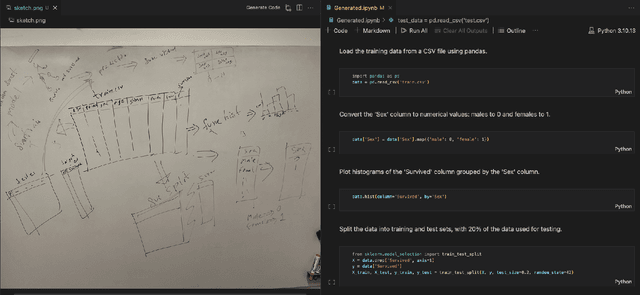

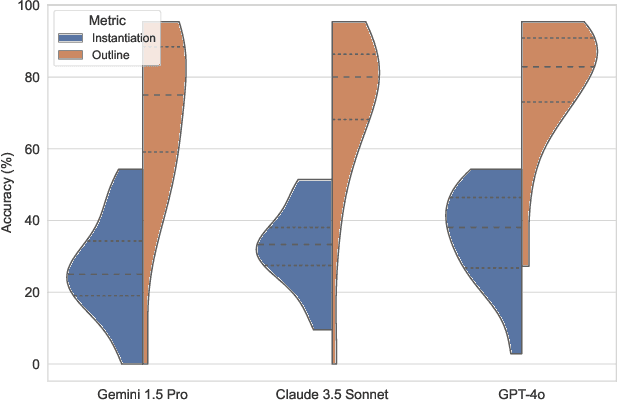
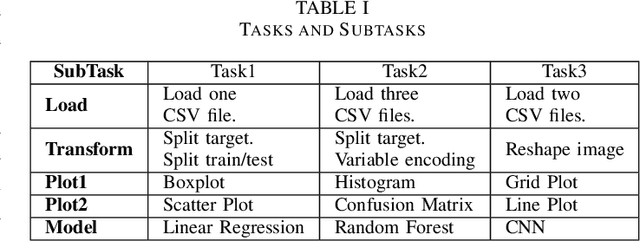
This paper explores the integration of Visual Code Assistants in Integrated Development Environments (IDEs). In Software Engineering, whiteboard sketching is often the initial step before coding, serving as a crucial collaboration tool for developers. Previous studies have investigated patterns in SE sketches and how they are used in practice, yet methods for directly using these sketches for code generation remain limited. The emergence of visually-equipped large language models presents an opportunity to bridge this gap, which is the focus of our research. In this paper, we built a first prototype of a Visual Code Assistant to get user feedback regarding in-IDE sketch-to-code tools. We conduct an experiment with 19 data scientists, most of whom regularly sketch as part of their job. We investigate developers' mental models by analyzing patterns commonly observed in their sketches when developing an ML workflow. Analysis indicates that diagrams were the preferred organizational component (52.6%), often accompanied by lists (42.1%) and numbered points (36.8%). Our tool converts their sketches into a Python notebook by querying an LLM. We use an LLM-as-judge setup to score the quality of the generated code, finding that even brief sketching can effectively generate useful code outlines. We also find a positive correlation between sketch time and the quality of the generated code. We conclude the study by conducting extensive interviews to assess the tool's usefulness, explore potential use cases, and understand developers' needs. As noted by participants, promising applications for these assistants include education, prototyping, and collaborative settings. Our findings signal promise for the next generation of Code Assistants to integrate visual information, both to improve code generation and to better leverage developers' existing sketching practices.
