 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025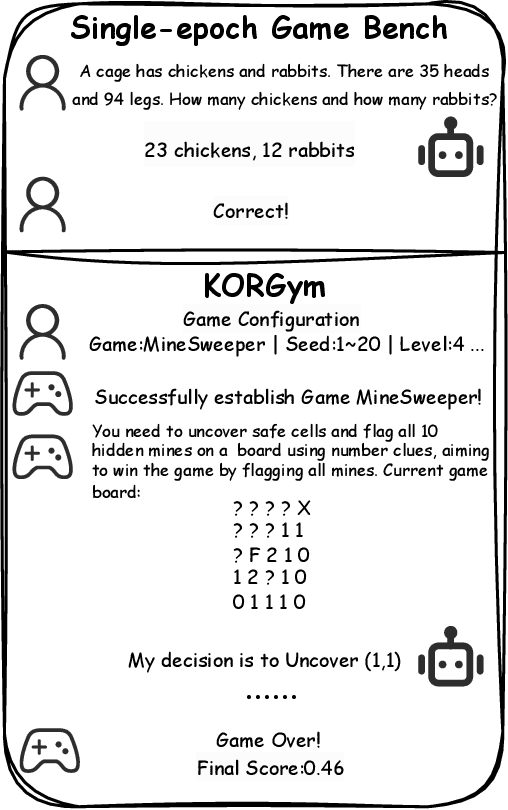
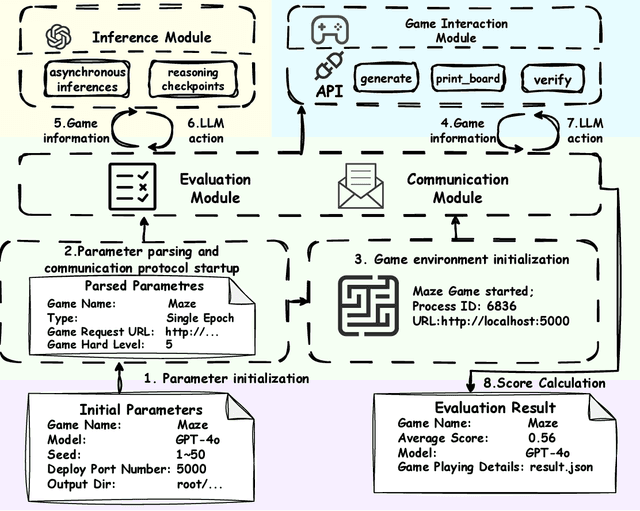

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
Learning Cascade Ranking as One Network
Mar 12, 2025Cascade Ranking is a prevalent architecture in large-scale top-k selection systems like recommendation and advertising platforms. Traditional training methods focus on single-stage optimization, neglecting interactions between stages. Recent advances such as RankFlow and FS-LTR have introduced interaction-aware training paradigms but still struggle to 1) align training objectives with the goal of the entire cascade ranking (i.e., end-to-end recall) and 2) learn effective collaboration patterns for different stages. To address these challenges, we propose LCRON, which introduces a novel surrogate loss function derived from the lower bound probability that ground truth items are selected by cascade ranking, ensuring alignment with the overall objective of the system. According to the properties of the derived bound, we further design an auxiliary loss for each stage to drive the reduction of this bound, leading to a more robust and effective top-k selection. LCRON enables end-to-end training of the entire cascade ranking system as a unified network. Experimental results demonstrate that LCRON achieves significant improvement over existing methods on public benchmarks and industrial applications, addressing key limitations in cascade ranking training and significantly enhancing system performance.
