 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA benchmark multimodal oro-dental dataset for large vision-language models
Nov 07, 2025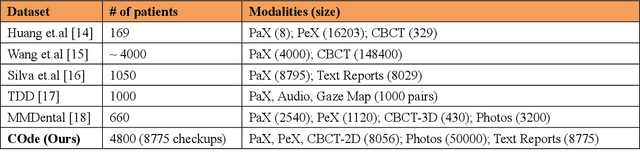
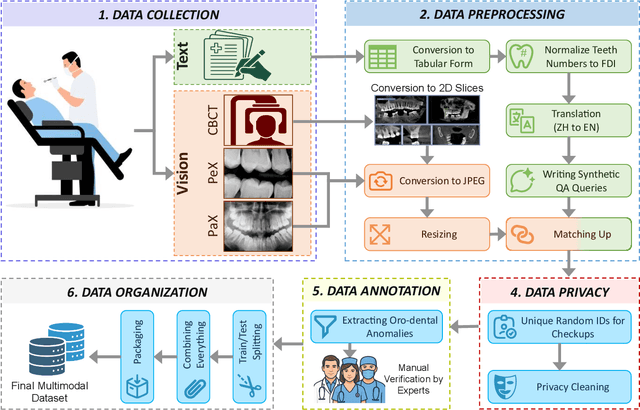
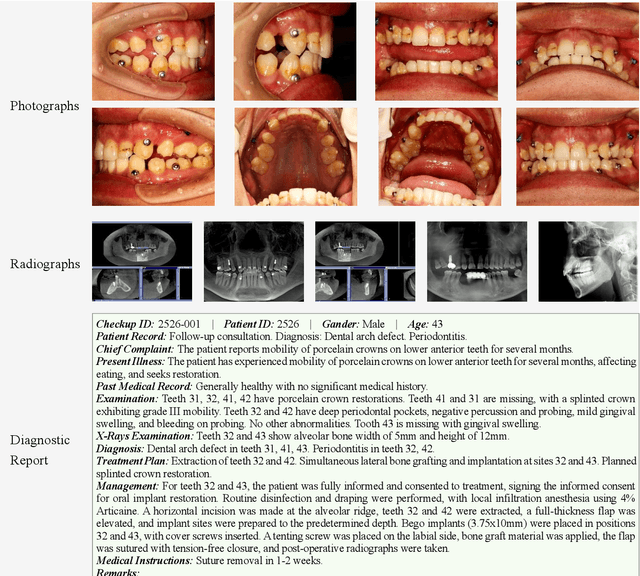
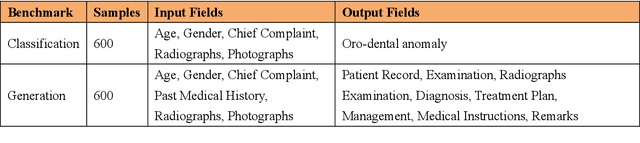
The advancement of artificial intelligence in oral healthcare relies on the availability of large-scale multimodal datasets that capture the complexity of clinical practice. In this paper, we present a comprehensive multimodal dataset, comprising 8775 dental checkups from 4800 patients collected over eight years (2018-2025), with patients ranging from 10 to 90 years of age. The dataset includes 50000 intraoral images, 8056 radiographs, and detailed textual records, including diagnoses, treatment plans, and follow-up notes. The data were collected under standard ethical guidelines and annotated for benchmarking. To demonstrate its utility, we fine-tuned state-of-the-art large vision-language models, Qwen-VL 3B and 7B, and evaluated them on two tasks: classification of six oro-dental anomalies and generation of complete diagnostic reports from multimodal inputs. We compared the fine-tuned models with their base counterparts and GPT-4o. The fine-tuned models achieved substantial gains over these baselines, validating the dataset and underscoring its effectiveness in advancing AI-driven oro-dental healthcare solutions. The dataset is publicly available, providing an essential resource for future research in AI dentistry.