Learning Defect Prediction from Unrealistic Data
Nov 02, 2023Pretrained models of code, such as CodeBERT and CodeT5, have become popular choices for code understanding and generation tasks. Such models tend to be large and require commensurate volumes of training data, which are rarely available for downstream tasks. Instead, it has become popular to train models with far larger but less realistic datasets, such as functions with artificially injected bugs. Models trained on such data, however, tend to only perform well on similar data, while underperforming on real world programs. In this paper, we conjecture that this discrepancy stems from the presence of distracting samples that steer the model away from the real-world task distribution. To investigate this conjecture, we propose an approach for identifying the subsets of these large yet unrealistic datasets that are most similar to examples in real-world datasets based on their learned representations. Our approach extracts high-dimensional embeddings of both real-world and artificial programs using a neural model and scores artificial samples based on their distance to the nearest real-world sample. We show that training on only the nearest, representationally most similar samples while discarding samples that are not at all similar in representations yields consistent improvements across two popular pretrained models of code on two code understanding tasks. Our results are promising, in that they show that training models on a representative subset of an unrealistic dataset can help us harness the power of large-scale synthetic data generation while preserving downstream task performance. Finally, we highlight the limitations of applying AI models for predicting vulnerabilities and bugs in real-world applications
Large Language Models for Test-Free Fault Localization
Oct 03, 2023



Fault Localization (FL) aims to automatically localize buggy lines of code, a key first step in many manual and automatic debugging tasks. Previous FL techniques assume the provision of input tests, and often require extensive program analysis, program instrumentation, or data preprocessing. Prior work on deep learning for APR struggles to learn from small datasets and produces limited results on real-world programs. Inspired by the ability of large language models (LLMs) of code to adapt to new tasks based on very few examples, we investigate the applicability of LLMs to line level fault localization. Specifically, we propose to overcome the left-to-right nature of LLMs by fine-tuning a small set of bidirectional adapter layers on top of the representations learned by LLMs to produce LLMAO, the first language model based fault localization approach that locates buggy lines of code without any test coverage information. We fine-tune LLMs with 350 million, 6 billion, and 16 billion parameters on small, manually curated corpora of buggy programs such as the Defects4J corpus. We observe that our technique achieves substantially more confidence in fault localization when built on the larger models, with bug localization performance scaling consistently with the LLM size. Our empirical evaluation shows that LLMAO improves the Top-1 results over the state-of-the-art machine learning fault localization (MLFL) baselines by 2.3%-54.4%, and Top-5 results by 14.4%-35.6%. LLMAO is also the first FL technique trained using a language model architecture that can detect security vulnerabilities down to the code line level.
CAT-LM: Training Language Models on Aligned Code And Tests
Oct 02, 2023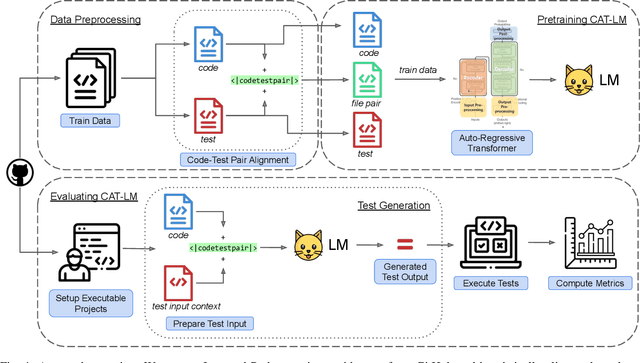

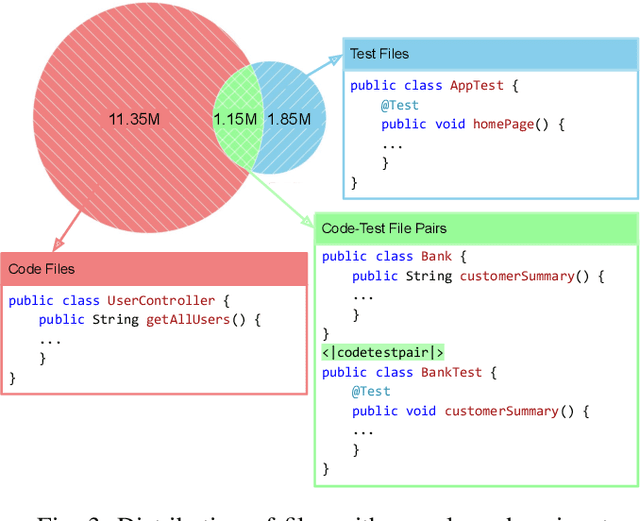
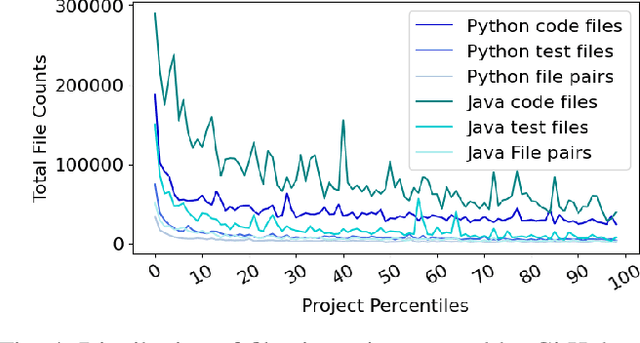
Testing is an integral part of the software development process. Yet, writing tests is time-consuming and therefore often neglected. Classical test generation tools such as EvoSuite generate behavioral test suites by optimizing for coverage, but tend to produce tests that are hard to understand. Language models trained on code can generate code that is highly similar to that written by humans, but current models are trained to generate each file separately, as is standard practice in natural language processing, and thus fail to consider the code-under-test context when producing a test file. In this work, we propose the Aligned Code And Tests Language Model (CAT-LM), a GPT-style language model with 2.7 Billion parameters, trained on a corpus of Python and Java projects. We utilize a novel pretraining signal that explicitly considers the mapping between code and test files when available. We also drastically increase the maximum sequence length of inputs to 8,192 tokens, 4x more than typical code generation models, to ensure that the code context is available to the model when generating test code. We analyze its usefulness for realistic applications, showing that sampling with filtering (e.g., by compilability, coverage) allows it to efficiently produce tests that achieve coverage similar to ones written by developers while resembling their writing style. By utilizing the code context, CAT-LM generates more valid tests than even much larger language models trained with more data (CodeGen 16B and StarCoder) and substantially outperforms a recent test-specific model (TeCo) at test completion. Overall, our work highlights the importance of incorporating software-specific insights when training language models for code and paves the way to more powerful automated test generation.
