 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-based Analysis of Neural Networks via Vision-Language Models
Apr 10, 2024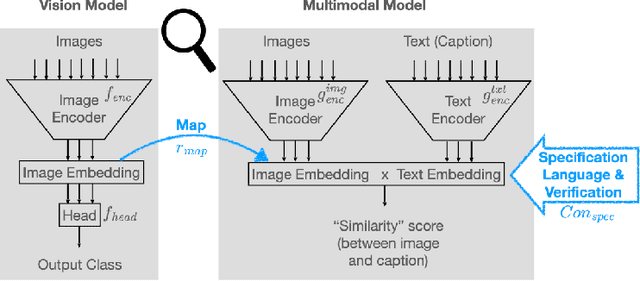
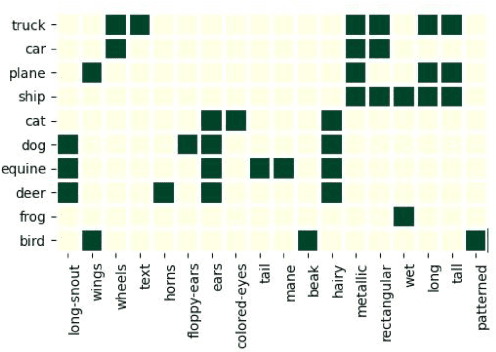
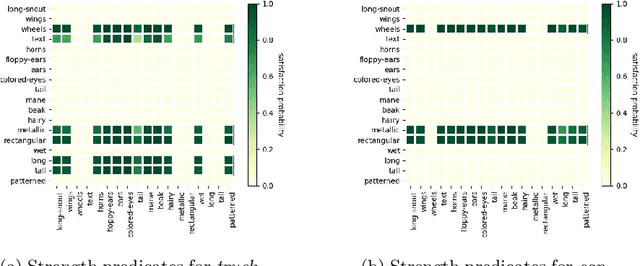
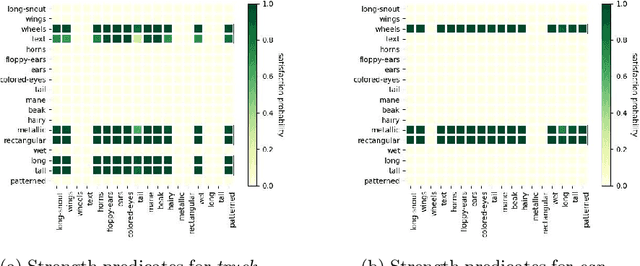
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $\texttt{Con}_{\texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $\texttt{Con}_{\texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
Assessing Visually-Continuous Corruption Robustness of Neural Networks Relative to Human Performance
Feb 29, 2024

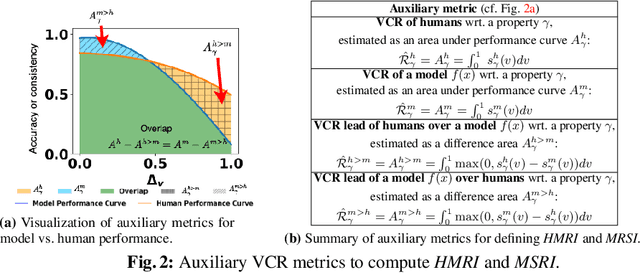
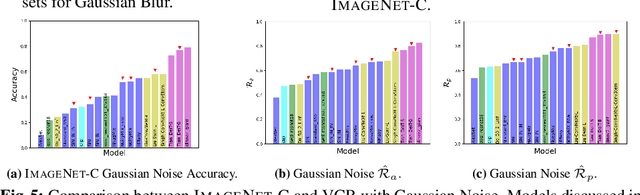
While Neural Networks (NNs) have surpassed human accuracy in image classification on ImageNet, they often lack robustness against image corruption, i.e., corruption robustness. Yet such robustness is seemingly effortless for human perception. In this paper, we propose visually-continuous corruption robustness (VCR) -- an extension of corruption robustness to allow assessing it over the wide and continuous range of changes that correspond to the human perceptive quality (i.e., from the original image to the full distortion of all perceived visual information), along with two novel human-aware metrics for NN evaluation. To compare VCR of NNs with human perception, we conducted extensive experiments on 14 commonly used image corruptions with 7,718 human participants and state-of-the-art robust NN models with different training objectives (e.g., standard, adversarial, corruption robustness), different architectures (e.g., convolution NNs, vision transformers), and different amounts of training data augmentation. Our study showed that: 1) assessing robustness against continuous corruption can reveal insufficient robustness undetected by existing benchmarks; as a result, 2) the gap between NN and human robustness is larger than previously known; and finally, 3) some image corruptions have a similar impact on human perception, offering opportunities for more cost-effective robustness assessments. Our validation set with 14 image corruptions, human robustness data, and the evaluation code is provided as a toolbox and a benchmark.
