 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRigorous Explanations for Tree Ensembles
Mar 31, 2026Tree ensembles (TEs) find a multitude of practical applications. They represent one of the most general and accurate classes of machine learning methods. While they are typically quite concise in representation, their operation remains inscrutable to human decision makers. One solution to build trust in the operation of TEs is to automatically identify explanations for the predictions made. Evidently, we can only achieve trust using explanations, if those explanations are rigorous, that is truly reflect properties of the underlying predictor they explain This paper investigates the computation of rigorously-defined, logically-sound explanations for the concrete case of two well-known examples of tree ensembles, namely random forests and boosted trees.
Most General Explanations of Tree Ensembles
May 19, 2025Explainable Artificial Intelligence (XAI) is critical for attaining trust in the operation of AI systems. A key question of an AI system is ``why was this decision made this way''. Formal approaches to XAI use a formal model of the AI system to identify abductive explanations. While abductive explanations may be applicable to a large number of inputs sharing the same concrete values, more general explanations may be preferred for numeric inputs. So-called inflated abductive explanations give intervals for each feature ensuring that any input whose values fall withing these intervals is still guaranteed to make the same prediction. Inflated explanations cover a larger portion of the input space, and hence are deemed more general explanations. But there can be many (inflated) abductive explanations for an instance. Which is the best? In this paper, we show how to find a most general abductive explanation for an AI decision. This explanation covers as much of the input space as possible, while still being a correct formal explanation of the model's behaviour. Given that we only want to give a human one explanation for a decision, the most general explanation gives us the explanation with the broadest applicability, and hence the one most likely to seem sensible. (The paper has been accepted at IJCAI2025 conference.)
Efficient Contrastive Explanations on Demand
Dec 24, 2024Recent work revealed a tight connection between adversarial robustness and restricted forms of symbolic explanations, namely distance-based (formal) explanations. This connection is significant because it represents a first step towards making the computation of symbolic explanations as efficient as deciding the existence of adversarial examples, especially for highly complex machine learning (ML) models. However, a major performance bottleneck remains, because of the very large number of features that ML models may possess, in particular for deep neural networks. This paper proposes novel algorithms to compute the so-called contrastive explanations for ML models with a large number of features, by leveraging on adversarial robustness. Furthermore, the paper also proposes novel algorithms for listing explanations and finding smallest contrastive explanations. The experimental results demonstrate the performance gains achieved by the novel algorithms proposed in this paper.
Distance-Restricted Explanations: Theoretical Underpinnings & Efficient Implementation
May 14, 2024



The uses of machine learning (ML) have snowballed in recent years. In many cases, ML models are highly complex, and their operation is beyond the understanding of human decision-makers. Nevertheless, some uses of ML models involve high-stakes and safety-critical applications. Explainable artificial intelligence (XAI) aims to help human decision-makers in understanding the operation of such complex ML models, thus eliciting trust in their operation. Unfortunately, the majority of past XAI work is based on informal approaches, that offer no guarantees of rigor. Unsurprisingly, there exists comprehensive experimental and theoretical evidence confirming that informal methods of XAI can provide human-decision makers with erroneous information. Logic-based XAI represents a rigorous approach to explainability; it is model-based and offers the strongest guarantees of rigor of computed explanations. However, a well-known drawback of logic-based XAI is the complexity of logic reasoning, especially for highly complex ML models. Recent work proposed distance-restricted explanations, i.e. explanations that are rigorous provided the distance to a given input is small enough. Distance-restricted explainability is tightly related with adversarial robustness, and it has been shown to scale for moderately complex ML models, but the number of inputs still represents a key limiting factor. This paper investigates novel algorithms for scaling up the performance of logic-based explainers when computing and enumerating ML model explanations with a large number of inputs.