Stack Over-Flowing with Results: The Case for Domain-Specific Pre-Training Over One-Size-Fits-All Models
Jun 05, 2023Large pre-trained neural language models have brought immense progress to both NLP and software engineering. Models in OpenAI's GPT series now dwarf Google's BERT and Meta's RoBERTa, which previously set new benchmarks on a wide range of NLP applications. These models are trained on massive corpora of heterogeneous data from web crawls, which enables them to learn general language patterns and semantic relationships. However, the largest models are both expensive to train and deploy and are often closed-source, so we lack access to their data and design decisions. We argue that this trend towards large, general-purpose models should be complemented with single-purpose, more modestly sized pre-trained models. In this work, we take StackOverflow (SO) as a domain example in which large volumes of rich aligned code and text data is available. We adopt standard practices for pre-training large language models, including using a very large context size (2,048 tokens), batch size (0.5M tokens) and training set (27B tokens), coupled with a powerful toolkit (Megatron-LM), to train two models: SOBertBase, with 109M parameters, and SOBertLarge with 762M parameters, at a budget of just $\$187$ and $\$800$ each. We compare the performance of our models with both the previous SOTA model trained on SO data exclusively as well general-purpose BERT models and OpenAI's ChatGPT on four SO-specific downstream tasks - question quality prediction, closed question prediction, named entity recognition and obsoletion prediction (a new task we introduce). Not only do our models consistently outperform all baselines, the smaller model is often sufficient for strong results. Both models are released to the public. These results demonstrate that pre-training both extensively and properly on in-domain data can yield a powerful and affordable alternative to leveraging closed-source general-purpose models.
AI for Low-Code for AI
May 31, 2023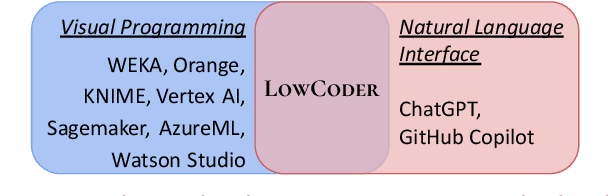


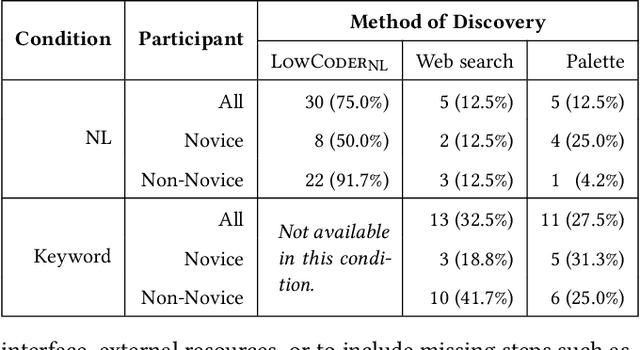
Low-code programming allows citizen developers to create programs with minimal coding effort, typically via visual (e.g. drag-and-drop) interfaces. In parallel, recent AI-powered tools such as Copilot and ChatGPT generate programs from natural language instructions. We argue that these modalities are complementary: tools like ChatGPT greatly reduce the need to memorize large APIs but still require their users to read (and modify) programs, whereas visual tools abstract away most or all programming but struggle to provide easy access to large APIs. At their intersection, we propose LowCoder, the first low-code tool for developing AI pipelines that supports both a visual programming interface (LowCoder_VP) and an AI-powered natural language interface (LowCoder_NL). We leverage this tool to provide some of the first insights into whether and how these two modalities help programmers by conducting a user study. We task 20 developers with varying levels of AI expertise with implementing four ML pipelines using LowCoder, replacing the LowCoder_NL component with a simple keyword search in half the tasks. Overall, we find that LowCoder is especially useful for (i) Discoverability: using LowCoder_NL, participants discovered new operators in 75% of the tasks, compared to just 32.5% and 27.5% using web search or scrolling through options respectively in the keyword-search condition, and (ii) Iterative Composition: 82.5% of tasks were successfully completed and many initial pipelines were further successfully improved. Qualitative analysis shows that AI helps users discover how to implement constructs when they know what to do, but still fails to support novices when they lack clarity on what they want to accomplish. Overall, our work highlights the benefits of combining the power of AI with low-code programming.
