 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating CAD Code with Vision-Language Models for 3D Designs
Oct 07, 2024



Generative AI has transformed the fields of Design and Manufacturing by providing efficient and automated methods for generating and modifying 3D objects. One approach involves using Large Language Models (LLMs) to generate Computer- Aided Design (CAD) scripting code, which can then be executed to render a 3D object; however, the resulting 3D object may not meet the specified requirements. Testing the correctness of CAD generated code is challenging due to the complexity and structure of 3D objects (e.g., shapes, surfaces, and dimensions) that are not feasible in code. In this paper, we introduce CADCodeVerify, a novel approach to iteratively verify and improve 3D objects generated from CAD code. Our approach works by producing ameliorative feedback by prompting a Vision-Language Model (VLM) to generate and answer a set of validation questions to verify the generated object and prompt the VLM to correct deviations. To evaluate CADCodeVerify, we introduce, CADPrompt, the first benchmark for CAD code generation, consisting of 200 natural language prompts paired with expert-annotated scripting code for 3D objects to benchmark progress. Our findings show that CADCodeVerify improves VLM performance by providing visual feedback, enhancing the structure of the 3D objects, and increasing the success rate of the compiled program. When applied to GPT-4, CADCodeVerify achieved a 7.30% reduction in Point Cloud distance and a 5.0% improvement in success rate compared to prior work
Language Models are Better Bug Detector Through Code-Pair Classification
Nov 14, 2023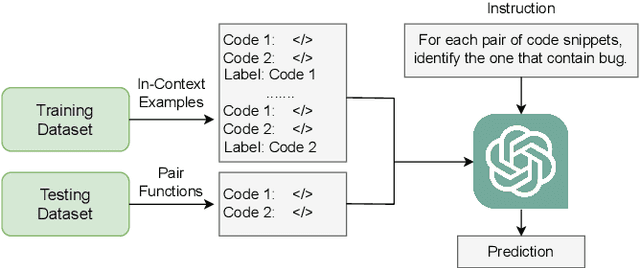
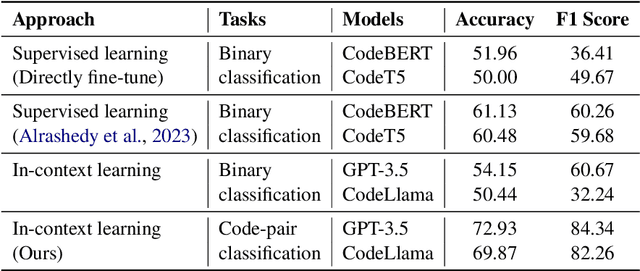
Large language models (LLMs) such as GPT-3.5 and CodeLlama are powerful models for code generation and understanding. Fine-tuning these models comes with a high computational cost and requires a large labeled dataset. Alternatively, in-context learning techniques allow models to learn downstream tasks with only a few examples. Recently, researchers have shown how in-context learning performs well in bug detection and repair. In this paper, we propose code-pair classification task in which both the buggy and non-buggy versions are given to the model, and the model identifies the buggy ones. We evaluate our task in real-world dataset of bug detection and two most powerful LLMs. Our experiments indicate that an LLM can often pick the buggy from the non-buggy version of the code, and the code-pair classification task is much easier compared to be given a snippet and deciding if and where a bug exists.
Learning Defect Prediction from Unrealistic Data
Nov 02, 2023Pretrained models of code, such as CodeBERT and CodeT5, have become popular choices for code understanding and generation tasks. Such models tend to be large and require commensurate volumes of training data, which are rarely available for downstream tasks. Instead, it has become popular to train models with far larger but less realistic datasets, such as functions with artificially injected bugs. Models trained on such data, however, tend to only perform well on similar data, while underperforming on real world programs. In this paper, we conjecture that this discrepancy stems from the presence of distracting samples that steer the model away from the real-world task distribution. To investigate this conjecture, we propose an approach for identifying the subsets of these large yet unrealistic datasets that are most similar to examples in real-world datasets based on their learned representations. Our approach extracts high-dimensional embeddings of both real-world and artificial programs using a neural model and scores artificial samples based on their distance to the nearest real-world sample. We show that training on only the nearest, representationally most similar samples while discarding samples that are not at all similar in representations yields consistent improvements across two popular pretrained models of code on two code understanding tasks. Our results are promising, in that they show that training models on a representative subset of an unrealistic dataset can help us harness the power of large-scale synthetic data generation while preserving downstream task performance. Finally, we highlight the limitations of applying AI models for predicting vulnerabilities and bugs in real-world applications