SED2AM: Solving Multi-Trip Time-Dependent Vehicle Routing Problem using Deep Reinforcement Learning
Mar 06, 2025Deep reinforcement learning (DRL)-based frameworks, featuring Transformer-style policy networks, have demonstrated their efficacy across various vehicle routing problem (VRP) variants. However, the application of these methods to the multi-trip time-dependent vehicle routing problem (MTTDVRP) with maximum working hours constraints -- a pivotal element of urban logistics -- remains largely unexplored. This paper introduces a DRL-based method called the Simultaneous Encoder and Dual Decoder Attention Model (SED2AM), tailored for the MTTDVRP with maximum working hours constraints. The proposed method introduces a temporal locality inductive bias to the encoding module of the policy networks, enabling it to effectively account for the time-dependency in travel distance or time. The decoding module of SED2AM includes a vehicle selection decoder that selects a vehicle from the fleet, effectively associating trips with vehicles for functional multi-trip routing. Additionally, this decoding module is equipped with a trip construction decoder leveraged for constructing trips for the vehicles. This policy model is equipped with two classes of state representations, fleet state and routing state, providing the information needed for effective route construction in the presence of maximum working hours constraints. Experimental results using real-world datasets from two major Canadian cities not only show that SED2AM outperforms the current state-of-the-art DRL-based and metaheuristic-based baselines but also demonstrate its generalizability to solve larger-scale problems.
Adaptive$^2$: Adaptive Domain Mining for Fine-grained Domain Adaptation Modeling
Dec 11, 2024



Advertising systems often face the multi-domain challenge, where data distributions vary significantly across scenarios. Existing domain adaptation methods primarily focus on building domain-adaptive neural networks but often rely on hand-crafted domain information, e.g., advertising placement, which may be sub-optimal. We think that fine-grained "domain" patterns exist that are difficult to hand-craft in online advertisement. Thus, we propose Adaptive$^2$, a novel framework that first learns domains adaptively using a domain mining module by self-supervision and then employs a shared&specific network to model shared and conflicting information. As a practice, we use VQ-VAE as the domain mining module and conduct extensive experiments on public benchmarks. Results show that traditional domain adaptation methods with hand-crafted domains perform no better than single-domain models under fair FLOPS conditions, highlighting the importance of domain definition. In contrast, Adaptive$^2$ outperforms existing approaches, emphasizing the effectiveness of our method and the significance of domain mining. We also deployed Adaptive$^2$ in the live streaming scenario of Kuaishou Advertising System, demonstrating its commercial value and potential for automatic domain identification. To the best of our knowledge, Adaptive$^2$ is the first approach to automatically learn both domain identification and adaptation in online advertising, opening new research directions for this area.
LDACP: Long-Delayed Ad Conversions Prediction Model for Bidding Strategy
Nov 25, 2024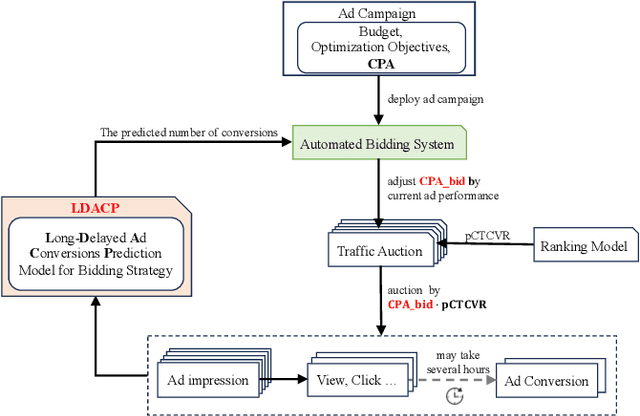

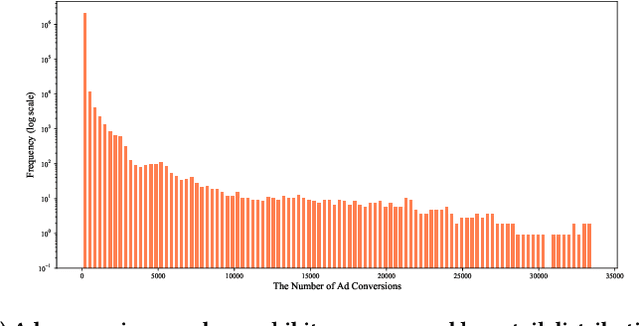

