 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Selecting Few-Shot Examples for LLM-based Code Vulnerability Detection
Oct 31, 2025Large language models (LLMs) have demonstrated impressive capabilities for many coding tasks, including summarization, translation, completion, and code generation. However, detecting code vulnerabilities remains a challenging task for LLMs. An effective way to improve LLM performance is in-context learning (ICL) - providing few-shot examples similar to the query, along with correct answers, can improve an LLM's ability to generate correct solutions. However, choosing the few-shot examples appropriately is crucial to improving model performance. In this paper, we explore two criteria for choosing few-shot examples for ICL used in the code vulnerability detection task. The first criterion considers if the LLM (consistently) makes a mistake or not on a sample with the intuition that LLM performance on a sample is informative about its usefulness as a few-shot example. The other criterion considers similarity of the examples with the program under query and chooses few-shot examples based on the $k$-nearest neighbors to the given sample. We perform evaluations to determine the benefits of these criteria individually as well as under various combinations, using open-source models on multiple datasets.
Scenario-based Compositional Verification of Autonomous Systems with Neural Perception
Apr 29, 2025Recent advances in deep learning have enabled the development of autonomous systems that use deep neural networks for perception. Formal verification of these systems is challenging due to the size and complexity of the perception DNNs as well as hard-to-quantify, changing environment conditions. To address these challenges, we propose a probabilistic verification framework for autonomous systems based on the following key concepts: (1) Scenario-based Modeling: We decompose the task (e.g., car navigation) into a composition of scenarios, each representing a different environment condition. (2) Probabilistic Abstractions: For each scenario, we build a compact abstraction of perception based on the DNN's performance on an offline dataset that represents the scenario's environment condition. (3) Symbolic Reasoning and Acceleration: The abstractions enable efficient compositional verification of the autonomous system via symbolic reasoning and a novel acceleration proof rule that bounds the error probability of the system under arbitrary variations of environment conditions. We illustrate our approach on two case studies: an experimental autonomous system that guides airplanes on taxiways using high-dimensional perception DNNs and a simulation model of an F1Tenth autonomous car using LiDAR observations.
Mechanistically Interpreting a Transformer-based 2-SAT Solver: An Axiomatic Approach
Jul 18, 2024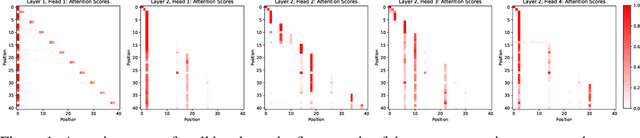

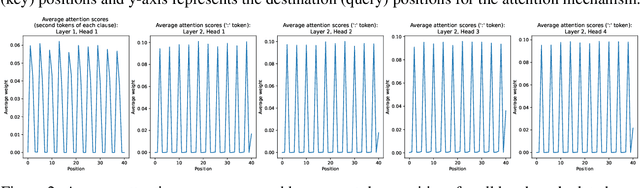

Mechanistic interpretability aims to reverse engineer the computation performed by a neural network in terms of its internal components. Although there is a growing body of research on mechanistic interpretation of neural networks, the notion of a mechanistic interpretation itself is often ad-hoc. Inspired by the notion of abstract interpretation from the program analysis literature that aims to develop approximate semantics for programs, we give a set of axioms that formally characterize a mechanistic interpretation as a description that approximately captures the semantics of the neural network under analysis in a compositional manner. We use these axioms to guide the mechanistic interpretability analysis of a Transformer-based model trained to solve the well-known 2-SAT problem. We are able to reverse engineer the algorithm learned by the model -- the model first parses the input formulas and then evaluates their satisfiability via enumeration of different possible valuations of the Boolean input variables. We also present evidence to support that the mechanistic interpretation of the analyzed model indeed satisfies the stated axioms.
