 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall RL Controller, Large Language Model: RL-Guided Adaptive Sampling for Test-Time Scaling
Jun 02, 2026Test-time scaling improves the reasoning performance of large language models but incurs substantial cost in both total computation and latency. Existing adaptive sampling methods partially mitigate this issue by dynamically deciding when to stop sampling, yet they typically rely on heuristic rules or rely on distribution assumptions. In this work, we formulate adaptive sampling as a Markov decision process (MDP). We train a lightweight sampling controller with reinforcement learning (RL) to jointly balance answer correctness, latency, and computation cost. At each round, the controller decides to stop sampling or to acquire additional samples. Our method is lightweight which only relies on statistics of final answers, and can be trained and deployed on CPU. We further show that the resulting framework admits an interpretation as the Lagrangian relaxation of a constrained optimization problem with explicit budget constraints. Experiments against strong baselines such as ASC and ESC show that our method achieves improved trade-offs among answer correctness, sampling rounds, and total samples required.
G-Zero: Self-Play for Open-Ended Generation from Zero Data
May 11, 2026Self-evolving LLMs excel in verifiable domains but struggle in open-ended tasks, where reliance on proxy LLM judges introduces capability bottlenecks and reward hacking. To overcome this, we introduce G-Zero, a verifier-free, co-evolutionary framework for autonomous self-improvement. Our core innovation is Hint-$δ$, an intrinsic reward that quantifies the predictive shift between a Generator model's unassisted response and its response conditioned on a self-generated hint. Using this signal, a Proposer model is trained via GRPO to continuously target the Generator's blind spots by synthesizing challenging queries and informative hints. The Generator is concurrently optimized via DPO to internalize these hint-guided improvements. Theoretically, we prove a best-iterate suboptimality guarantee for an idealized standard-DPO version of G-Zero, provided that the Proposer induces sufficient exploration coverage and the data filteration keeps pseudo-label score noise low. By deriving supervision entirely from internal distributional dynamics, G-Zero bypasses the capability ceilings of external judges, providing a scalable, robust pathway for continuous LLM self-evolution across unverifiable domains.
DeltaRubric: Generative Multimodal Reward Modeling via Joint Planning and Verification
May 10, 2026Aligning Multimodal Large Language Models (MLLMs) requires reliable reward models, yet existing single-step evaluators can suffer from lazy judging, exploiting language priors over fine-grained visual verification. While rubric-based evaluation mitigates these biases in text-only settings, extending it to multimodal tasks is bottlenecked by the complexity of visual reasoning. The critical differences between responses often depend on instance-specific visual details. Robust evaluation requires dynamically synthesizing rubrics that isolate spatial and factual discrepancies. To address this, we introduce $\textbf{DeltaRubric}$, an approach that reformulates multimodal preference evaluation as a plan-and-execute process within a single MLLM. DeltaRubric operates in two steps: acting first as a $\textit{Disagreement Planner}$, the model generates a neutral, instance-specific verification checklist. Transitioning into a $\textit{Checklist Verifier}$, it executes these self-generated checks against the image and question to produce the final grounded judgment. We formulate DeltaRubric as a multi-role reinforcement learning problem, jointly optimizing planning and verification capabilities. Validated on Qwen3-VL 4B and 8B Instruct models, DeltaRubric achieves solid empirical gains. For instance, On VL-RewardBench, it improves base model overall accuracy by $\textbf{+22.6}$ (4B) and $\textbf{+18.8}$ (8B) points, largely outperforming standard no-rubric baselines. The results demonstrate that decomposing evaluation into structured, verifiable steps leads to more reliable and generalizable multimodal reward modeling.
Reinforcing Multimodal Reasoning Against Visual Degradation
May 10, 2026Reinforcement Learning has significantly advanced the reasoning capabilities of Multimodal Large Language Models (MLLMs), yet the resulting policies remain brittle against real-world visual degradations such as blur, compression artifacts, and low-resolution scans. Prior robustness techniques from vision and deep RL rely on static data augmentation or value-based regularization, neither of which transfers cleanly to critic-free RL fine-tuning of autoregressive MLLMs. Reinforcing reasoning against such corruptions is non-trivial: naively injecting degraded views during rollout induces reward poisoning, where perceptual occlusions trigger hallucinated trajectories and destabilize optimization. We propose ROMA, an RL fine-tuning framework that modifies the optimization dynamics to reinforce reasoning against visual degradation while preserving clean-input performance. A dual-forward-pass strategy uses teacher forcing to evaluate corrupted views against clean-image trajectories, avoiding new rollouts on degraded inputs. For distributional consistency, we apply a token-level surrogate KL penalty against the worst-case augmentation; to prevent policy collapse under regularization, an auxiliary policy gradient loss anchored to clean-image advantages preserves a reliable reward signal; and to avoid systematically incorrect invariance, correctness-conditioned regularization restricts enforcement to successful trajectories. On Qwen3-VL 4B/8B across seven multimodal reasoning benchmarks, our method improves robustness by +2.4% on seen and +2.3% on unseen corruptions over GRPO while matching clean accuracy.
