 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoRestTest: A Tool for Automated REST API Testing Using LLMs and MARL
Jan 15, 2025As REST APIs have become widespread in modern web services, comprehensive testing of these APIs has become increasingly crucial. Due to the vast search space consisting of operations, parameters, and parameter values along with their complex dependencies and constraints, current testing tools suffer from low code coverage, leading to suboptimal fault detection. To address this limitation, we present a novel tool, AutoRestTest, which integrates the Semantic Operation Dependency Graph (SODG) with Multi-Agent Reinforcement Learning (MARL) and large language models (LLMs) for effective REST API testing. AutoRestTest determines operation-dependent parameters using the SODG and employs five specialized agents (operation, parameter, value, dependency, and header) to identify dependencies of operations and generate operation sequences, parameter combinations, and values. AutoRestTest provides a command-line interface and continuous telemetry on successful operation count, unique server errors detected, and time elapsed. Upon completion, AutoRestTest generates a detailed report highlighting errors detected and operations exercised. In this paper, we introduce our tool and present preliminary results.
LlamaRestTest: Effective REST API Testing with Small Language Models
Jan 15, 2025
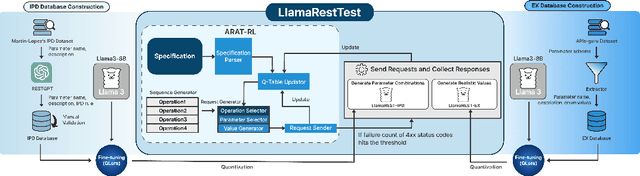
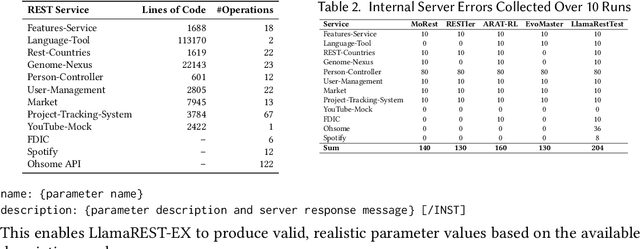
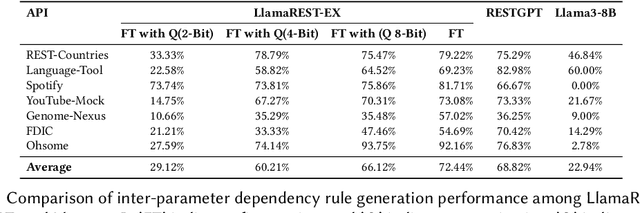
Modern web services rely heavily on REST APIs, typically documented using the OpenAPI specification. The widespread adoption of this standard has resulted in the development of many black-box testing tools that generate tests based on these specifications. Recent advancements in Natural Language Processing (NLP), particularly with Large Language Models (LLMs), have enhanced REST API testing by extracting actionable rules and generating input values from the human-readable portions of the specification. However, these advancements overlook the potential of continuously refining the identified rules and test inputs based on server responses. To address this limitation, we present LlamaRestTest, a novel approach that employs two custom LLMs to generate realistic test inputs and uncover parameter dependencies during the testing process by incorporating server responses. These LLMs are created by fine-tuning the Llama3-8b model, using mined datasets of REST API example values and inter-parameter dependencies. We evaluated LlamaRestTest on 12 real-world services (including popular services such as Spotify), comparing it against RESTGPT, a GPT-powered specification-enhancement tool, as well as several state-of-the-art REST API testing tools, including RESTler, MoRest, EvoMaster, and ARAT-RL. Our results show that fine-tuning enables smaller LLMs to outperform larger models in detecting actionable rules and generating inputs for REST API testing. We evaluated configurations from the base Llama3-8B to fine-tuned versions and explored 2-bit, 4-bit, and 8-bit quantization for efficiency. LlamaRestTest surpasses state-of-the-art tools in code coverage and error detection, even with RESTGPT-enhanced specifications, and an ablation study highlights the impact of its novel components.