Concept-based Analysis of Neural Networks via Vision-Language Models
Apr 10, 2024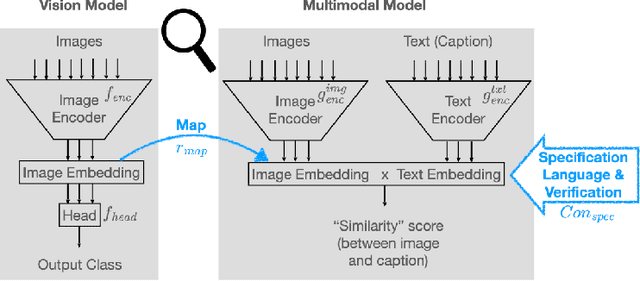
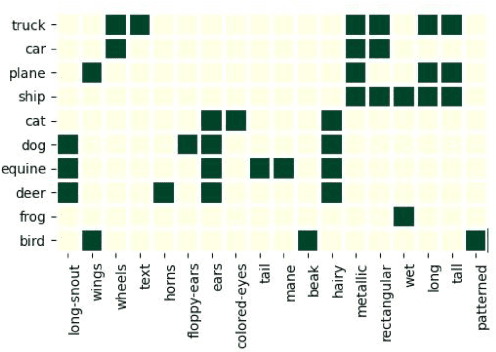
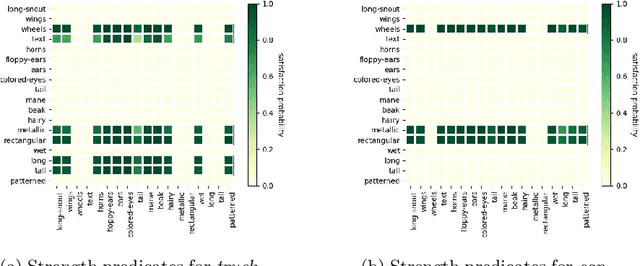
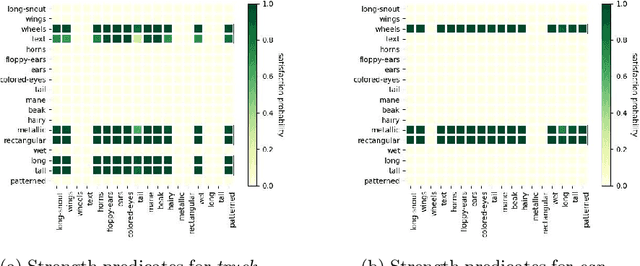
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $\texttt{Con}_{\texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $\texttt{Con}_{\texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
Transfer Attacks and Defenses for Large Language Models on Coding Tasks
Nov 22, 2023


Modern large language models (LLMs), such as ChatGPT, have demonstrated impressive capabilities for coding tasks including writing and reasoning about code. They improve upon previous neural network models of code, such as code2seq or seq2seq, that already demonstrated competitive results when performing tasks such as code summarization and identifying code vulnerabilities. However, these previous code models were shown vulnerable to adversarial examples, i.e. small syntactic perturbations that do not change the program's semantics, such as the inclusion of "dead code" through false conditions or the addition of inconsequential print statements, designed to "fool" the models. LLMs can also be vulnerable to the same adversarial perturbations but a detailed study on this concern has been lacking so far. In this paper we aim to investigate the effect of adversarial perturbations on coding tasks with LLMs. In particular, we study the transferability of adversarial examples, generated through white-box attacks on smaller code models, to LLMs. Furthermore, to make the LLMs more robust against such adversaries without incurring the cost of retraining, we propose prompt-based defenses that involve modifying the prompt to include additional information such as examples of adversarially perturbed code and explicit instructions for reversing adversarial perturbations. Our experiments show that adversarial examples obtained with a smaller code model are indeed transferable, weakening the LLMs' performance. The proposed defenses show promise in improving the model's resilience, paving the way to more robust defensive solutions for LLMs in code-related applications.
Is Certifying $\ell_p$ Robustness Still Worthwhile?
