 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimal Multi-draft Speculative Decoding
Feb 26, 2025Large Language Models (LLMs) have become an indispensable part of natural language processing tasks. However, autoregressive sampling has become an efficiency bottleneck. Multi-Draft Speculative Decoding (MDSD) is a recent approach where, when generating each token, a small draft model generates multiple drafts, and the target LLM verifies them in parallel, ensuring that the final output conforms to the target model distribution. The two main design choices in MDSD are the draft sampling method and the verification algorithm. For a fixed draft sampling method, the optimal acceptance rate is a solution to an optimal transport problem, but the complexity of this problem makes it difficult to solve for the optimal acceptance rate and measure the gap between existing verification algorithms and the theoretical upper bound. This paper discusses the dual of the optimal transport problem, providing a way to efficiently compute the optimal acceptance rate. For the first time, we measure the theoretical upper bound of MDSD efficiency for vocabulary sizes in the thousands and quantify the gap between existing verification algorithms and this bound. We also compare different draft sampling methods based on their optimal acceptance rates. Our results show that the draft sampling method strongly influences the optimal acceptance rate, with sampling without replacement outperforming sampling with replacement. Additionally, existing verification algorithms do not reach the theoretical upper bound for both without replacement and with replacement sampling. Our findings suggest that carefully designed draft sampling methods can potentially improve the optimal acceptance rate and enable the development of verification algorithms that closely match the theoretical upper bound.
Axiomatic Aggregations of Abductive Explanations
Oct 12, 2023
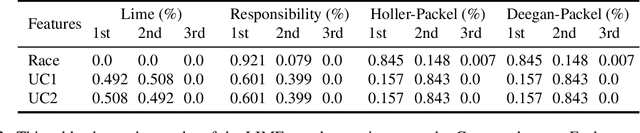

The recent criticisms of the robustness of post hoc model approximation explanation methods (like LIME and SHAP) have led to the rise of model-precise abductive explanations. For each data point, abductive explanations provide a minimal subset of features that are sufficient to generate the outcome. While theoretically sound and rigorous, abductive explanations suffer from a major issue -- there can be several valid abductive explanations for the same data point. In such cases, providing a single abductive explanation can be insufficient; on the other hand, providing all valid abductive explanations can be incomprehensible due to their size. In this work, we solve this issue by aggregating the many possible abductive explanations into feature importance scores. We propose three aggregation methods: two based on power indices from cooperative game theory and a third based on a well-known measure of causal strength. We characterize these three methods axiomatically, showing that each of them uniquely satisfies a set of desirable properties. We also evaluate them on multiple datasets and show that these explanations are robust to the attacks that fool SHAP and LIME.
Simple Steps to Success: Axiomatics of Distance-Based Algorithmic Recourse
Jun 27, 2023



We propose a novel data-driven framework for algorithmic recourse that offers users interventions to change their predicted outcome. Existing approaches to compute recourse find a set of points that satisfy some desiderata -- e.g. an intervention in the underlying causal graph, or minimizing a cost function. Satisfying these criteria, however, requires extensive knowledge of the underlying model structure, often an unrealistic amount of information in several domains. We propose a data-driven, computationally efficient approach to computing algorithmic recourse. We do so by suggesting directions in the data manifold that users can take to change their predicted outcome. We present Stepwise Explainable Paths (StEP), an axiomatically justified framework to compute direction-based algorithmic recourse. We offer a thorough empirical and theoretical investigation of StEP. StEP offers provable privacy and robustness guarantees, and outperforms the state-of-the-art on several established recourse desiderata.
Weighted Notions of Fairness with Binary Supermodular Chores
Mar 10, 2023We study the problem of allocating indivisible chores among agents with binary supermodular cost functions. In other words, each chore has a marginal cost of $0$ or $1$ and chores exhibit increasing marginal costs (or decreasing marginal utilities). In this note, we combine the techniques of Viswanathan and Zick (2022) and Barman et al. (2023) to present a general framework for fair allocation with this class of valuation functions. Our framework allows us to generalize the results of Barman et al. (2023) and efficiently compute allocations which satisfy weighted notions of fairness like weighted leximin or min weighted $p$-mean malfare for any $p \ge 1$.
Dividing Good and Better Items Among Agents with Submodular Valuations
Feb 06, 2023

We study the problem of fairly allocating a set of indivisible goods among agents with bivalued submodular valuations -- each good provides a marginal gain of either $a$ or $b$ ($a < b$) and goods have decreasing marginal gains. This is a natural generalization of two well-studied valuation classes -- bivalued additive valuations and binary submodular valuations. We present a simple sequential algorithmic framework, based on the recently introduced Yankee Swap mechanism, that can be adapted to compute a variety of solution concepts, including leximin, max Nash welfare (MNW) and $p$-mean welfare maximizing allocations when $a$ divides $b$. This result is complemented by an existing result on the computational intractability of leximin and MNW allocations when $a$ does not divide $b$. We further examine leximin and MNW allocations with respect to two well-known properties -- envy freeness and the maximin share guarantee. On envy freeness, we show that neither the leximin nor the MNW allocation is guaranteed to be envy free up to one good (EF1). This is surprising since for the simpler classes of bivalued additive valuations and binary submodular valuations, MNW allocations are known to be envy free up to any good (EFX). On the maximin share guarantee, we show that MNW and leximin allocations guarantee each agent $\frac14$ and $\frac{a}{b+3a}$ of their maximin share respectively when $a$ divides $b$. This fraction improves to $\frac13$ and $\frac{a}{b+2a}$ respectively when agents have bivalued additive valuations.
Graphical House Allocation
Jan 03, 2023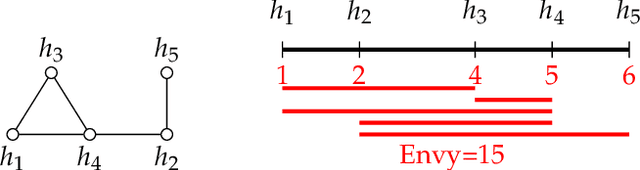


