 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraint-Aware Generative Re-ranking for Multi-Objective Optimization in Advertising Feeds
Mar 04, 2026Optimizing reranking in advertising feeds is a constrained combinatorial problem, requiring simultaneous maximization of platform revenue and preservation of user experience. Recent generative ranking methods enable listwise optimization via autoregressive decoding, but their deployment is hindered by high inference latency and limited constraint handling. We propose a constraint-aware generative reranking framework that transforms constrained optimization into bounded neural decoding. Unlike prior approaches that separate generator and evaluator models, our framework unifies sequence generation and reward estimation into a single network. We further introduce constraint-aware reward pruning, integrating constraint satisfaction directly into decoding to efficiently generate optimal sequences. Experiments on large-scale industrial feeds and online A/B tests show that our method improves revenue and user engagement while meeting strict latency requirements, providing an efficient neural solution for constrained listwise optimization.
Compress, Cross and Scale: Multi-Level Compression Cross Networks for Efficient Scaling in Recommender Systems
Feb 12, 2026Modeling high-order feature interactions efficiently is a central challenge in click-through rate and conversion rate prediction. Modern industrial recommender systems are predominantly built upon deep learning recommendation models, where the interaction backbone plays a critical role in determining both predictive performance and system efficiency. However, existing interaction modules often struggle to simultaneously achieve strong interaction capacity, high computational efficiency, and good scalability, resulting in limited ROI when models are scaled under strict production constraints. In this work, we propose MLCC, a structured feature interaction architecture that organizes feature crosses through hierarchical compression and dynamic composition, which can efficiently capture high-order feature dependencies while maintaining favorable computational complexity. We further introduce MC-MLCC, a Multi-Channel extension that decomposes feature interactions into parallel subspaces, enabling efficient horizontal scaling with improved representation capacity and significantly reduced parameter growth. Extensive experiments on three public benchmarks and a large-scale industrial dataset show that our proposed models consistently outperform strong DLRM-style baselines by up to 0.52 AUC, while reducing model parameters and FLOPs by up to 26$\times$ under comparable performance. Comprehensive scaling analyses demonstrate stable and predictable scaling behavior across embedding dimension, head number, and channel count, with channel-based scaling achieving substantially better efficiency than conventional embedding inflation. Finally, online A/B testing on a real-world advertising platform validates the practical effectiveness of our approach, which has been widely adopted in Bilibili advertising system under strict latency and resource constraints.
SPICE: Submodular Penalized Information-Conflict Selection for Efficient Large Language Model Training
Jan 30, 2026Information-based data selection for instruction tuning is compelling: maximizing the log-determinant of the Fisher information yields a monotone submodular objective, enabling greedy algorithms to achieve a $(1-1/e)$ approximation under a cardinality budget. In practice, however, we identify alleviating gradient conflicts, misalignment between per-sample gradients, is a key factor that slows down the decay of marginal log-determinant information gains, thereby preventing significant loss of information. We formalize this via an $\varepsilon$-decomposition that quantifies the deviation from ideal submodularity as a function of conflict statistics, yielding data-dependent approximation factors that tighten as conflicts diminish. Guided by this analysis, we propose SPICE, a conflict-aware selector that maximizes information while penalizing misalignment, and that supports early stopping and proxy models for efficiency. Empirically, SPICE selects subsets with higher log-determinant information than original criteria, and these informational gains translate into performance improvements: across 8 benchmarks with LLaMA2-7B and Qwen2-7B, SPICE uses only 10% of the data, yet matches or exceeds 6 methods including full-data tuning. This achieves performance improvements with substantially lower training cost.