In online advertising, once an ad campaign is deployed, the automated bidding system dynamically adjusts the bidding strategy to optimize Cost Per Action (CPA) based on the number of ad conversions. For ads with a long conversion delay, relying solely on the real-time tracked conversion number as a signal for bidding strategy can significantly overestimate the current CPA, leading to conservative bidding strategies. Therefore, it is crucial to predict the number of long-delayed conversions. Nonetheless, it is challenging to predict ad conversion numbers through traditional regression methods due to the wide range of ad conversion numbers. Previous regression works have addressed this challenge by transforming regression problems into bucket classification problems, achieving success in various scenarios. However, specific challenges arise when predicting the number of ad conversions: 1) The integer nature of ad conversion numbers exacerbates the discontinuity issue in one-hot hard labels; 2) The long-tail distribution of ad conversion numbers complicates tail data prediction. In this paper, we propose the Long-Delayed Ad Conversions Prediction model for bidding strategy (LDACP), which consists of two sub-modules. To alleviate the issue of discontinuity in one-hot hard labels, the Bucket Classification Module with label Smoothing method (BCMS) converts one-hot hard labels into non-normalized soft labels, then fits these soft labels by minimizing classification loss and regression loss. To address the challenge of predicting tail data, the Value Regression Module with Proxy labels (VRMP) uses the prediction bias of aggregated pCTCVR as proxy labels. Finally, a Mixture of Experts (MoE) structure integrates the predictions from BCMS and VRMP to obtain the final predicted ad conversion number.
Scaling Laws for Online Advertisement Retrieval
Nov 20, 2024


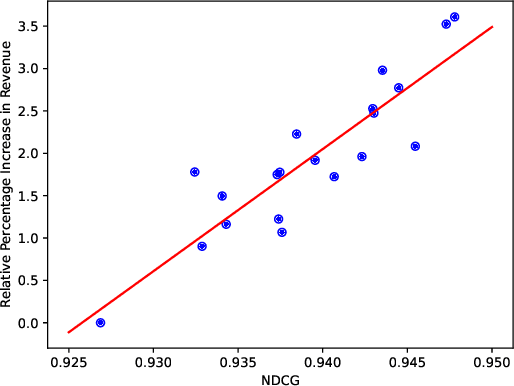
The scaling law is a notable property of neural network models and has significantly propelled the development of large language models. Scaling laws hold great promise in guiding model design and resource allocation. Recent research increasingly shows that scaling laws are not limited to NLP tasks or Transformer architectures; they also apply to domains such as recommendation. However, there is still a lack of literature on scaling law research in online advertisement retrieval systems. This may be because 1) identifying the scaling law for resource cost and online revenue is often expensive in both time and training resources for large-scale industrial applications, and 2) varying settings for different systems prevent the scaling law from being applied across various scenarios. To address these issues, we propose a lightweight paradigm to identify the scaling law of online revenue and machine cost for a certain online advertisement retrieval scenario with a low experimental cost. Specifically, we focus on a sole factor (FLOPs) and propose an offline metric named R/R* that exhibits a high linear correlation with online revenue for retrieval models. We estimate the machine cost offline via a simulation algorithm. Thus, we can transform most online experiments into low-cost offline experiments. We conduct comprehensive experiments to verify the effectiveness of our proposed metric R/R* and to identify the scaling law in the online advertisement retrieval system of Kuaishou. With the scaling law, we demonstrate practical applications for ROI-constrained model designing and multi-scenario resource allocation in Kuaishou advertising system. To the best of our knowledge, this is the first work to study the scaling laws for online advertisement retrieval of real-world systems, showing great potential for scaling law in advertising system optimization.