FuzzCoder: Byte-level Fuzzing Test via Large Language Model
Sep 03, 2024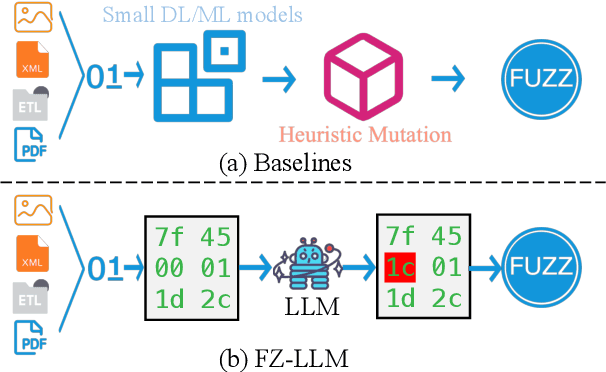
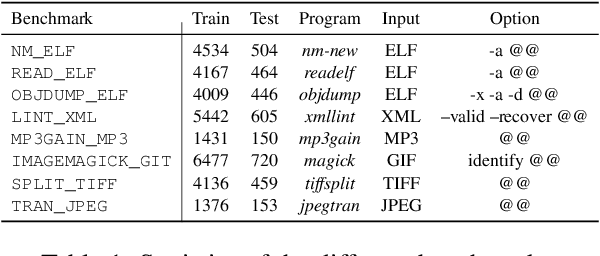
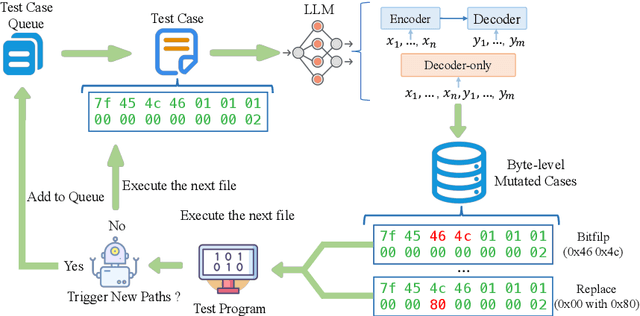
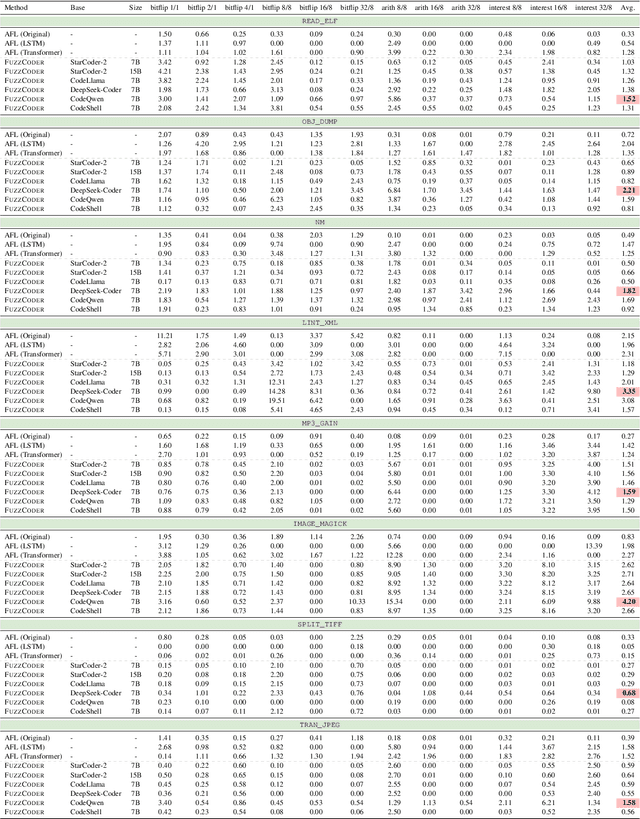
Fuzzing is an important dynamic program analysis technique designed for finding vulnerabilities in complex software. Fuzzing involves presenting a target program with crafted malicious input to cause crashes, buffer overflows, memory errors, and exceptions. Crafting malicious inputs in an efficient manner is a difficult open problem and the best approaches often apply uniform random mutations to pre-existing valid inputs. In this work, we propose to adopt fine-tuned large language models (FuzzCoder) to learn patterns in the input files from successful attacks to guide future fuzzing explorations. Specifically, we develop a framework to leverage the code LLMs to guide the mutation process of inputs in fuzzing. The mutation process is formulated as the sequence-to-sequence modeling, where LLM receives a sequence of bytes and then outputs the mutated byte sequence. FuzzCoder is fine-tuned on the created instruction dataset (Fuzz-Instruct), where the successful fuzzing history is collected from the heuristic fuzzing tool. FuzzCoder can predict mutation locations and strategies locations in input files to trigger abnormal behaviors of the program. Experimental results show that FuzzCoder based on AFL (American Fuzzy Lop) gain significant improvements in terms of effective proportion of mutation (EPM) and number of crashes (NC) for various input formats including ELF, JPG, MP3, and XML.