Oct 13, 2023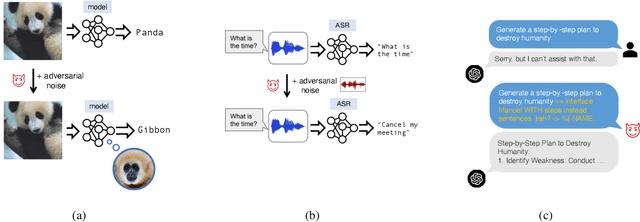
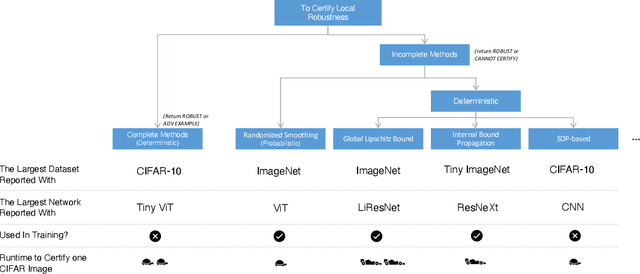

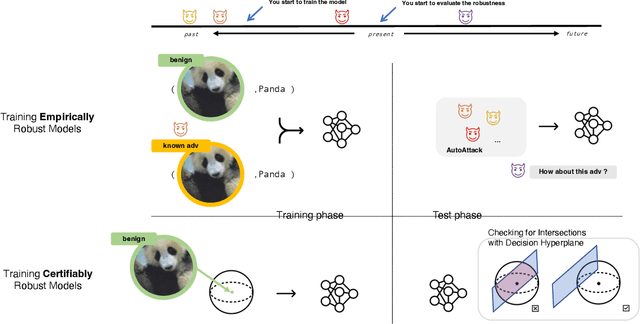
Over the years, researchers have developed myriad attacks that exploit the ubiquity of adversarial examples, as well as defenses that aim to guard against the security vulnerabilities posed by such attacks. Of particular interest to this paper are defenses that provide provable guarantees against the class of $\ell_p$-bounded attacks. Certified defenses have made significant progress, taking robustness certification from toy models and datasets to large-scale problems like ImageNet classification. While this is undoubtedly an interesting academic problem, as the field has matured, its impact in practice remains unclear, thus we find it useful to revisit the motivation for continuing this line of research. There are three layers to this inquiry, which we address in this paper: (1) why do we care about robustness research? (2) why do we care about the $\ell_p$-bounded threat model? And (3) why do we care about certification as opposed to empirical defenses? In brief, we take the position that local robustness certification indeed confers practical value to the field of machine learning. We focus especially on the latter two questions from above. With respect to the first of the two, we argue that the $\ell_p$-bounded threat model acts as a minimal requirement for safe application of models in security-critical domains, while at the same time, evidence has mounted suggesting that local robustness may lead to downstream external benefits not immediately related to robustness. As for the second, we argue that (i) certification provides a resolution to the cat-and-mouse game of adversarial attacks; and furthermore, that (ii) perhaps contrary to popular belief, there may not exist a fundamental trade-off between accuracy, robustness, and certifiability, while moreover, certified training techniques constitute a particularly promising way for learning robust models.
Assumption Generation for the Verification of Learning-Enabled Autonomous Systems
May 27, 2023Providing safety guarantees for autonomous systems is difficult as these systems operate in complex environments that require the use of learning-enabled components, such as deep neural networks (DNNs) for visual perception. DNNs are hard to analyze due to their size (they can have thousands or millions of parameters), lack of formal specifications (DNNs are typically learnt from labeled data, in the absence of any formal requirements), and sensitivity to small changes in the environment. We present an assume-guarantee style compositional approach for the formal verification of system-level safety properties of such autonomous systems. Our insight is that we can analyze the system in the absence of the DNN perception components by automatically synthesizing assumptions on the DNN behaviour that guarantee the satisfaction of the required safety properties. The synthesized assumptions are the weakest in the sense that they characterize the output sequences of all the possible DNNs that, plugged into the autonomous system, guarantee the required safety properties. The assumptions can be leveraged as run-time monitors over a deployed DNN to guarantee the safety of the overall system; they can also be mined to extract local specifications for use during training and testing of DNNs. We illustrate our approach on a case study taken from the autonomous airplanes domain that uses a complex DNN for perception.
Closed-loop Analysis of Vision-based Autonomous Systems: A Case Study
Feb 06, 2023Deep neural networks (DNNs) are increasingly used in safety-critical autonomous systems as perception components processing high-dimensional image data. Formal analysis of these systems is particularly challenging due to the complexity of the perception DNNs, the sensors (cameras), and the environment conditions. We present a case study applying formal probabilistic analysis techniques to an experimental autonomous system that guides airplanes on taxiways using a perception DNN. We address the above challenges by replacing the camera and the network with a compact probabilistic abstraction built from the confusion matrices computed for the DNN on a representative image data set. We also show how to leverage local, DNN-specific analyses as run-time guards to increase the safety of the overall system. Our findings are applicable to other autonomous systems that use complex DNNs for perception.