Parallel-Probe: Towards Efficient Parallel Thinking via 2D Probing
Feb 03, 2026Parallel thinking has emerged as a promising paradigm for reasoning, yet it imposes significant computational burdens. Existing efficiency methods primarily rely on local, per-trajectory signals and lack principled mechanisms to exploit global dynamics across parallel branches. We introduce 2D probing, an interface that exposes the width-depth dynamics of parallel thinking by periodically eliciting intermediate answers from all branches. Our analysis reveals three key insights: non-monotonic scaling across width-depth allocations, heterogeneous reasoning branch lengths, and early stabilization of global consensus. Guided by these insights, we introduce $\textbf{Parallel-Probe}$, a training-free controller designed to optimize online parallel thinking. Parallel-Probe employs consensus-based early stopping to regulate reasoning depth and deviation-based branch pruning to dynamically adjust width. Extensive experiments across three benchmarks and multiple models demonstrate that Parallel-Probe establishes a superior Pareto frontier for test-time scaling. Compared to standard majority voting, it reduces sequential tokens by up to $\textbf{35.8}$% and total token cost by over $\textbf{25.8}$% while maintaining competitive accuracy.
Prepare Reasoning Language Models for Multi-Agent Debate with Self-Debate Reinforcement Learning
Jan 29, 2026The reasoning abilities of large language models (LLMs) have been substantially improved by reinforcement learning with verifiable rewards (RLVR). At test time, collaborative reasoning through Multi-Agent Debate (MAD) has emerged as a promising approach for enhancing LLM performance. However, current RLVR methods typically train LLMs to solve problems in isolation, without explicitly preparing them to synthesize and benefit from different rationales that arise during debate. In this work, we propose Self-Debate Reinforcement Learning (SDRL), a training framework that equips a single LLM with strong standalone problem-solving ability and the capability to learn from diverse reasoning trajectories in MAD. Given a prompt, SDRL first samples multiple candidate solutions, then constructs a debate context with diverse reasoning paths and generates second-turn responses conditioned on this context. Finally, SDRL jointly optimizes both the initial and debate-conditioned responses, yielding a model that is effective as both a standalone solver and a debate participant. Experiments across multiple base models and reasoning benchmarks show that SDRL improves overall MAD performance while simultaneously strengthening single model reasoning.
RelayLLM: Efficient Reasoning via Collaborative Decoding
Jan 08, 2026Large Language Models (LLMs) for complex reasoning is often hindered by high computational costs and latency, while resource-efficient Small Language Models (SLMs) typically lack the necessary reasoning capacity. Existing collaborative approaches, such as cascading or routing, operate at a coarse granularity by offloading entire queries to LLMs, resulting in significant computational waste when the SLM is capable of handling the majority of reasoning steps. To address this, we propose RelayLLM, a novel framework for efficient reasoning via token-level collaborative decoding. Unlike routers, RelayLLM empowers the SLM to act as an active controller that dynamically invokes the LLM only for critical tokens via a special command, effectively "relaying" the generation process. We introduce a two-stage training framework, including warm-up and Group Relative Policy Optimization (GRPO) to teach the model to balance independence with strategic help-seeking. Empirical results across six benchmarks demonstrate that RelayLLM achieves an average accuracy of 49.52%, effectively bridging the performance gap between the two models. Notably, this is achieved by invoking the LLM for only 1.07% of the total generated tokens, offering a 98.2% cost reduction compared to performance-matched random routers.
ImAgent: A Unified Multimodal Agent Framework for Test-Time Scalable Image Generation
Nov 14, 2025Recent text-to-image (T2I) models have made remarkable progress in generating visually realistic and semantically coherent images. However, they still suffer from randomness and inconsistency with the given prompts, particularly when textual descriptions are vague or underspecified. Existing approaches, such as prompt rewriting, best-of-N sampling, and self-refinement, can mitigate these issues but usually require additional modules and operate independently, hindering test-time scaling efficiency and increasing computational overhead. In this paper, we introduce ImAgent, a training-free unified multimodal agent that integrates reasoning, generation, and self-evaluation within a single framework for efficient test-time scaling. Guided by a policy controller, multiple generation actions dynamically interact and self-organize to enhance image fidelity and semantic alignment without relying on external models. Extensive experiments on image generation and editing tasks demonstrate that ImAgent consistently improves over the backbone and even surpasses other strong baselines where the backbone model fails, highlighting the potential of unified multimodal agents for adaptive and efficient image generation under test-time scaling.
