 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Invariants Are Equal: Curating Training Data to Accelerate Program Verification with SLMs
Mar 16, 2026The synthesis of inductive loop invariants is a critical bottleneck in automated program verification. While Large Language Models (LLMs) show promise in mitigating this issue, they often fail on hard instances, generating invariants that are invalid or computationally ineffective. While fine-tuning is a natural route to mitigate this limitation, obtaining high-quality training data for invariant generation remains an open challenge. We present a rigorous data curation pipeline designed to extract high-quality training signals from raw verifier-generated invariants. First, we formalize the properties required for a high-quality training invariant. Second, we propose Wonda, a pipeline that refines noisy data via AST-based normalization, followed by LLM-driven semantic rewriting and augmentation with provable quality guarantees. We demonstrate that fine-tuning Small Language Models (SLMs) on this curated dataset result in consistent and significant performance gain. In particular, a fine-tuned 4B parameter model matches the utility of a GPT-OSS-120B baseline and approaches the state-of-the-art GPT-5.2, without incurring reasoning-time overhead. On challenging instances from the recent InvBench evaluation suite, our approach doubles the invariant correctness and speedup rates of base models; and improves their Virtual Best Performance (VBP) rates on the verification task by up to 14.2%.
SpotIt+: Verification-based Text-to-SQL Evaluation with Database Constraints
Mar 04, 2026We present SpotIt+, an open-source tool for evaluating Text-to-SQL systems via bounded equivalence verification. Given a generated SQL query and the ground truth, SpotIt+ actively searches for database instances that differentiate the two queries. To ensure that the generated counterexamples reflect practically relevant discrepancies, we introduce a constraint-mining pipeline that combines rule-based specification mining over example databases with LLM-based validation. Experimental results on the BIRD dataset show that the mined constraints enable SpotIt+ to generate more realistic differentiating databases, while preserving its ability to efficiently uncover numerous discrepancies between generated and gold SQL queries that are missed by standard test-based evaluation.
HoneyBee: Efficient Role-based Access Control for Vector Databases via Dynamic Partitioning
May 02, 2025



As vector databases gain traction in enterprise applications, robust access control has become critical to safeguard sensitive data. Access control in these systems is often implemented through hybrid vector queries, which combine nearest neighbor search on vector data with relational predicates based on user permissions. However, existing approaches face significant trade-offs: creating dedicated indexes for each user minimizes query latency but introduces excessive storage redundancy, while building a single index and applying access control after vector search reduces storage overhead but suffers from poor recall and increased query latency. This paper introduces HoneyBee, a dynamic partitioning framework that bridges the gap between these approaches by leveraging the structure of Role-Based Access Control (RBAC) policies. RBAC, widely adopted in enterprise settings, groups users into roles and assigns permissions to those roles, creating a natural "thin waist" in the permission structure that is ideal for partitioning decisions. Specifically, HoneyBee produces overlapping partitions where vectors can be strategically replicated across different partitions to reduce query latency while controlling storage overhead. By introducing analytical models for the performance and recall of the vector search, HoneyBee formulates the partitioning strategy as a constrained optimization problem to dynamically balance storage, query efficiency, and recall. Evaluations on RBAC workloads demonstrate that HoneyBee reduces storage redundancy compared to role partitioning and achieves up to 6x faster query speeds than row-level security (RLS) with only 1.4x storage increase, offering a practical middle ground for secure and efficient vector search.
Lucy: Think and Reason to Solve Text-to-SQL
Jul 06, 2024