Multi-Epoch learning with Data Augmentation for Deep Click-Through Rate Prediction
Jun 27, 2024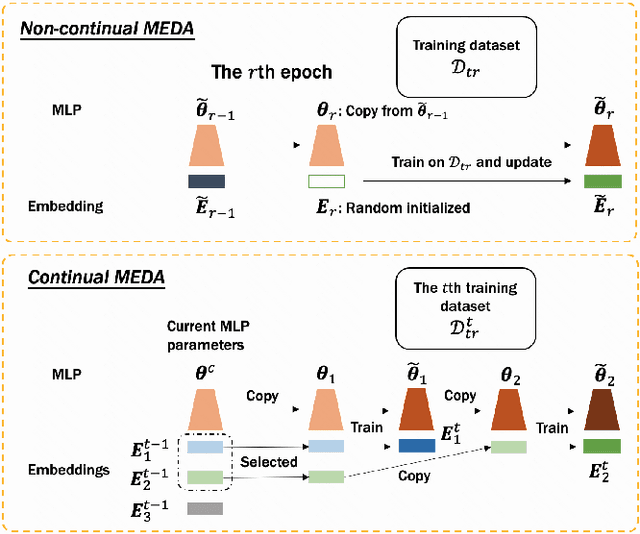
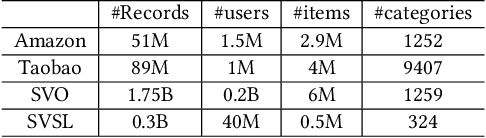
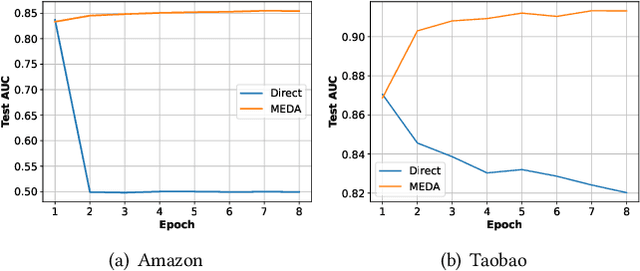
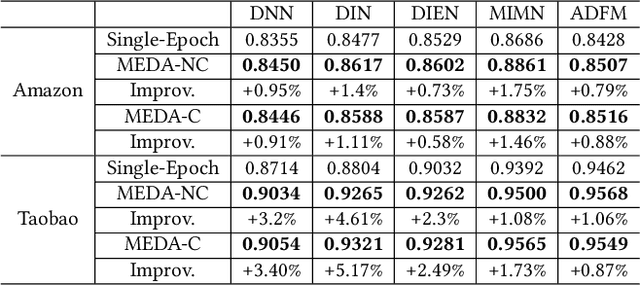
This paper investigates the one-epoch overfitting phenomenon in Click-Through Rate (CTR) models, where performance notably declines at the start of the second epoch. Despite extensive research, the efficacy of multi-epoch training over the conventional one-epoch approach remains unclear. We identify the overfitting of the embedding layer, caused by high-dimensional data sparsity, as the primary issue. To address this, we introduce a novel and simple Multi-Epoch learning with Data Augmentation (MEDA) framework, suitable for both non-continual and continual learning scenarios, which can be seamlessly integrated into existing deep CTR models and may have potential applications to handle the "forgetting or overfitting" dilemma in the retraining and the well-known catastrophic forgetting problems. MEDA minimizes overfitting by reducing the dependency of the embedding layer on subsequent training data or the Multi-Layer Perceptron (MLP) layers, and achieves data augmentation through training the MLP with varied embedding spaces. Our findings confirm that pre-trained MLP layers can adapt to new embedding spaces, enhancing performance without overfitting. This adaptability underscores the MLP layers' role in learning a matching function focused on the relative relationships among embeddings rather than their absolute positions. To our knowledge, MEDA represents the first multi-epoch training strategy tailored for deep CTR prediction models. We conduct extensive experiments on several public and business datasets, and the effectiveness of data augmentation and superiority over conventional single-epoch training are fully demonstrated. Besides, MEDA has exhibited significant benefits in a real-world online advertising system.