Locally-Minimal Probabilistic Explanations
Dec 20, 2023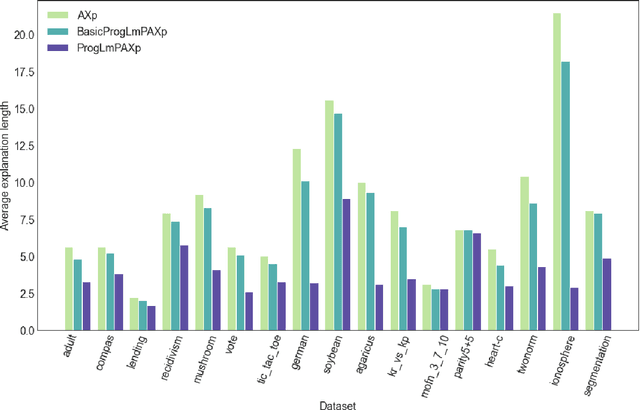

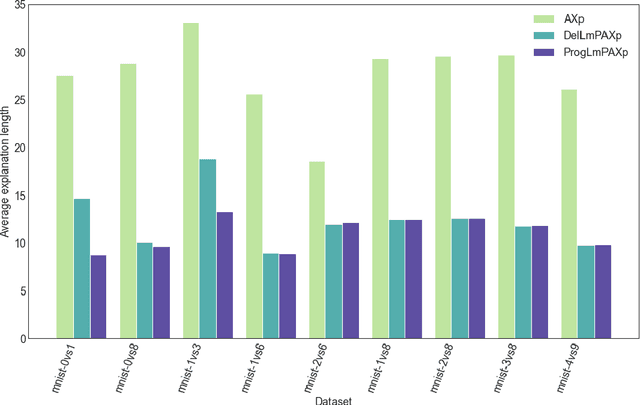
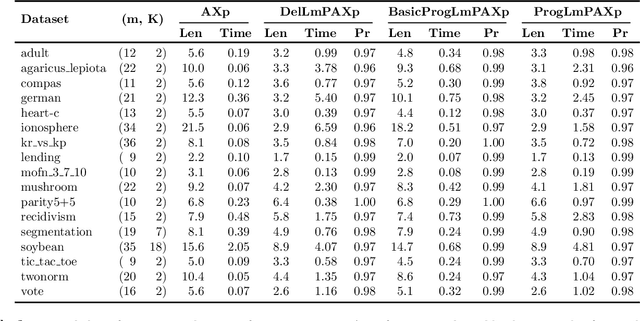
Formal abductive explanations offer crucial guarantees of rigor and so are of interest in high-stakes uses of machine learning (ML). One drawback of abductive explanations is explanation size, justified by the cognitive limits of human decision-makers. Probabilistic abductive explanations (PAXps) address this limitation, but their theoretical and practical complexity makes their exact computation most often unrealistic. This paper proposes novel efficient algorithms for the computation of locally-minimal PXAps, which offer high-quality approximations of PXAps in practice. The experimental results demonstrate the practical efficiency of the proposed algorithms.
The Pros and Cons of Adversarial Robustness
Dec 18, 2023
Robustness is widely regarded as a fundamental problem in the analysis of machine learning (ML) models. Most often robustness equates with deciding the non-existence of adversarial examples, where adversarial examples denote situations where small changes on some inputs cause a change in the prediction. The perceived importance of ML model robustness explains the continued progress observed for most of the last decade. Whereas robustness is often assessed locally, i.e. given some target point in feature space, robustness can also be defined globally, i.e. where any point in feature space can be considered. The importance of ML model robustness is illustrated for example by the existence of competitions evaluating the progress of robustness tools, namely in the case of neural networks (NNs) but also by efforts towards robustness certification. More recently, robustness tools have also been used for computing rigorous explanations of ML models. In contrast with the observed successes of robustness, this paper uncovers some limitations with existing definitions of robustness, both global and local, but also with efforts towards robustness certification. The paper also investigates uses of adversarial examples besides those related with robustness.