FuzzCoder: Byte-level Fuzzing Test via Large Language Model
Sep 03, 2024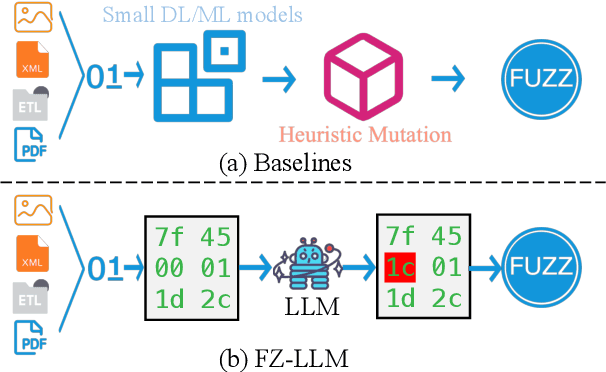
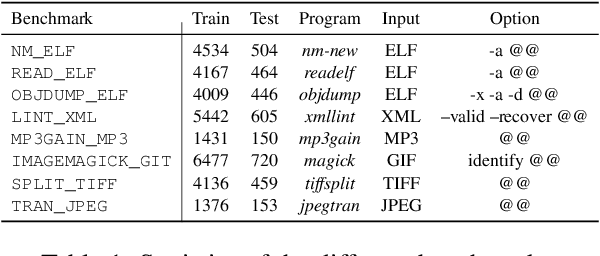
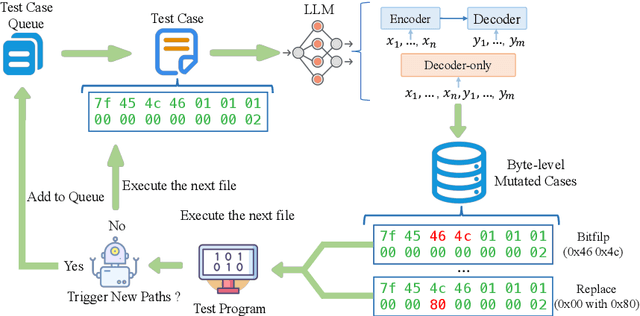
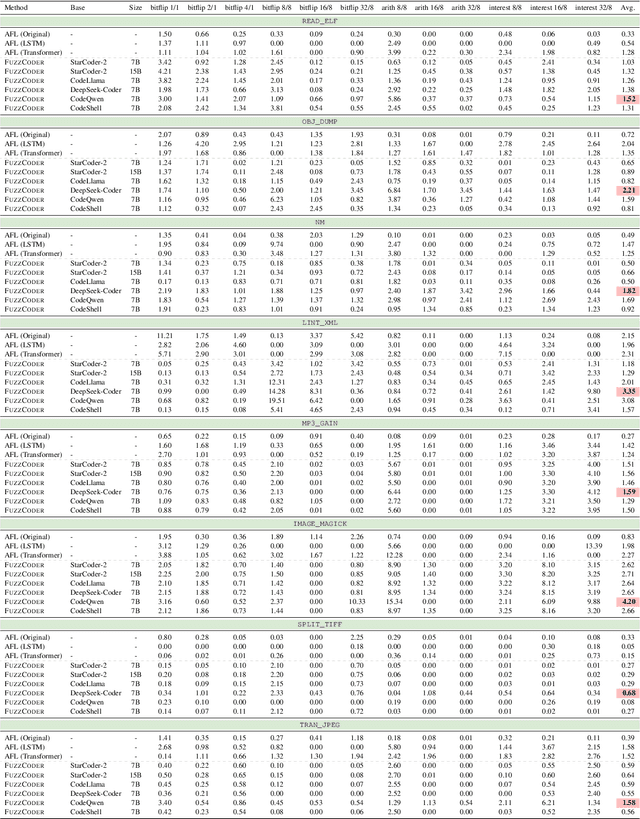
Fuzzing is an important dynamic program analysis technique designed for finding vulnerabilities in complex software. Fuzzing involves presenting a target program with crafted malicious input to cause crashes, buffer overflows, memory errors, and exceptions. Crafting malicious inputs in an efficient manner is a difficult open problem and the best approaches often apply uniform random mutations to pre-existing valid inputs. In this work, we propose to adopt fine-tuned large language models (FuzzCoder) to learn patterns in the input files from successful attacks to guide future fuzzing explorations. Specifically, we develop a framework to leverage the code LLMs to guide the mutation process of inputs in fuzzing. The mutation process is formulated as the sequence-to-sequence modeling, where LLM receives a sequence of bytes and then outputs the mutated byte sequence. FuzzCoder is fine-tuned on the created instruction dataset (Fuzz-Instruct), where the successful fuzzing history is collected from the heuristic fuzzing tool. FuzzCoder can predict mutation locations and strategies locations in input files to trigger abnormal behaviors of the program. Experimental results show that FuzzCoder based on AFL (American Fuzzy Lop) gain significant improvements in terms of effective proportion of mutation (EPM) and number of crashes (NC) for various input formats including ELF, JPG, MP3, and XML.
