 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Multi-Agent Bandits with Parsimonious Hints
Feb 22, 2025



We study a hinted heterogeneous multi-agent multi-armed bandits problem (HMA2B), where agents can query low-cost observations (hints) in addition to pulling arms. In this framework, each of the $M$ agents has a unique reward distribution over $K$ arms, and in $T$ rounds, they can observe the reward of the arm they pull only if no other agent pulls that arm. The goal is to maximize the total utility by querying the minimal necessary hints without pulling arms, achieving time-independent regret. We study HMA2B in both centralized and decentralized setups. Our main centralized algorithm, GP-HCLA, which is an extension of HCLA, uses a central decision-maker for arm-pulling and hint queries, achieving $O(M^4K)$ regret with $O(MK\log T)$ adaptive hints. In decentralized setups, we propose two algorithms, HD-ETC and EBHD-ETC, that allow agents to choose actions independently through collision-based communication and query hints uniformly until stopping, yielding $O(M^3K^2)$ regret with $O(M^3K\log T)$ hints, where the former requires knowledge of the minimum gap and the latter does not. Finally, we establish lower bounds to prove the optimality of our results and verify them through numerical simulations.
Fair and Welfare-Efficient Constrained Multi-matchings under Uncertainty
Nov 04, 2024



We study fair allocation of constrained resources, where a market designer optimizes overall welfare while maintaining group fairness. In many large-scale settings, utilities are not known in advance, but are instead observed after realizing the allocation. We therefore estimate agent utilities using machine learning. Optimizing over estimates requires trading-off between mean utilities and their predictive variances. We discuss these trade-offs under two paradigms for preference modeling -- in the stochastic optimization regime, the market designer has access to a probability distribution over utilities, and in the robust optimization regime they have access to an uncertainty set containing the true utilities with high probability. We discuss utilitarian and egalitarian welfare objectives, and we explore how to optimize for them under stochastic and robust paradigms. We demonstrate the efficacy of our approaches on three publicly available conference reviewer assignment datasets. The approaches presented enable scalable constrained resource allocation under uncertainty for many combinations of objectives and preference models.
RankSHAP: a Gold Standard Feature Attribution Method for the Ranking Task
May 03, 2024Several works propose various post-hoc, model-agnostic explanations for the task of ranking, i.e. the task of ordering a set of documents, via feature attribution methods. However, these attributions are seen to weakly correlate and sometimes contradict each other. In classification/regression, several works focus on \emph{axiomatic characterization} of feature attribution methods, showing that a certain method uniquely satisfies a set of desirable properties. However, no such efforts have been taken in the space of feature attributions for the task of ranking. We take an axiomatic game-theoretic approach, popular in the feature attribution community, to identify candidate attribution methods for ranking tasks. We first define desirable axioms: Rank-Efficiency, Rank-Missingness, Rank-Symmetry and Rank-Monotonicity, all variants of the classical Shapley axioms. Next, we introduce Rank-SHAP, a feature attribution algorithm for the general ranking task, which is an extension to classical Shapley values. We identify a polynomial-time algorithm for computing approximate Rank-SHAP values and evaluate the computational efficiency and accuracy of our algorithm under various scenarios. We also evaluate its alignment with human intuition with a user study. Lastly, we theoretically examine popular rank attribution algorithms, EXS and Rank-LIME, and evaluate their capacity to satisfy the classical Shapley axioms.
Percentile Criterion Optimization in Offline Reinforcement Learning
Apr 07, 2024



In reinforcement learning, robust policies for high-stakes decision-making problems with limited data are usually computed by optimizing the \emph{percentile criterion}. The percentile criterion is approximately solved by constructing an \emph{ambiguity set} that contains the true model with high probability and optimizing the policy for the worst model in the set. Since the percentile criterion is non-convex, constructing ambiguity sets is often challenging. Existing work uses \emph{Bayesian credible regions} as ambiguity sets, but they are often unnecessarily large and result in learning overly conservative policies. To overcome these shortcomings, we propose a novel Value-at-Risk based dynamic programming algorithm to optimize the percentile criterion without explicitly constructing any ambiguity sets. Our theoretical and empirical results show that our algorithm implicitly constructs much smaller ambiguity sets and learns less conservative robust policies.
Axiomatic Aggregations of Abductive Explanations
Oct 12, 2023
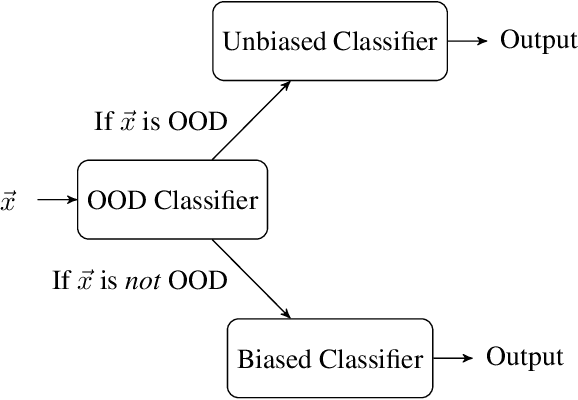
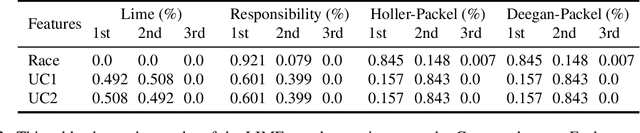