If a Human Can See It, So Should Your System: Reliability Requirements for Machine Vision Components
Feb 08, 2022
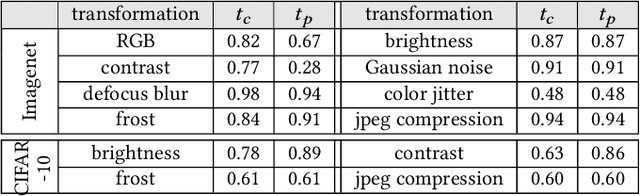
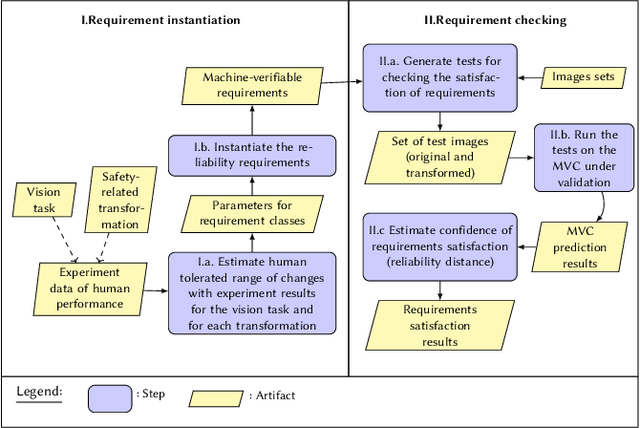
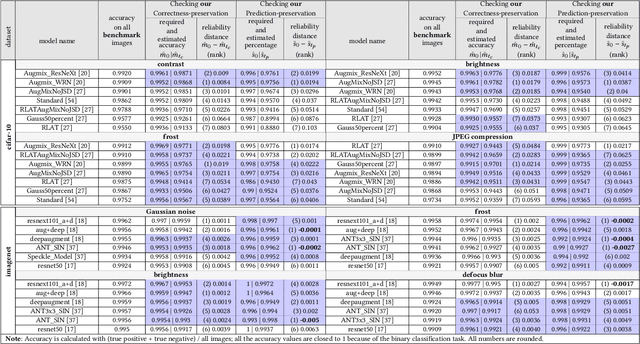
Machine Vision Components (MVC) are becoming safety-critical. Assuring their quality, including safety, is essential for their successful deployment. Assurance relies on the availability of precisely specified and, ideally, machine-verifiable requirements. MVCs with state-of-the-art performance rely on machine learning (ML) and training data but largely lack such requirements. In this paper, we address the need for defining machine-verifiable reliability requirements for MVCs against transformations that simulate the full range of realistic and safety-critical changes in the environment. Using human performance as a baseline, we define reliability requirements as: 'if the changes in an image do not affect a human's decision, neither should they affect the MVC's.' To this end, we provide: (1) a class of safety-related image transformations; (2) reliability requirement classes to specify correctness-preservation and prediction-preservation for MVCs; (3) a method to instantiate machine-verifiable requirements from these requirements classes using human performance experiment data; (4) human performance experiment data for image recognition involving eight commonly used transformations, from about 2000 human participants; and (5) a method for automatically checking whether an MVC satisfies our requirements. Further, we show that our reliability requirements are feasible and reusable by evaluating our methods on 13 state-of-the-art pre-trained image classification models. Finally, we demonstrate that our approach detects reliability gaps in MVCs that other existing methods are unable to detect.