Adaptive Neural Ranking Framework: Toward Maximized Business Goal for Cascade Ranking Systems
Oct 16, 2023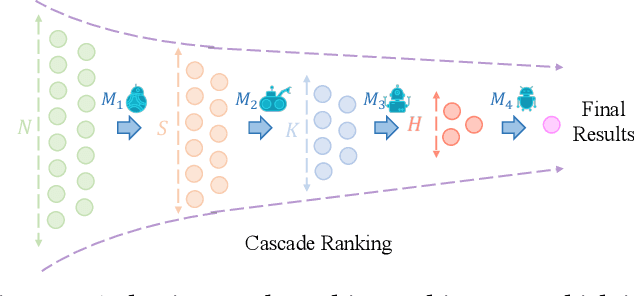

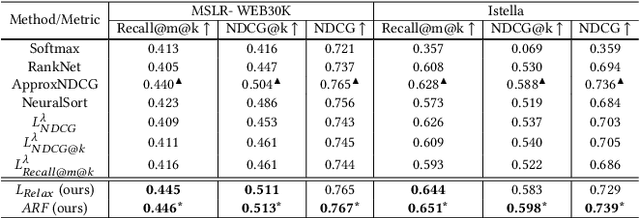
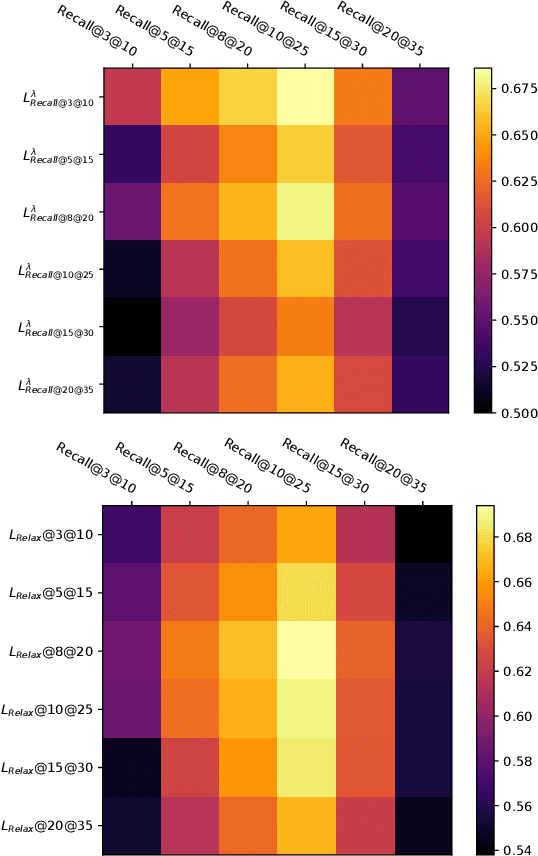
Cascade ranking is widely used for large-scale top-k selection problems in online advertising and recommendation systems, and learning-to-rank is an important way to optimize the models in cascade ranking systems. Previous works on learning-to-rank usually focus on letting the model learn the complete order or pay more attention to the order of top materials, and adopt the corresponding rank metrics as optimization targets. However, these optimization targets can not adapt to various cascade ranking scenarios with varying data complexities and model capabilities; and the existing metric-driven methods such as the Lambda framework can only optimize a rough upper bound of the metric, potentially resulting in performance misalignment. To address these issues, we first propose a novel perspective on optimizing cascade ranking systems by highlighting the adaptability of optimization targets to data complexities and model capabilities. Concretely, we employ multi-task learning framework to adaptively combine the optimization of relaxed and full targets, which refers to metrics Recall@m@k and OAP respectively. Then we introduce a permutation matrix to represent the rank metrics and employ differentiable sorting techniques to obtain a relaxed permutation matrix with controllable approximate error bound. This enables us to optimize both the relaxed and full targets directly and more appropriately using the proposed surrogate losses within the deep learning framework. We named this method as Adaptive Neural Ranking Framework. We use the NeuralSort method to obtain the relaxed permutation matrix and draw on the uncertainty weight method in multi-task learning to optimize the proposed losses jointly. Experiments on a total of 4 public and industrial benchmarks show the effectiveness and generalization of our method, and online experiment shows that our method has significant application value.