Axiomatic Aggregations of Abductive Explanations
Oct 12, 2023
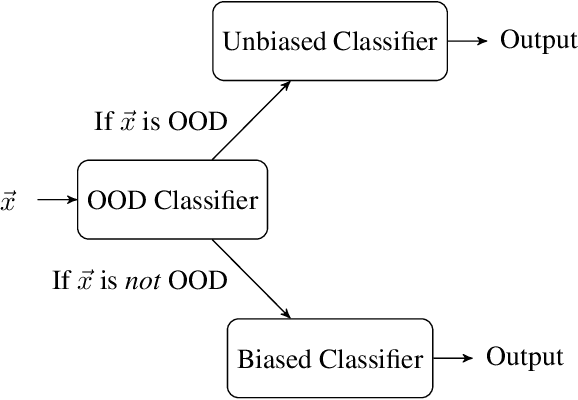
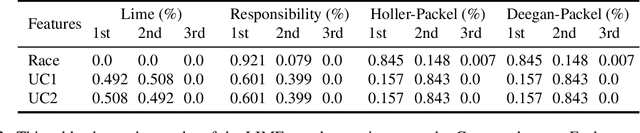

The recent criticisms of the robustness of post hoc model approximation explanation methods (like LIME and SHAP) have led to the rise of model-precise abductive explanations. For each data point, abductive explanations provide a minimal subset of features that are sufficient to generate the outcome. While theoretically sound and rigorous, abductive explanations suffer from a major issue -- there can be several valid abductive explanations for the same data point. In such cases, providing a single abductive explanation can be insufficient; on the other hand, providing all valid abductive explanations can be incomprehensible due to their size. In this work, we solve this issue by aggregating the many possible abductive explanations into feature importance scores. We propose three aggregation methods: two based on power indices from cooperative game theory and a third based on a well-known measure of causal strength. We characterize these three methods axiomatically, showing that each of them uniquely satisfies a set of desirable properties. We also evaluate them on multiple datasets and show that these explanations are robust to the attacks that fool SHAP and LIME.
Delivering Inflated Explanations
Jun 27, 2023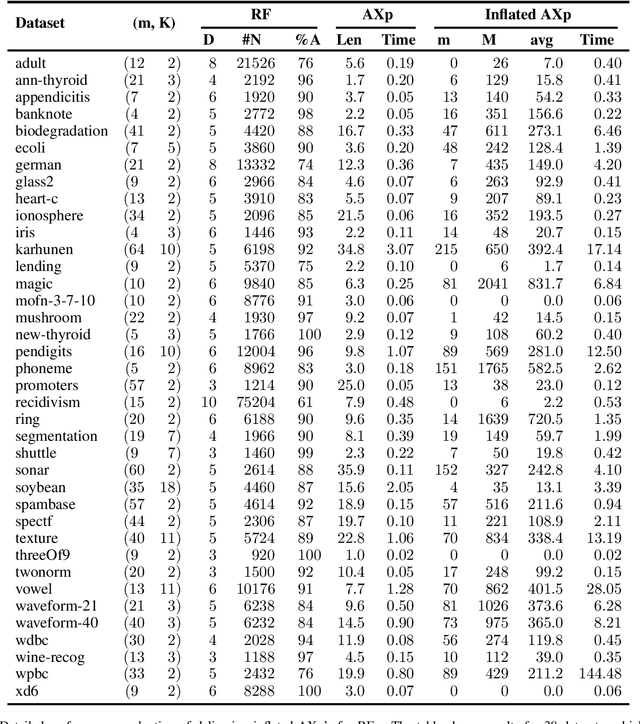
In the quest for Explainable Artificial Intelligence (XAI) one of the questions that frequently arises given a decision made by an AI system is, ``why was the decision made in this way?'' Formal approaches to explainability build a formal model of the AI system and use this to reason about the properties of the system. Given a set of feature values for an instance to be explained, and a resulting decision, a formal abductive explanation is a set of features, such that if they take the given value will always lead to the same decision. This explanation is useful, it shows that only some features were used in making the final decision. But it is narrow, it only shows that if the selected features take their given values the decision is unchanged. It's possible that some features may change values and still lead to the same decision. In this paper we formally define inflated explanations which is a set of features, and for each feature of set of values (always including the value of the instance being explained), such that the decision will remain unchanged. Inflated explanations are more informative than abductive explanations since e.g they allow us to see if the exact value of a feature is important, or it could be any nearby value. Overall they allow us to better understand the role of each feature in the decision. We show that we can compute inflated explanations for not that much greater cost than abductive explanations, and that we can extend duality results for abductive explanations also to inflated explanations.