Adaptive Neural Ranking Framework: Toward Maximized Business Goal for Cascade Ranking Systems
Oct 16, 2023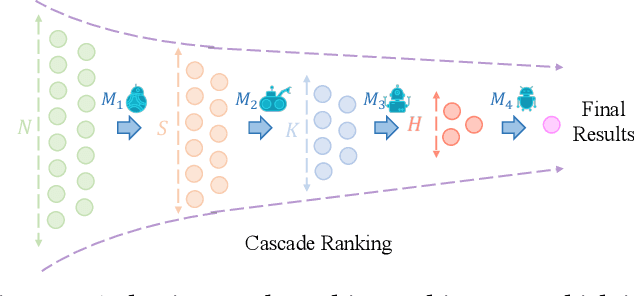

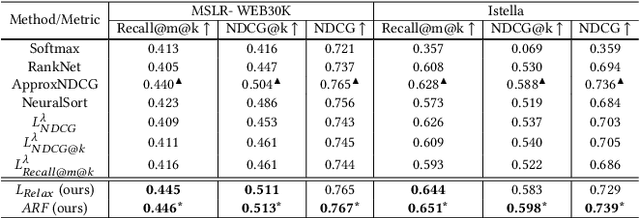
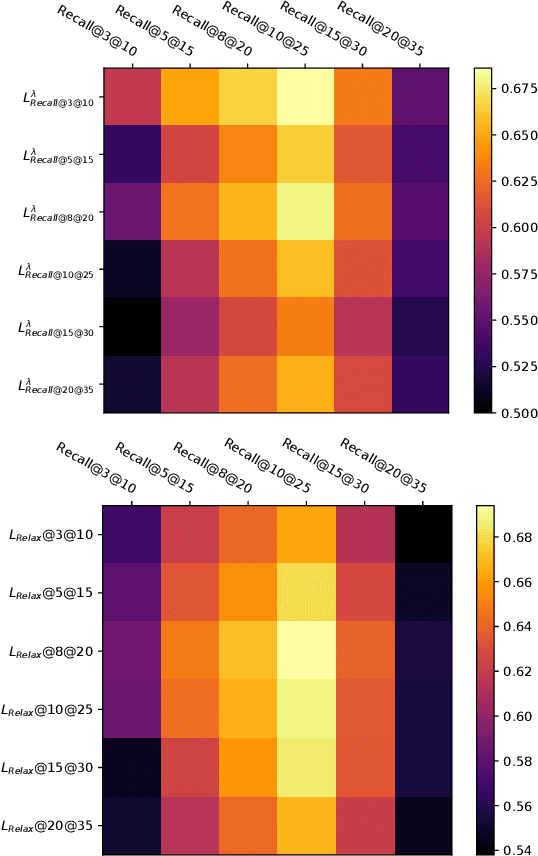
Cascade ranking is widely used for large-scale top-k selection problems in online advertising and recommendation systems, and learning-to-rank is an important way to optimize the models in cascade ranking systems. Previous works on learning-to-rank usually focus on letting the model learn the complete order or pay more attention to the order of top materials, and adopt the corresponding rank metrics as optimization targets. However, these optimization targets can not adapt to various cascade ranking scenarios with varying data complexities and model capabilities; and the existing metric-driven methods such as the Lambda framework can only optimize a rough upper bound of the metric, potentially resulting in performance misalignment. To address these issues, we first propose a novel perspective on optimizing cascade ranking systems by highlighting the adaptability of optimization targets to data complexities and model capabilities. Concretely, we employ multi-task learning framework to adaptively combine the optimization of relaxed and full targets, which refers to metrics Recall@m@k and OAP respectively. Then we introduce a permutation matrix to represent the rank metrics and employ differentiable sorting techniques to obtain a relaxed permutation matrix with controllable approximate error bound. This enables us to optimize both the relaxed and full targets directly and more appropriately using the proposed surrogate losses within the deep learning framework. We named this method as Adaptive Neural Ranking Framework. We use the NeuralSort method to obtain the relaxed permutation matrix and draw on the uncertainty weight method in multi-task learning to optimize the proposed losses jointly. Experiments on a total of 4 public and industrial benchmarks show the effectiveness and generalization of our method, and online experiment shows that our method has significant application value.