Multi-Epoch Learning for Deep Click-Through Rate Prediction Models
May 31, 2023The one-epoch overfitting phenomenon has been widely observed in industrial Click-Through Rate (CTR) applications, where the model performance experiences a significant degradation at the beginning of the second epoch. Recent advances try to understand the underlying factors behind this phenomenon through extensive experiments. However, it is still unknown whether a multi-epoch training paradigm could achieve better results, as the best performance is usually achieved by one-epoch training. In this paper, we hypothesize that the emergence of this phenomenon may be attributed to the susceptibility of the embedding layer to overfitting, which can stem from the high-dimensional sparsity of data. To maintain feature sparsity while simultaneously avoiding overfitting of embeddings, we propose a novel Multi-Epoch learning with Data Augmentation (MEDA), which can be directly applied to most deep CTR models. MEDA achieves data augmentation by reinitializing the embedding layer in each epoch, thereby avoiding embedding overfitting and simultaneously improving convergence. To our best knowledge, MEDA is the first multi-epoch training paradigm designed for deep CTR prediction models. We conduct extensive experiments on several public datasets, and the effectiveness of our proposed MEDA is fully verified. Notably, the results show that MEDA can significantly outperform the conventional one-epoch training. Besides, MEDA has exhibited significant benefits in a real-world scene on Kuaishou.
Improving Multi-Interest Network with Stable Learning
Jul 14, 2022
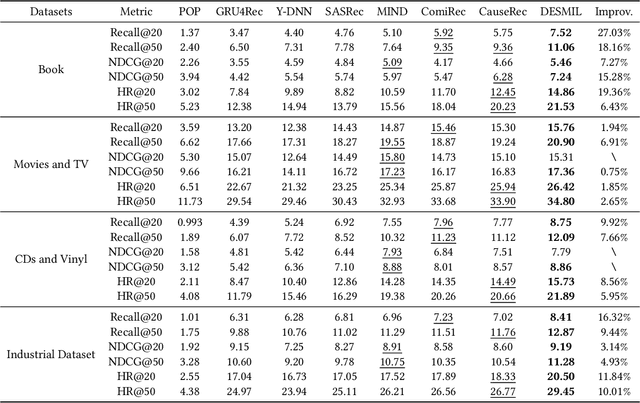
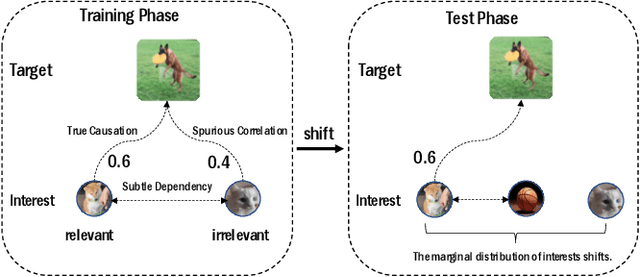

Modeling users' dynamic preferences from historical behaviors lies at the core of modern recommender systems. Due to the diverse nature of user interests, recent advances propose the multi-interest networks to encode historical behaviors into multiple interest vectors. In real scenarios, the corresponding items of captured interests are usually retrieved together to get exposure and collected into training data, which produces dependencies among interests. Unfortunately, multi-interest networks may incorrectly concentrate on subtle dependencies among captured interests. Misled by these dependencies, the spurious correlations between irrelevant interests and targets are captured, resulting in the instability of prediction results when training and test distributions do not match. In this paper, we introduce the widely used Hilbert-Schmidt Independence Criterion (HSIC) to measure the degree of independence among captured interests and empirically show that the continuous increase of HSIC may harm model performance. Based on this, we propose a novel multi-interest network, named DEep Stable Multi-Interest Learning (DESMIL), which tries to eliminate the influence of subtle dependencies among captured interests via learning weights for training samples and make model concentrate more on underlying true causation. We conduct extensive experiments on public recommendation datasets, a large-scale industrial dataset and the synthetic datasets which simulate the out-of-distribution data. Experimental results demonstrate that our proposed DESMIL outperforms state-of-the-art models by a significant margin. Besides, we also conduct comprehensive model analysis to reveal the reason why DESMIL works to a certain extent.