DiffusER: Discrete Diffusion via Edit-based Reconstruction
Oct 30, 2022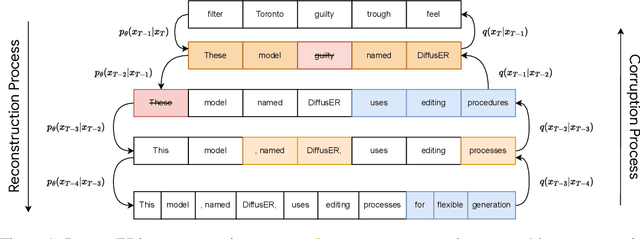

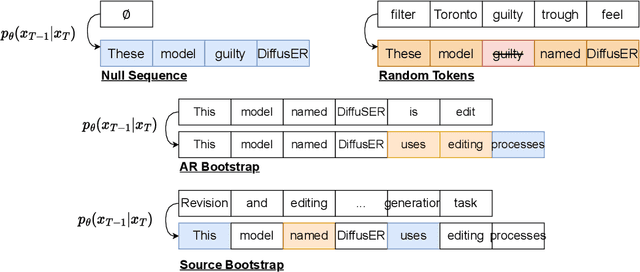
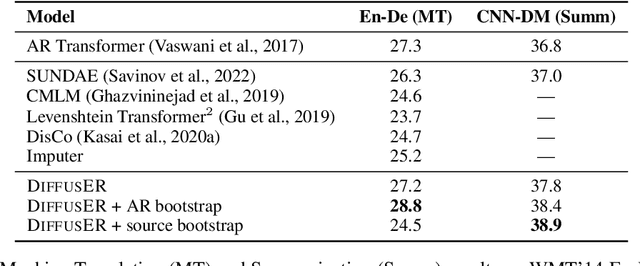
In text generation, models that generate text from scratch one token at a time are currently the dominant paradigm. Despite being performant, these models lack the ability to revise existing text, which limits their usability in many practical scenarios. We look to address this, with DiffusER (Diffusion via Edit-based Reconstruction), a new edit-based generative model for text based on denoising diffusion models -- a class of models that use a Markov chain of denoising steps to incrementally generate data. DiffusER is not only a strong generative model in general, rivalling autoregressive models on several tasks spanning machine translation, summarization, and style transfer; it can also perform other varieties of generation that standard autoregressive models are not well-suited for. For instance, we demonstrate that DiffusER makes it possible for a user to condition generation on a prototype, or an incomplete sequence, and continue revising based on previous edit steps.