MBCT: Tree-Based Feature-Aware Binning for Individual Uncertainty Calibration
Feb 09, 2022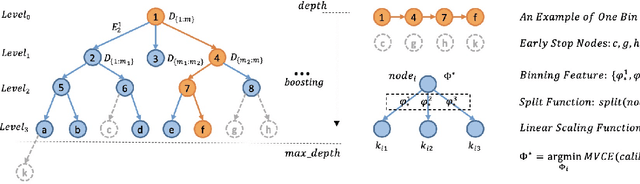
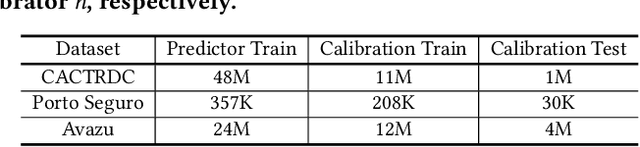
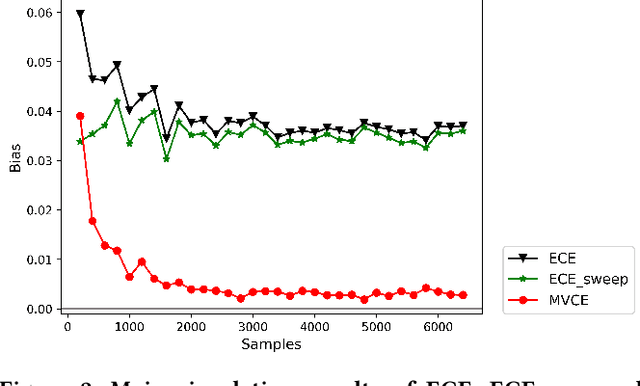
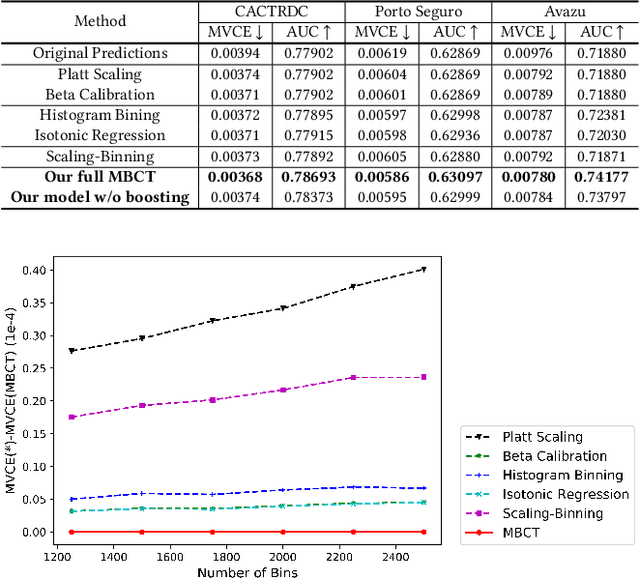
Most machine learning classifiers only concern classification accuracy, while certain applications (such as medical diagnosis, meteorological forecasting, and computation advertising) require the model to predict the true probability, known as a calibrated estimate. In previous work, researchers have developed several calibration methods to post-process the outputs of a predictor to obtain calibrated values, such as binning and scaling methods. Compared with scaling, binning methods are shown to have distribution-free theoretical guarantees, which motivates us to prefer binning methods for calibration. However, we notice that existing binning methods have several drawbacks: (a) the binning scheme only considers the original prediction values, thus limiting the calibration performance; and (b) the binning approach is non-individual, mapping multiple samples in a bin to the same value, and thus is not suitable for order-sensitive applications. In this paper, we propose a feature-aware binning framework, called Multiple Boosting Calibration Trees (MBCT), along with a multi-view calibration loss to tackle the above issues. Our MBCT optimizes the binning scheme by the tree structures of features, and adopts a linear function in a tree node to achieve individual calibration. Our MBCT is non-monotonic, and has the potential to improve order accuracy, due to its learnable binning scheme and the individual calibration. We conduct comprehensive experiments on three datasets in different fields. Results show that our method outperforms all competing models in terms of both calibration error and order accuracy. We also conduct simulation experiments, justifying that the proposed multi-view calibration loss is a better metric in modeling calibration error.