LPFS: Learnable Polarizing Feature Selection for Click-Through Rate Prediction
Jun 01, 2022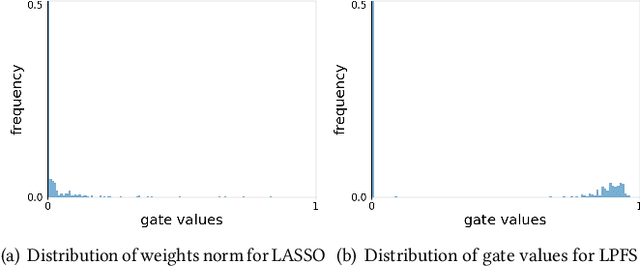
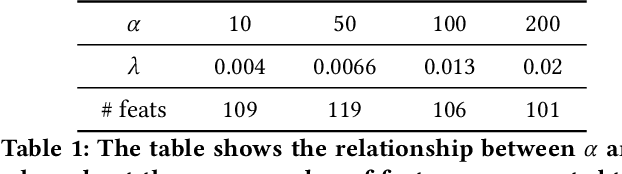
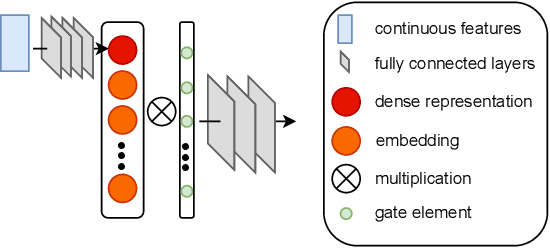

In industry, feature selection is a standard but necessary step to search for an optimal set of informative feature fields for efficient and effective training of deep Click-Through Rate (CTR) models. Most previous works measure the importance of feature fields by using their corresponding continuous weights from the model, then remove the feature fields with small weight values. However, removing many features that correspond to small but not exact zero weights will inevitably hurt model performance and not be friendly to hot-start model training. There is also no theoretical guarantee that the magnitude of weights can represent the importance, thus possibly leading to sub-optimal results if using these methods. To tackle this problem, we propose a novel Learnable Polarizing Feature Selection (LPFS) method using a smoothed-$\ell^0$ function in literature. Furthermore, we extend LPFS to LPFS++ by our newly designed smoothed-$\ell^0$-liked function to select a more informative subset of features. LPFS and LPFS++ can be used as gates inserted at the input of the deep network to control the active and inactive state of each feature. When training is finished, some gates are exact zero, while others are around one, which is particularly favored by the practical hot-start training in the industry, due to no damage to the model performance before and after removing the features corresponding to exact-zero gates. Experiments show that our methods outperform others by a clear margin, and have achieved great A/B test results in KuaiShou Technology.
Persia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021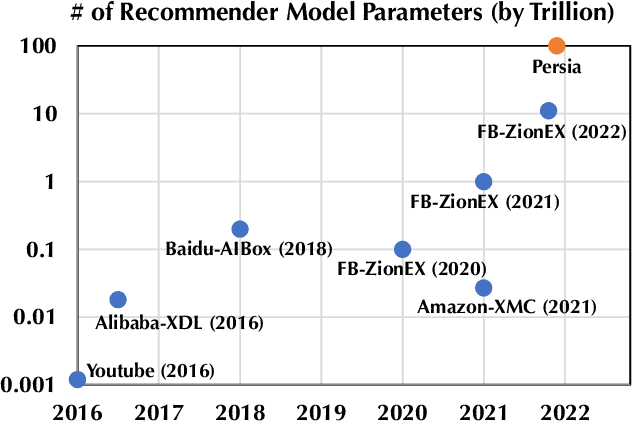