The recent criticisms of the robustness of post hoc model approximation explanation methods (like LIME and SHAP) have led to the rise of model-precise abductive explanations. For each data point, abductive explanations provide a minimal subset of features that are sufficient to generate the outcome. While theoretically sound and rigorous, abductive explanations suffer from a major issue -- there can be several valid abductive explanations for the same data point. In such cases, providing a single abductive explanation can be insufficient; on the other hand, providing all valid abductive explanations can be incomprehensible due to their size. In this work, we solve this issue by aggregating the many possible abductive explanations into feature importance scores. We propose three aggregation methods: two based on power indices from cooperative game theory and a third based on a well-known measure of causal strength. We characterize these three methods axiomatically, showing that each of them uniquely satisfies a set of desirable properties. We also evaluate them on multiple datasets and show that these explanations are robust to the attacks that fool SHAP and LIME.
Towards an AI Accountability Policy
Jul 25, 2023


This white paper is a response to the "AI Accountability Policy Request for Comments" by the National Telecommunications and Information Administration of the United States. The question numbers for which comments were requested are provided in superscripts at the end of key sentences answering the respective questions. The white paper offers a set of interconnected recommendations for an AI accountability policy.
Simple Steps to Success: Axiomatics of Distance-Based Algorithmic Recourse
Jun 27, 2023



We propose a novel data-driven framework for algorithmic recourse that offers users interventions to change their predicted outcome. Existing approaches to compute recourse find a set of points that satisfy some desiderata -- e.g. an intervention in the underlying causal graph, or minimizing a cost function. Satisfying these criteria, however, requires extensive knowledge of the underlying model structure, often an unrealistic amount of information in several domains. We propose a data-driven, computationally efficient approach to computing algorithmic recourse. We do so by suggesting directions in the data manifold that users can take to change their predicted outcome. We present Stepwise Explainable Paths (StEP), an axiomatically justified framework to compute direction-based algorithmic recourse. We offer a thorough empirical and theoretical investigation of StEP. StEP offers provable privacy and robustness guarantees, and outperforms the state-of-the-art on several established recourse desiderata.
Weighted Notions of Fairness with Binary Supermodular Chores
Mar 10, 2023We study the problem of allocating indivisible chores among agents with binary supermodular cost functions. In other words, each chore has a marginal cost of $0$ or $1$ and chores exhibit increasing marginal costs (or decreasing marginal utilities). In this note, we combine the techniques of Viswanathan and Zick (2022) and Barman et al. (2023) to present a general framework for fair allocation with this class of valuation functions. Our framework allows us to generalize the results of Barman et al. (2023) and efficiently compute allocations which satisfy weighted notions of fairness like weighted leximin or min weighted $p$-mean malfare for any $p \ge 1$.
Dividing Good and Better Items Among Agents with Submodular Valuations
Feb 06, 2023

We study the problem of fairly allocating a set of indivisible goods among agents with bivalued submodular valuations -- each good provides a marginal gain of either $a$ or $b$ ($a < b$) and goods have decreasing marginal gains. This is a natural generalization of two well-studied valuation classes -- bivalued additive valuations and binary submodular valuations. We present a simple sequential algorithmic framework, based on the recently introduced Yankee Swap mechanism, that can be adapted to compute a variety of solution concepts, including leximin, max Nash welfare (MNW) and $p$-mean welfare maximizing allocations when $a$ divides $b$. This result is complemented by an existing result on the computational intractability of leximin and MNW allocations when $a$ does not divide $b$. We further examine leximin and MNW allocations with respect to two well-known properties -- envy freeness and the maximin share guarantee. On envy freeness, we show that neither the leximin nor the MNW allocation is guaranteed to be envy free up to one good (EF1). This is surprising since for the simpler classes of bivalued additive valuations and binary submodular valuations, MNW allocations are known to be envy free up to any good (EFX). On the maximin share guarantee, we show that MNW and leximin allocations guarantee each agent $\frac14$ and $\frac{a}{b+3a}$ of their maximin share respectively when $a$ divides $b$. This fraction improves to $\frac13$ and $\frac{a}{b+2a}$ respectively when agents have bivalued additive valuations.
Yankee Swap: a Fast and Simple Fair Allocation Mechanism for Matroid Rank Valuations
Jun 28, 2022
We study fair allocation of indivisible goods when agents have matroid rank valuations. Our main contribution is a simple algorithm based on the colloquial Yankee Swap procedure that computes provably fair and efficient Lorenz dominating allocations. While there exist polynomial time algorithms to compute such allocations, our proposed method improves on them in two ways. (a) Our approach is easy to understand and does not use complex matroid optimization algorithms as subroutines. (b) Our approach is scalable; it is provably faster than all known algorithms to compute Lorenz dominating allocations. These two properties are key to the adoption of algorithms in any real fair allocation setting; our contribution brings us one step closer to this goal.