On Computing Probabilistic Abductive Explanations
Dec 12, 2022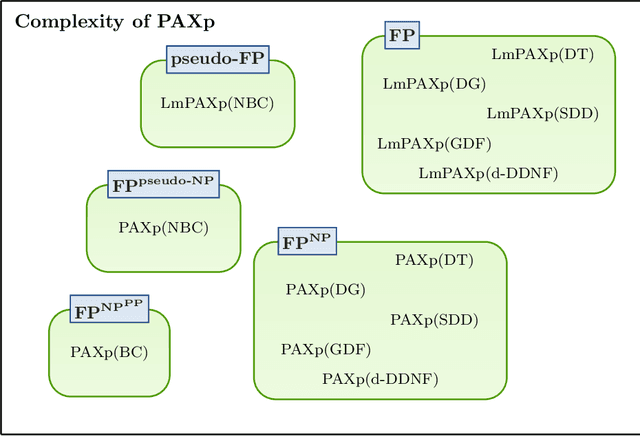

The most widely studied explainable AI (XAI) approaches are unsound. This is the case with well-known model-agnostic explanation approaches, and it is also the case with approaches based on saliency maps. One solution is to consider intrinsic interpretability, which does not exhibit the drawback of unsoundness. Unfortunately, intrinsic interpretability can display unwieldy explanation redundancy. Formal explainability represents the alternative to these non-rigorous approaches, with one example being PI-explanations. Unfortunately, PI-explanations also exhibit important drawbacks, the most visible of which is arguably their size. Recently, it has been observed that the (absolute) rigor of PI-explanations can be traded off for a smaller explanation size, by computing the so-called relevant sets. Given some positive {\delta}, a set S of features is {\delta}-relevant if, when the features in S are fixed, the probability of getting the target class exceeds {\delta}. However, even for very simple classifiers, the complexity of computing relevant sets of features is prohibitive, with the decision problem being NPPP-complete for circuit-based classifiers. In contrast with earlier negative results, this paper investigates practical approaches for computing relevant sets for a number of widely used classifiers that include Decision Trees (DTs), Naive Bayes Classifiers (NBCs), and several families of classifiers obtained from propositional languages. Moreover, the paper shows that, in practice, and for these families of classifiers, relevant sets are easy to compute. Furthermore, the experiments confirm that succinct sets of relevant features can be obtained for the families of classifiers considered.
On Computing Relevant Features for Explaining NBCs
Jul 11, 2022

Despite the progress observed with model-agnostic explainable AI (XAI), it is the case that model-agnostic XAI can produce incorrect explanations. One alternative are the so-called formal approaches to XAI, that include PI-explanations. Unfortunately, PI-explanations also exhibit important drawbacks, the most visible of which is arguably their size. The computation of relevant features serves to trade off probabilistic precision for the number of features in an explanation. However, even for very simple classifiers, the complexity of computing sets of relevant features is prohibitive. This paper investigates the computation of relevant sets for Naive Bayes Classifiers (NBCs), and shows that, in practice, these are easy to compute. Furthermore, the experiments confirm that succinct sets of relevant features can be obtained with NBCs.