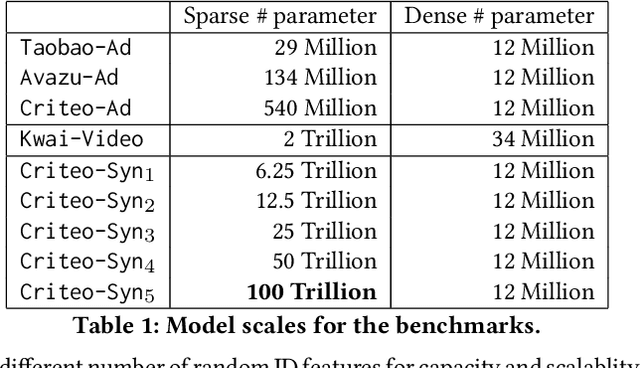
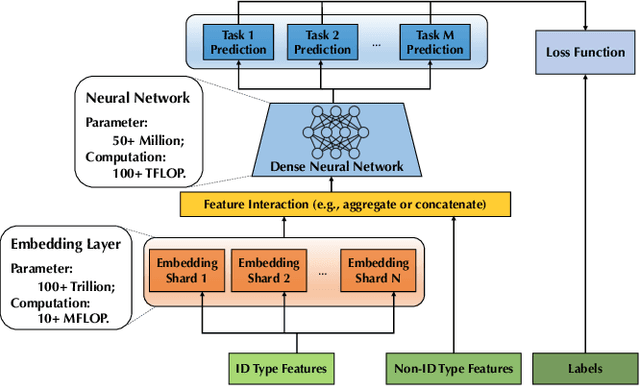
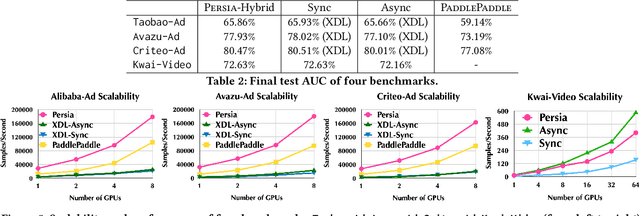
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.
PASTO: Strategic Parameter Optimization in Recommendation Systems -- Probabilistic is Better than Deterministic
Aug 20, 2021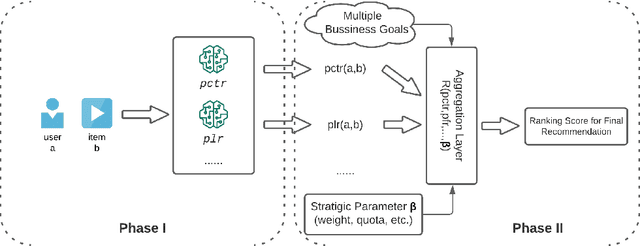
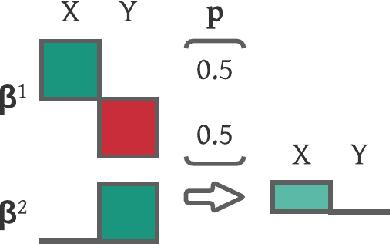

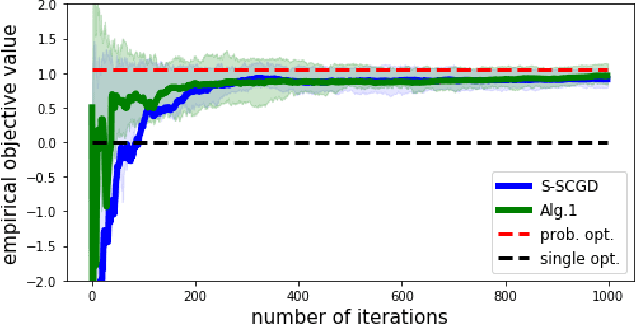
Real-world recommendation systems often consist of two phases. In the first phase, multiple predictive models produce the probability of different immediate user actions. In the second phase, these predictions are aggregated according to a set of 'strategic parameters' to meet a diverse set of business goals, such as longer user engagement, higher revenue potential, or more community/network interactions. In addition to building accurate predictive models, it is also crucial to optimize this set of 'strategic parameters' so that primary goals are optimized while secondary guardrails are not hurt. In this setting with multiple and constrained goals, this paper discovers that a probabilistic strategic parameter regime can achieve better value compared to the standard regime of finding a single deterministic parameter. The new probabilistic regime is to learn the best distribution over strategic parameter choices and sample one strategic parameter from the distribution when each user visits the platform. To pursue the optimal probabilistic solution, we formulate the problem into a stochastic compositional optimization problem, in which the unbiased stochastic gradient is unavailable. Our approach is applied in a popular social network platform with hundreds of millions of daily users and achieves +0.22% lift of user engagement in a recommendation task and +1.7% lift in revenue in an advertising optimization scenario comparing to using the best deterministic parameter strategy.