Large Language Models (LLMs) have made significant progress in assisting users to query databases in natural language. While LLM-based techniques provide state-of-the-art results on many standard benchmarks, their performance significantly drops when applied to large enterprise databases. The reason is that these databases have a large number of tables with complex relationships that are challenging for LLMs to reason about. We analyze challenges that LLMs face in these settings and propose a new solution that combines the power of LLMs in understanding questions with automated reasoning techniques to handle complex database constraints. Based on these ideas, we have developed a new framework that outperforms state-of-the-art techniques in zero-shot text-to-SQL on complex benchmarks
Concept-based Analysis of Neural Networks via Vision-Language Models
Apr 10, 2024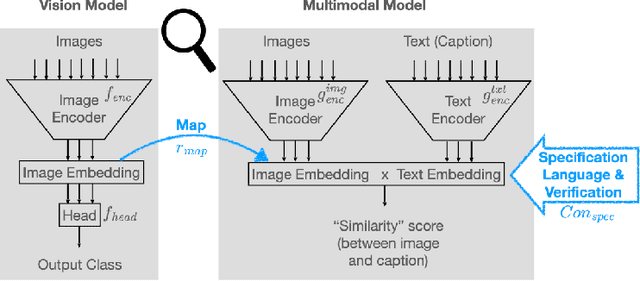
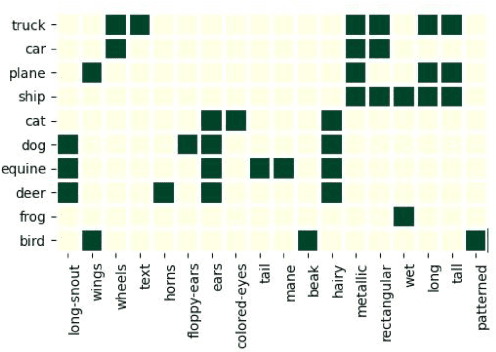
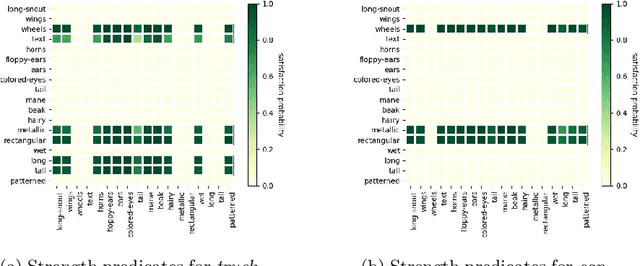
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $\texttt{Con}_{\texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $\texttt{Con}_{\texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
Lemur: Integrating Large Language Models in Automated Program Verification
Oct 10, 2023



The demonstrated code-understanding capability of LLMs raises the question of whether they can be used for automated program verification, a task that often demands high-level abstract reasoning about program properties, which is challenging for verification tools. We propose a general methodology to combine the power of LLMs and automated reasoners for automated program verification. We formally describe this methodology as a set of derivation rules and prove its soundness. We instantiate the calculus as a sound automated verification procedure, which led to practical improvements on a set of synthetic and competition benchmarks.
CrystalBox: Future-Based Explanations for DRL Network Controllers
Feb 27, 2023Lack of explainability is a key factor limiting the practical adoption of high-performant Deep Reinforcement Learning (DRL) controllers. Explainable RL for networking hitherto used salient input features to interpret a controller's behavior. However, these feature-based solutions do not completely explain the controller's decision-making process. Often, operators are interested in understanding the impact of a controller's actions on performance in the future, which feature-based solutions cannot capture. In this paper, we present CrystalBox, a framework that explains a controller's behavior in terms of the future impact on key network performance metrics. CrystalBox employs a novel learning-based approach to generate succinct and expressive explanations. We use reward components of the DRL network controller, which are key performance metrics meaningful to operators, as the basis for explanations. CrystalBox is generalizable and can work across both discrete and continuous control environments without any changes to the controller or the DRL workflow. Using adaptive bitrate streaming and congestion control, we demonstrate CrytalBox's ability to generate high-fidelity future-based explanations. We additionally present three practical use cases of CrystalBox: cross-state explainability, guided reward design, and network observability.
Prioritized Trace Selection: Towards High-Performance DRL-based Network Controllers
Feb 24, 2023



Deep Reinforcement Learning (DRL) based controllers offer high performance in a variety of network environments. However, simulator-based training of DRL controllers using highly skewed datasets of real-world traces often results in poor performance in the wild. In this paper, we put forward a generalizable solution for training high-performance DRL controllers in simulators -- Prioritized Trace Selection (PTS). PTS employs an automated three-stage process. First, we identify critical features that determine trace behavior. Second, we classify the traces into clusters. Finally, we dynamically identify and prioritize the salient clusters during training. PTS does not require any changes to the DRL workflow. It can work across both on-policy and off-policy DRL algorithms. We use Adaptive Bit Rate selection and Congestion Control as representative applications to show that PTS offers better performance in simulation and real-world, across multiple controllers and DRL algorithms. Our novel ABR controller, Gelato, trained with PTS outperforms state-of-the-art controllers on the real-world live-streaming platform, Puffer, reducing stalls by 59% and significantly improving average video quality.
On Computing Probabilistic Abductive Explanations
Dec 12, 2022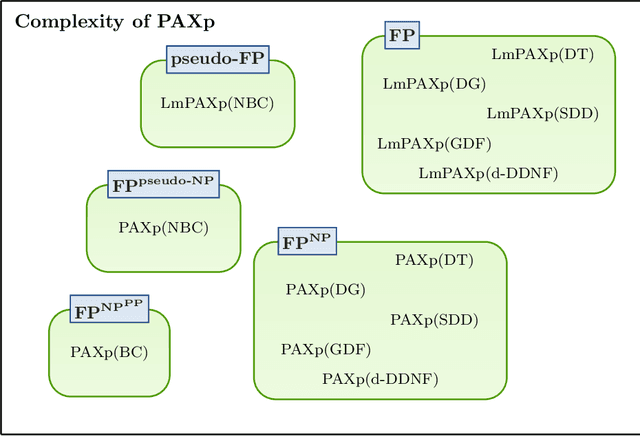