A Systematic Evaluation of Large Language Models of Code
Mar 01, 2022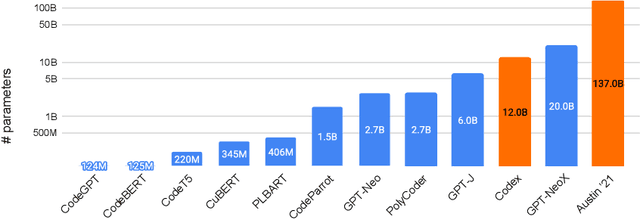
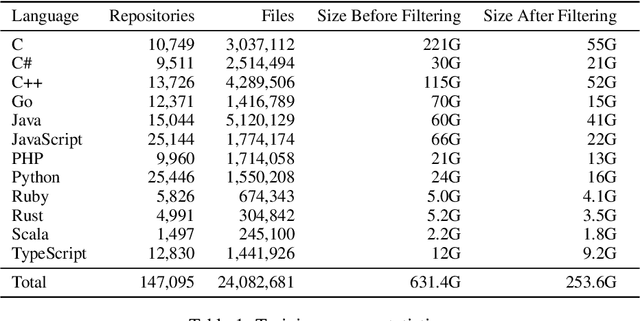

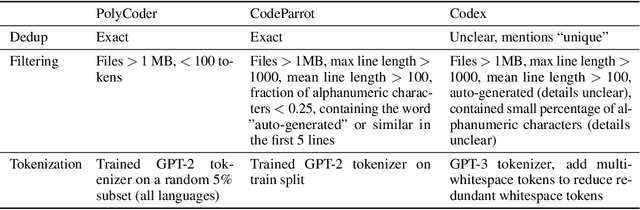
Large language models (LMs) of code have recently shown tremendous promise in completing code and synthesizing code from natural language descriptions. However, the current state-of-the-art code LMs (e.g., Codex (Chen et al., 2021)) are not publicly available, leaving many questions about their model and data design decisions. We aim to fill in some of these blanks through a systematic evaluation of the largest existing models: Codex, GPT-J, GPT-Neo, GPT-NeoX-20B, and CodeParrot, across various programming languages. Although Codex itself is not open-source, we find that existing open-source models do achieve close results in some programming languages, although targeted mainly for natural language modeling. We further identify an important missing piece in the form of a large open-source model trained exclusively on a multi-lingual corpus of code. We release a new model, PolyCoder, with 2.7B parameters based on the GPT-2 architecture, which was trained on 249GB of code across 12 programming languages on a single machine. In the C programming language, PolyCoder outperforms all models including Codex. Our trained models are open-source and publicly available at https://github.com/VHellendoorn/Code-LMs, which enables future research and application in this area.
Capturing Structural Locality in Non-parametric Language Models
Oct 06, 2021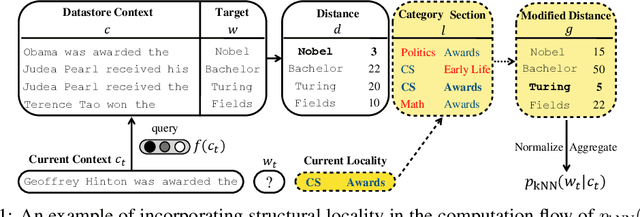

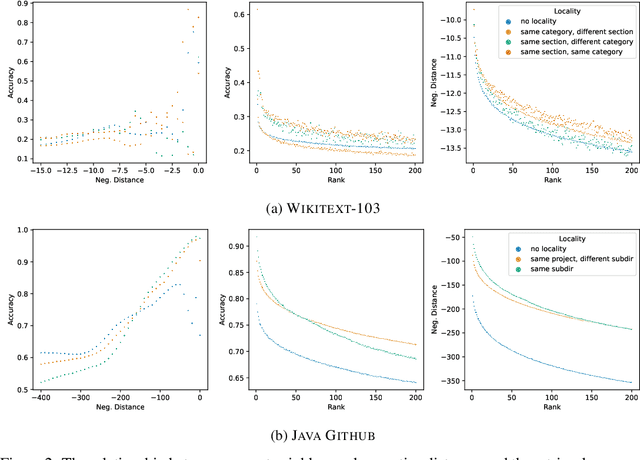
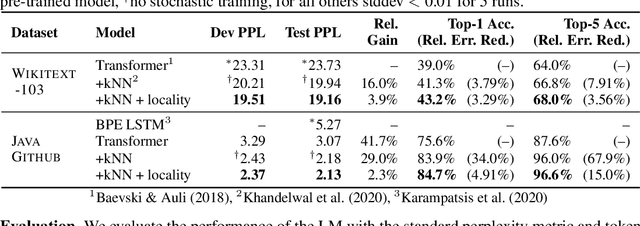
Structural locality is a ubiquitous feature of real-world datasets, wherein data points are organized into local hierarchies. Some examples include topical clusters in text or project hierarchies in source code repositories. In this paper, we explore utilizing this structural locality within non-parametric language models, which generate sequences that reference retrieved examples from an external source. We propose a simple yet effective approach for adding locality information into such models by adding learned parameters that improve the likelihood of retrieving examples from local neighborhoods. Experiments on two different domains, Java source code and Wikipedia text, demonstrate that locality features improve model efficacy over models without access to these features, with interesting differences. We also perform an analysis of how and where locality features contribute to improved performance and why the traditionally used contextual similarity metrics alone are not enough to grasp the locality structure.