Beyond English: Toward Inclusive and Scalable Multilingual Machine Translation with LLMs
Nov 10, 2025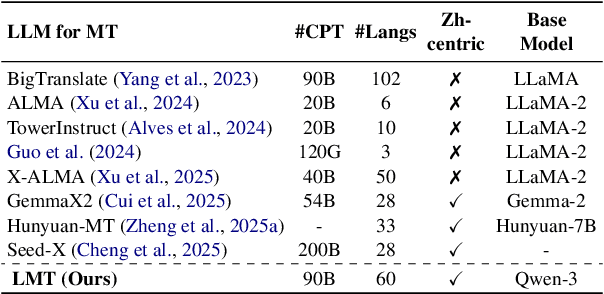
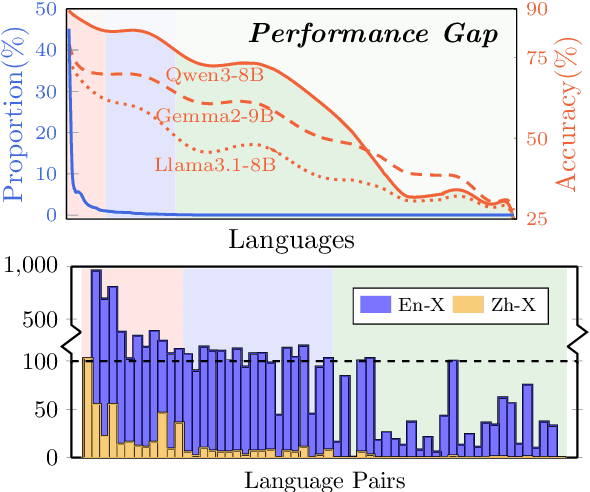
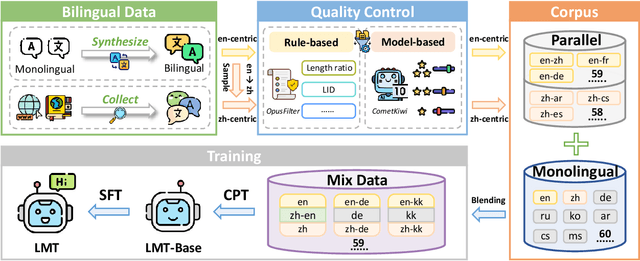
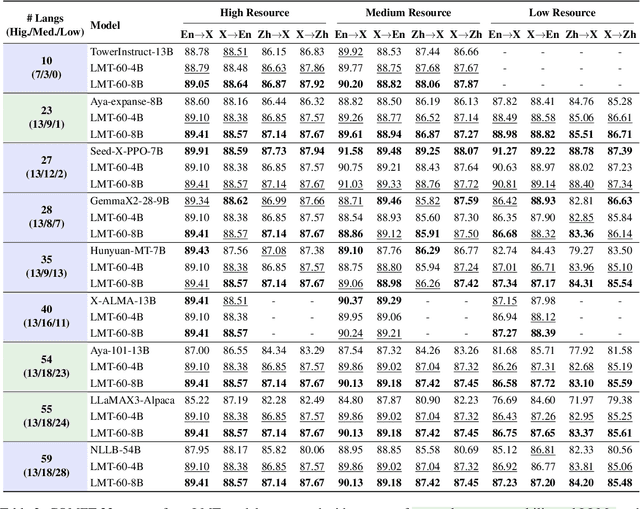
Large language models have significantly advanced Multilingual Machine Translation (MMT), yet the broad language coverage, consistent translation quality, and English-centric bias remain open challenges. To address these challenges, we introduce \textbf{LMT}, a suite of \textbf{L}arge-scale \textbf{M}ultilingual \textbf{T}ranslation models centered on both Chinese and English, covering 60 languages and 234 translation directions. During development, we identify a previously overlooked phenomenon of \textbf{directional degeneration}, where symmetric multi-way fine-tuning data overemphasize reverse directions (X $\to$ En/Zh), leading to excessive many-to-one mappings and degraded translation quality. We propose \textbf{Strategic Downsampling}, a simple yet effective method to mitigate this degeneration. In addition, we design \textbf{Parallel Multilingual Prompting (PMP)}, which leverages typologically related auxiliary languages to enhance cross-lingual transfer. Through rigorous data curation and refined adaptation strategies, LMT achieves SOTA performance among models of comparable language coverage, with our 4B model (LMT-60-4B) surpassing the much larger Aya-101-13B and NLLB-54B models by a substantial margin. We release LMT in four sizes (0.6B/1.7B/4B/8B) to catalyze future research and provide strong baselines for inclusive, scalable, and high-quality MMT \footnote{\href{https://github.com/NiuTrans/LMT}{https://github.com/NiuTrans/LMT}}.