The most widely studied explainable AI (XAI) approaches are unsound. This is the case with well-known model-agnostic explanation approaches, and it is also the case with approaches based on saliency maps. One solution is to consider intrinsic interpretability, which does not exhibit the drawback of unsoundness. Unfortunately, intrinsic interpretability can display unwieldy explanation redundancy. Formal explainability represents the alternative to these non-rigorous approaches, with one example being PI-explanations. Unfortunately, PI-explanations also exhibit important drawbacks, the most visible of which is arguably their size. Recently, it has been observed that the (absolute) rigor of PI-explanations can be traded off for a smaller explanation size, by computing the so-called relevant sets. Given some positive {\delta}, a set S of features is {\delta}-relevant if, when the features in S are fixed, the probability of getting the target class exceeds {\delta}. However, even for very simple classifiers, the complexity of computing relevant sets of features is prohibitive, with the decision problem being NPPP-complete for circuit-based classifiers. In contrast with earlier negative results, this paper investigates practical approaches for computing relevant sets for a number of widely used classifiers that include Decision Trees (DTs), Naive Bayes Classifiers (NBCs), and several families of classifiers obtained from propositional languages. Moreover, the paper shows that, in practice, and for these families of classifiers, relevant sets are easy to compute. Furthermore, the experiments confirm that succinct sets of relevant features can be obtained for the families of classifiers considered.
Eliminating The Impossible, Whatever Remains Must Be True
Jun 20, 2022
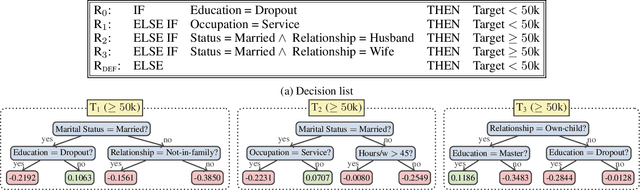

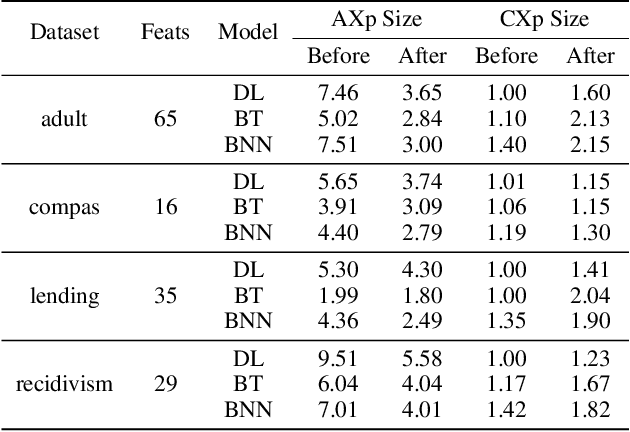
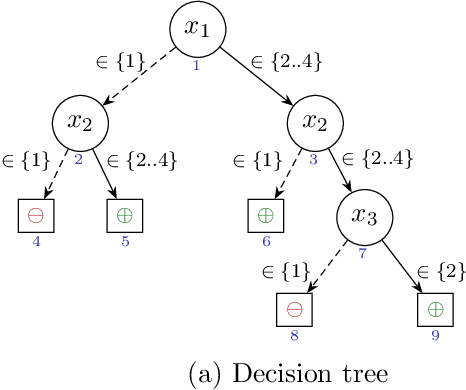
The rise of AI methods to make predictions and decisions has led to a pressing need for more explainable artificial intelligence (XAI) methods. One common approach for XAI is to produce a post-hoc explanation, explaining why a black box ML model made a certain prediction. Formal approaches to post-hoc explanations provide succinct reasons for why a prediction was made, as well as why not another prediction was made. But these approaches assume that features are independent and uniformly distributed. While this means that "why" explanations are correct, they may be longer than required. It also means the "why not" explanations may be suspect as the counterexamples they rely on may not be meaningful. In this paper, we show how one can apply background knowledge to give more succinct "why" formal explanations, that are presumably easier to interpret by humans, and give more accurate "why not" explanations. Furthermore, we also show how to use existing rule induction techniques to efficiently extract background information from a dataset, and also how to report which background information was used to make an explanation, allowing a human to examine it if they doubt the correctness of the explanation.