Computation Resource Allocation Solution in Recommender Systems
Mar 03, 2021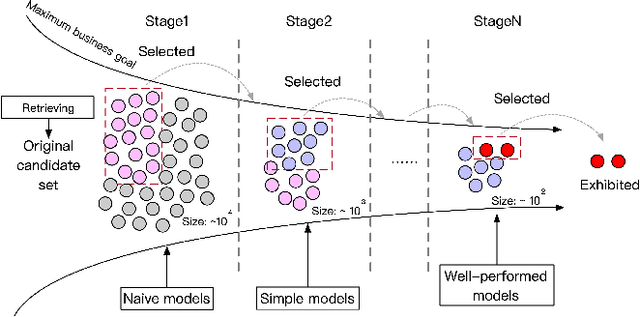

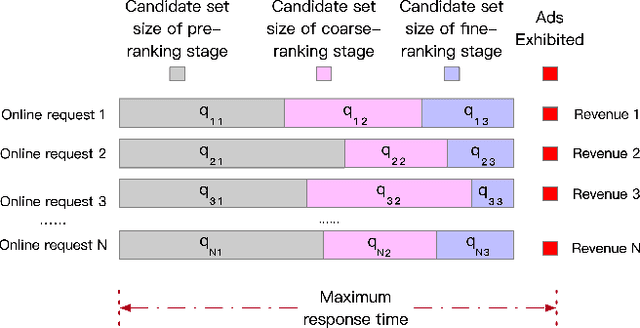
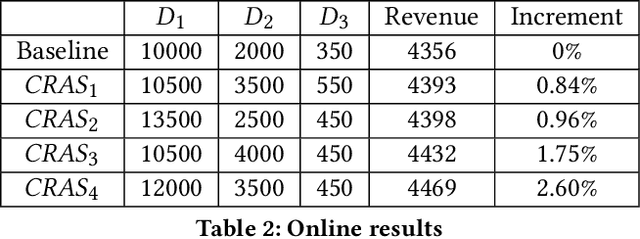
Recommender systems rely heavily on increasing computation resources to improve their business goal. By deploying computation-intensive models and algorithms, these systems are able to inference user interests and exhibit certain ads or commodities from the candidate set to maximize their business goals. However, such systems are facing two challenges in achieving their goals. On the one hand, facing massive online requests, computation-intensive models and algorithms are pushing their computation resources to the limit. On the other hand, the response time of these systems is strictly limited to a short period, e.g. 300 milliseconds in our real system, which is also being exhausted by the increasingly complex models and algorithms. In this paper, we propose the computation resource allocation solution (CRAS) that maximizes the business goal with limited computation resources and response time. We comprehensively illustrate the problem and formulate such a problem as an optimization problem with multiple constraints, which could be broken down into independent sub-problems. To solve the sub-problems, we propose the revenue function to facilitate the theoretical analysis, and obtain the optimal computation resource allocation strategy. To address the applicability issues, we devise the feedback control system to help our strategy constantly adapt to the changing online environment. The effectiveness of our method is verified by extensive experiments based on the real dataset from Taobao.com. We also deploy our method in the display advertising system of Alibaba. The online results show that our computation resource allocation solution achieves significant business goal improvement without any increment of computation cost, which demonstrates the efficacy of our method in real industrial practice.