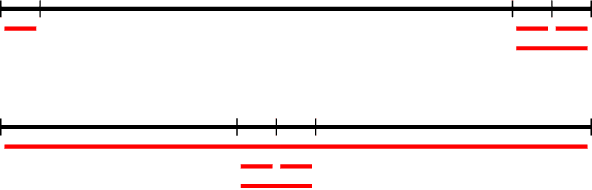
The classical house allocation problem involves assigning $n$ houses (or items) to $n$ agents according to their preferences. A key criterion in such problems is satisfying some fairness constraints such as envy-freeness. We consider a generalization of this problem wherein the agents are placed along the vertices of a graph (corresponding to a social network), and each agent can only experience envy towards its neighbors. Our goal is to minimize the aggregate envy among the agents as a natural fairness objective, i.e., the sum of all pairwise envy values over all edges in a social graph. When agents have identical and evenly-spaced valuations, our problem reduces to the well-studied problem of linear arrangements. For identical valuations with possibly uneven spacing, we show a number of deep and surprising ways in which our setting is a departure from this classical problem. More broadly, we contribute several structural and computational results for various classes of graphs, including NP-hardness results for disjoint unions of paths, cycles, stars, or cliques, and fixed-parameter tractable (and, in some cases, polynomial-time) algorithms for paths, cycles, stars, cliques, and their disjoint unions. Additionally, a conceptual contribution of our work is the formulation of a structural property for disconnected graphs that we call separability which results in efficient parameterized algorithms for finding optimal allocations.
Yankee Swap: a Fast and Simple Fair Allocation Mechanism for Matroid Rank Valuations
Jun 28, 2022
We study fair allocation of indivisible goods when agents have matroid rank valuations. Our main contribution is a simple algorithm based on the colloquial Yankee Swap procedure that computes provably fair and efficient Lorenz dominating allocations. While there exist polynomial time algorithms to compute such allocations, our proposed method improves on them in two ways. (a) Our approach is easy to understand and does not use complex matroid optimization algorithms as subroutines. (b) Our approach is scalable; it is provably faster than all known algorithms to compute Lorenz dominating allocations. These two properties are key to the adoption of algorithms in any real fair allocation setting; our contribution brings us one step closer to this goal.
Model Explanations via the Axiomatic Causal Lens
Sep 17, 2021
Explaining the decisions of black-box models has been a central theme in the study of trustworthy ML. Numerous measures have been proposed in the literature; however, none of them have been able to adopt a provably causal take on explainability. Building upon Halpern and Pearl's formal definition of a causal explanation, we derive an analogous set of axioms for the classification setting, and use them to derive three explanation measures. Our first measure is a natural adaptation of Chockler and Halpern's notion of causal responsibility, whereas the other two correspond to existing game-theoretic influence measures. We present an axiomatic treatment for our proposed indices, showing that they can be uniquely characterized by a set of desirable properties. We compliment this with computational analysis, providing probabilistic approximation schemes for all of our proposed measures. Thus, our work is the first to formally bridge the gap between model explanations, game-theoretic influence, and causal analysis.
The Price is Right: Learning Market Equilibria from Samples
Dec 29, 2020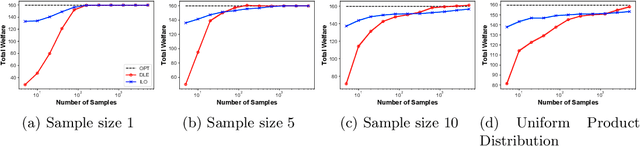
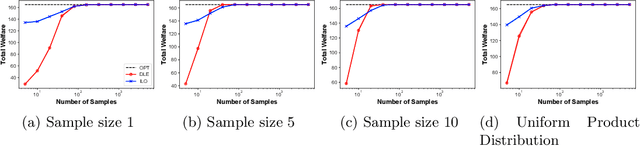
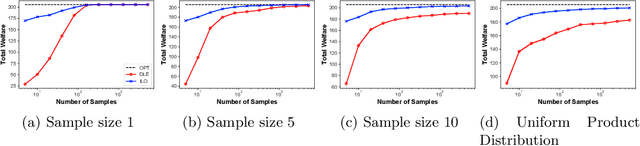

Equilibrium computation in markets usually considers settings where player valuation functions are known. We consider the setting where player valuations are unknown; using a PAC learning-theoretic framework, we analyze some classes of common valuation functions, and provide algorithms which output direct PAC equilibrium allocations, not estimates based on attempting to learn valuation functions. Since there exist trivial PAC market outcomes with an unbounded worst-case efficiency loss, we lower-bound the efficiency of our algorithms. While the efficiency loss under general distributions is rather high, we show that in some cases (e.g., unit-demand valuations), it is possible to find a PAC market equilibrium with significantly better utility.