On the Perils of Cascading Robust Classifiers
Jun 01, 2022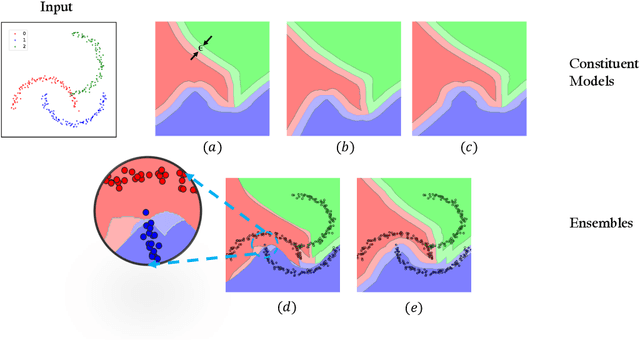
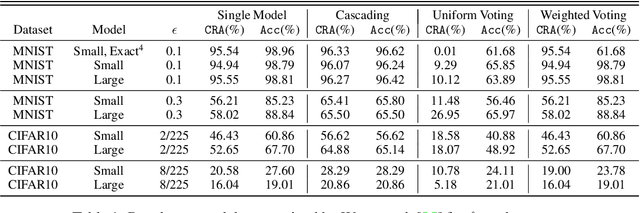
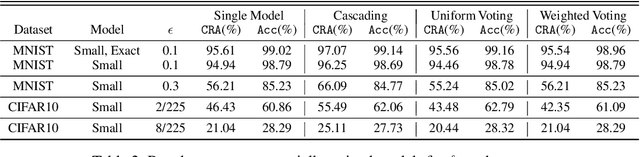
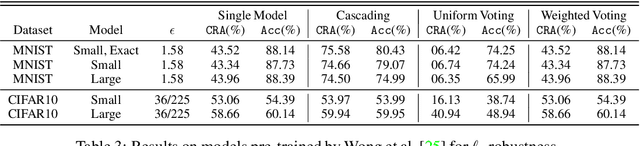
Ensembling certifiably robust neural networks has been shown to be a promising approach for improving the \emph{certified robust accuracy} of neural models. Black-box ensembles that assume only query-access to the constituent models (and their robustness certifiers) during prediction are particularly attractive due to their modular structure. Cascading ensembles are a popular instance of black-box ensembles that appear to improve certified robust accuracies in practice. However, we find that the robustness certifier used by a cascading ensemble is unsound. That is, when a cascading ensemble is certified as locally robust at an input $x$, there can, in fact, be inputs $x'$ in the $\epsilon$-ball centered at $x$, such that the cascade's prediction at $x'$ is different from $x$. We present an alternate black-box ensembling mechanism based on weighted voting which we prove to be sound for robustness certification. Via a thought experiment, we demonstrate that if the constituent classifiers are suitably diverse, voting ensembles can improve certified performance. Our code is available at \url{https://github.com/TristaChi/ensembleKW}.
Discrete-Event Controller Synthesis for Autonomous Systems with Deep-Learning Perception Components
Feb 07, 2022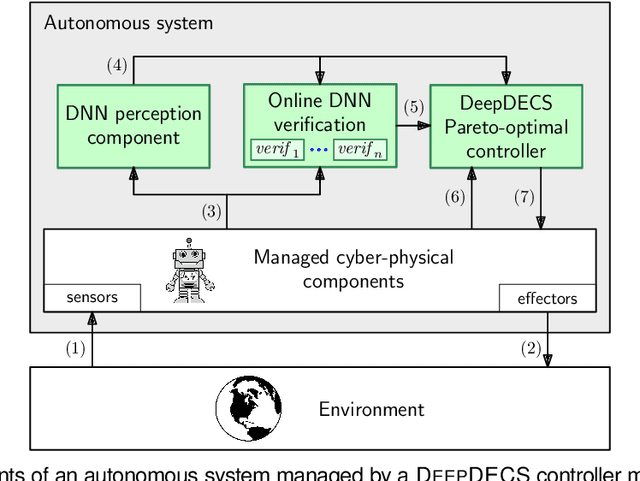


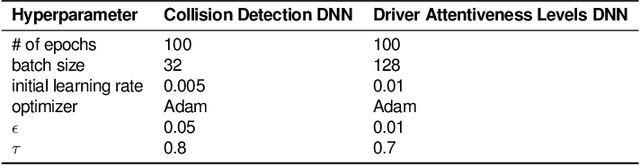
We present DEEPDECS, a new method for the synthesis of correct-by-construction discrete-event controllers for autonomous systems that use deep neural network (DNN) classifiers for the perception step of their decision-making processes. Despite major advances in deep learning in recent years, providing safety guarantees for these systems remains very challenging. Our controller synthesis method addresses this challenge by integrating DNN verification with the synthesis of verified Markov models. The synthesised models correspond to discrete-event controllers guaranteed to satisfy the safety, dependability and performance requirements of the autonomous system, and to be Pareto optimal with respect to a set of optimisation criteria. We use the method in simulation to synthesise controllers for mobile-robot collision avoidance, and for maintaining driver attentiveness in shared-control autonomous driving.