TNF: Tri-branch Neural Fusion for Multimodal Medical Data Classification
Mar 10, 2024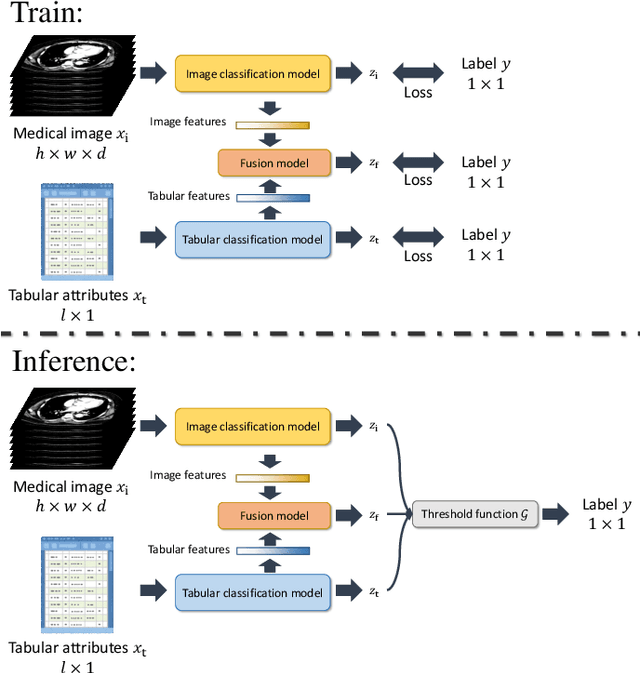
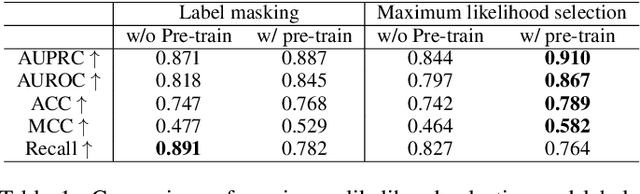

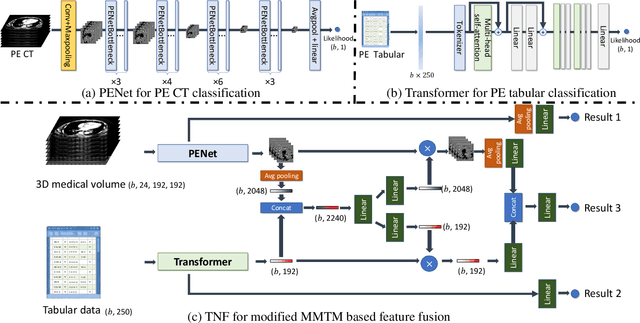
This paper presents a Tri-branch Neural Fusion (TNF) approach designed for classifying multimodal medical images and tabular data. It also introduces two solutions to address the challenge of label inconsistency in multimodal classification. Traditional methods in multi-modality medical data classification often rely on single-label approaches, typically merging features from two distinct input modalities. This becomes problematic when features are mutually exclusive or labels differ across modalities, leading to reduced accuracy. To overcome this, our TNF approach implements a tri-branch framework that manages three separate outputs: one for image modality, another for tabular modality, and a third hybrid output that fuses both image and tabular data. The final decision is made through an ensemble method that integrates likelihoods from all three branches. We validate the effectiveness of TNF through extensive experiments, which illustrate its superiority over traditional fusion and ensemble methods in various convolutional neural networks and transformer-based architectures across multiple datasets.
WeaveNet for Approximating Two-sided Matching Problems
Oct 19, 2023Matching, a task to optimally assign limited resources under constraints, is a fundamental technology for society. The task potentially has various objectives, conditions, and constraints; however, the efficient neural network architecture for matching is underexplored. This paper proposes a novel graph neural network (GNN), \textit{WeaveNet}, designed for bipartite graphs. Since a bipartite graph is generally dense, general GNN architectures lose node-wise information by over-smoothing when deeply stacked. Such a phenomenon is undesirable for solving matching problems. WeaveNet avoids it by preserving edge-wise information while passing messages densely to reach a better solution. To evaluate the model, we approximated one of the \textit{strongly NP-hard} problems, \textit{fair stable matching}. Despite its inherent difficulties and the network's general purpose design, our model reached a comparative performance with state-of-the-art algorithms specially designed for stable matching for small numbers of agents.