A Multi-Agent Approach for REST API Testing with Semantic Graphs and LLM-Driven Inputs
Nov 11, 2024As modern web services increasingly rely on REST APIs, their thorough testing has become crucial. Furthermore, the advent of REST API specifications such as the OpenAPI Specification has led to the emergence of many black-box REST API testing tools. However, these tools often focus on individual test elements in isolation (e.g., APIs, parameters, values), resulting in lower coverage and less effectiveness in detecting faults (i.e., 500 response codes). To address these limitations, we present AutoRestTest, the first black-box framework to adopt a dependency-embedded multi-agent approach for REST API testing, integrating Multi-Agent Reinforcement Learning (MARL) with a Semantic Property Dependency Graph (SPDG) and Large Language Models (LLMs). Our approach treats REST API testing as a separable problem, where four agents -- API, dependency, parameter, and value -- collaborate to optimize API exploration. LLMs handle domain-specific value restrictions, the SPDG model simplifies the search space for dependencies using a similarity score between API operations, and MARL dynamically optimizes the agents' behavior. Evaluated on 12 real-world REST services, AutoRestTest outperforms the four leading black-box REST API testing tools, including those assisted by RESTGPT (which augments realistic test inputs using LLMs), in terms of code coverage, operation coverage, and fault detection. Notably, AutoRestTest is the only tool able to identify an internal server error in Spotify. Our ablation study underscores the significant contributions of the agent learning, SPDG, and LLM components.
Learning Defect Prediction from Unrealistic Data
Nov 02, 2023Pretrained models of code, such as CodeBERT and CodeT5, have become popular choices for code understanding and generation tasks. Such models tend to be large and require commensurate volumes of training data, which are rarely available for downstream tasks. Instead, it has become popular to train models with far larger but less realistic datasets, such as functions with artificially injected bugs. Models trained on such data, however, tend to only perform well on similar data, while underperforming on real world programs. In this paper, we conjecture that this discrepancy stems from the presence of distracting samples that steer the model away from the real-world task distribution. To investigate this conjecture, we propose an approach for identifying the subsets of these large yet unrealistic datasets that are most similar to examples in real-world datasets based on their learned representations. Our approach extracts high-dimensional embeddings of both real-world and artificial programs using a neural model and scores artificial samples based on their distance to the nearest real-world sample. We show that training on only the nearest, representationally most similar samples while discarding samples that are not at all similar in representations yields consistent improvements across two popular pretrained models of code on two code understanding tasks. Our results are promising, in that they show that training models on a representative subset of an unrealistic dataset can help us harness the power of large-scale synthetic data generation while preserving downstream task performance. Finally, we highlight the limitations of applying AI models for predicting vulnerabilities and bugs in real-world applications
Robustness of Neural Networks: A Probabilistic and Practical Approach
Feb 15, 2019Neural networks are becoming increasingly prevalent in software, and it is therefore important to be able to verify their behavior. Because verifying the correctness of neural networks is extremely challenging, it is common to focus on the verification of other properties of these systems. One important property, in particular, is robustness. Most existing definitions of robustness, however, focus on the worst-case scenario where the inputs are adversarial. Such notions of robustness are too strong, and unlikely to be satisfied by-and verifiable for-practical neural networks. Observing that real-world inputs to neural networks are drawn from non-adversarial probability distributions, we propose a novel notion of robustness: probabilistic robustness, which requires the neural network to be robust with at least $(1 - \epsilon)$ probability with respect to the input distribution. This probabilistic approach is practical and provides a principled way of estimating the robustness of a neural network. We also present an algorithm, based on abstract interpretation and importance sampling, for checking whether a neural network is probabilistically robust. Our algorithm uses abstract interpretation to approximate the behavior of a neural network and compute an overapproximation of the input regions that violate robustness. It then uses importance sampling to counter the effect of such overapproximation and compute an accurate estimate of the probability that the neural network violates the robustness property.