VOGUE: Guiding Exploration with Visual Uncertainty Improves Multimodal Reasoning
Oct 01, 2025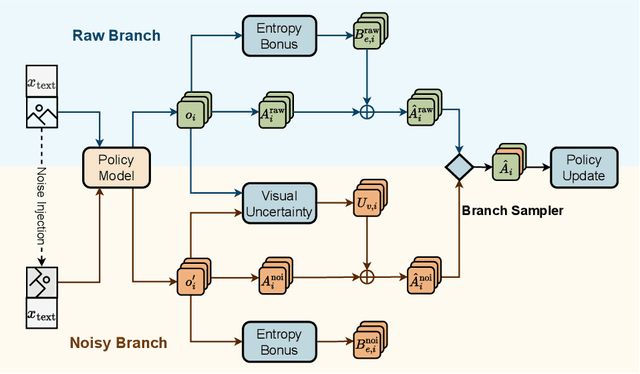
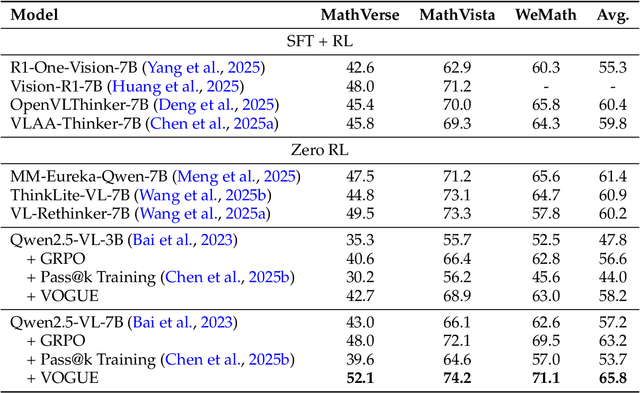
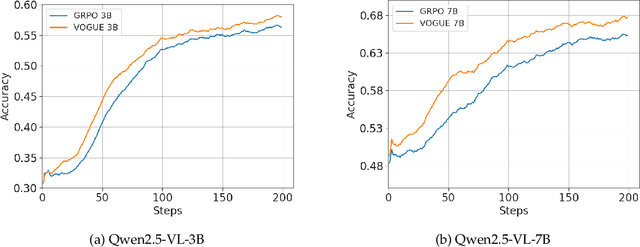
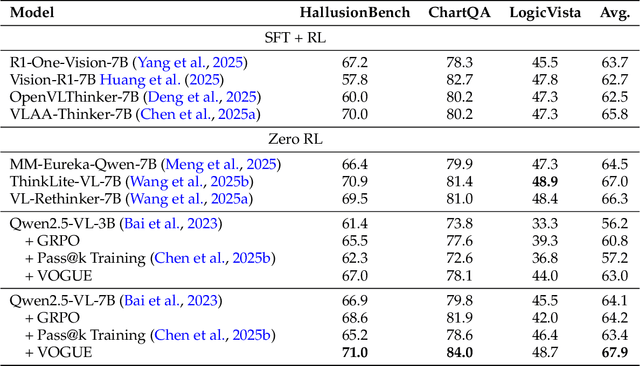
Reinforcement learning with verifiable rewards (RLVR) improves reasoning in large language models (LLMs) but struggles with exploration, an issue that still persists for multimodal LLMs (MLLMs). Current methods treat the visual input as a fixed, deterministic condition, overlooking a critical source of ambiguity and struggling to build policies robust to plausible visual variations. We introduce $\textbf{VOGUE (Visual Uncertainty Guided Exploration)}$, a novel method that shifts exploration from the output (text) to the input (visual) space. By treating the image as a stochastic context, VOGUE quantifies the policy's sensitivity to visual perturbations using the symmetric KL divergence between a "raw" and "noisy" branch, creating a direct signal for uncertainty-aware exploration. This signal shapes the learning objective via an uncertainty-proportional bonus, which, combined with a token-entropy bonus and an annealed sampling schedule, effectively balances exploration and exploitation. Implemented within GRPO on two model scales (Qwen2.5-VL-3B/7B), VOGUE boosts pass@1 accuracy by an average of 2.6% on three visual math benchmarks and 3.7% on three general-domain reasoning benchmarks, while simultaneously increasing pass@4 performance and mitigating the exploration decay commonly observed in RL fine-tuning. Our work shows that grounding exploration in the inherent uncertainty of visual inputs is an effective strategy for improving multimodal reasoning.