Edge-Selective Feature Weaving for Point Cloud Matching
Feb 08, 2022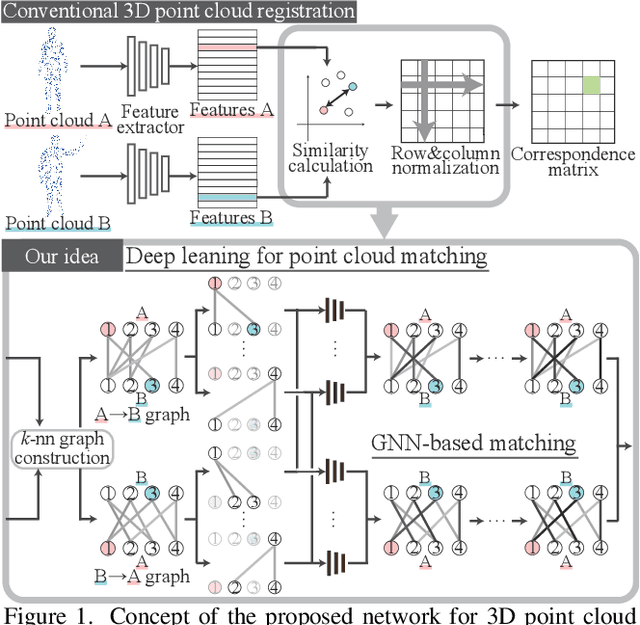
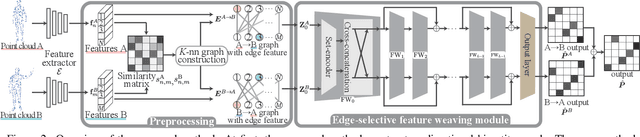
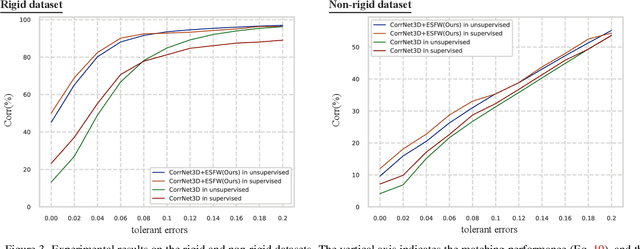

This paper tackles the problem of accurately matching the points of two 3D point clouds. Most conventional methods improve their performance by extracting representative features from each point via deep-learning-based algorithms. On the other hand, the correspondence calculation between the extracted features has not been examined in depth, and non-trainable algorithms (e.g. the Sinkhorn algorithm) are frequently applied. As a result, the extracted features may be forcibly fitted to a non-trainable algorithm. Furthermore, the extracted features frequently contain stochastically unavoidable errors, which degrades the matching accuracy. In this paper, instead of using a non-trainable algorithm, we propose a differentiable matching network that can be jointly optimized with the feature extraction procedure. Our network first constructs graphs with edges connecting the points of each point cloud and then extracts discriminative edge features by using two main components: a shared set-encoder and an edge-selective cross-concatenation. These components enable us to symmetrically consider two point clouds and to extract discriminative edge features, respectively. By using the extracted discriminative edge features, our network can accurately calculate the correspondence between points. Our experimental results show that the proposed network can significantly improve the performance of point cloud matching. Our code is available at https://github.com/yanarin/ESFW
Adaptive Distillation for Decentralized Learning from Heterogeneous Clients
Aug 18, 2020
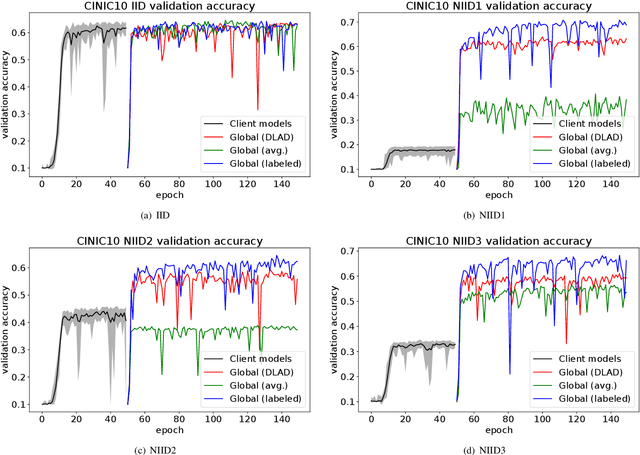
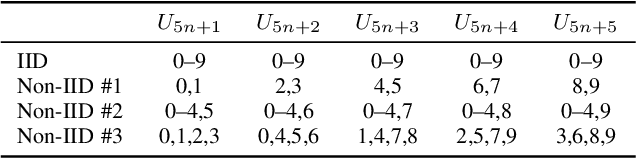

This paper addresses the problem of decentralized learning to achieve a high-performance global model by asking a group of clients to share local models pre-trained with their own data resources. We are particularly interested in a specific case where both the client model architectures and data distributions are diverse, which makes it nontrivial to adopt conventional approaches such as Federated Learning and network co-distillation. To this end, we propose a new decentralized learning method called Decentralized Learning via Adaptive Distillation (DLAD). Given a collection of client models and a large number of unlabeled distillation samples, the proposed DLAD 1) aggregates the outputs of the client models while adaptively emphasizing those with higher confidence in given distillation samples and 2) trains the global model to imitate the aggregated outputs. Our extensive experimental evaluation on multiple public datasets (MNIST, CIFAR-10, and CINIC-10) demonstrates the effectiveness of the proposed method.